Download

1 / 37
370 likes | 653 Views
Structured P2P Network. Group14: Qiwei Zhang; Shi Yan; Dawei Ouyang ; Boyu Sun. What is P2P Network?. Peer-to-peer (abbreviated to P2P ) E ach computer in the network can act as a client or server for the other computers in the network.

E N D
Structured P2P Network Group14: Qiwei Zhang; Shi Yan; DaweiOuyang; Boyu Sun
What is P2P Network? • Peer-to-peer (abbreviated to P2P) • Each computer in the network can act as a client or server for the other computers in the network. • Allow shared access to files and peripherals without the need for a central server
Centralized: Nodes in the P2P network issue queries to the central directory server to find which other nodes hold the desired files.
Decentralized and Unstructured: 1. To find a file, a node queries its neighbors. 2. The most typical query method is flooding • Decentralized but Structured: 1. the P2P overlay topology is tightly controlled 2. files are placed not at random nodes but at specified locations.
We focus on the following 3 critical problems in Structured P2P network: • Load Balancing Problem • P2P look-up protocol: Chord • Content-Addressable (CAN) Network
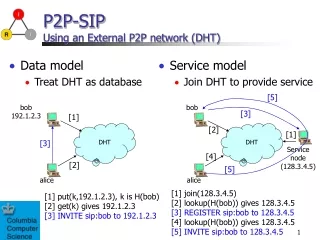
Structured P2P System ●UseGlobally Consistent Protocols Peers or resources are organized following specific criteria and algorithms. Ensure efficiency for routing search desired files ●Distributed Hash Table(DHT) A class of decentralized distributed systems that provide a lookup service similar to hash table A variant of consistent hashing is used to assign ownership of each file to a particular peer
Distributed Hash Table in P2P ●(key, value) pairs are stored in the DHT ● Any participating node can efficiently retrieve the value associated with a given key ● A change in the set of participants causes a minimal amount of disruption ● Can scale to extremely large numbers of nodes handle continual node arrivals, departures, and failures.
Load balancing in dynamic structured P2P networks P2P networks may face following problems in real world • data items are continuously inserted and deleted, • nodes join and depart the system continuously, • the distribution of data item IDs and item sizes can be skewed. Efficient load balancing is needed Load: e.g. number of bits required for an object; popularity of the object Move cost : usually proportional to object size. A load balancing algorithm should be able to achieve: • Minimize the load imbalance • Minimize the amount of load moved
Virtual Server in P2P • A virtual server represents a peer in the DHT The storage of data items and routing happen at the virtual server level rather than at the physical node level. • A physical node hosts one or more virtual servers. • Load balancing is achieved by moving virtual servers From heavily loaded physical nodes to lightly loaded physical nodes.
Several Typical Schemes • one-to-one each lightly loaded node v periodically contacts a random node w. If w is heavily loaded, virtual servers are transferred from w to v such that w becomes light without making v heavy • one-to-many allows a heavy node to consider more than one light node at a time. • many-to-many each directory maintains load information for a set of both light and heavy nodes The new scheme is based on one-to-many and many-to-many
Potential Improvements • Prediction of change in load. • Balance of multiple resources. • Beneficial effect of heterogeneous capacities.
Chord-A Scalable Peer-to-Peer Lookup Protocol for Internet Applications Ion Stoica, Robert Morris, David Liben-Nowell, David R. Karger, M. Frans Kaashoek, Frank Dabek, and Hari Balakrishnan, Member, IEEE
Motivation: A fundamental problem that confronts peer-to-peer applications is the efficient location of the nodes that stores a desired data item. Chord deal with this problem by operation: given a key, it maps the key onto a node.
A node's identifier is chosen by hashing its IP address • The key's identifier is produced by hashing the key
Chord Protocol 1. Consistent hashing 2. Lookup Algorithm • Simple key location algorithm • scalable key location algorithm
Where to store K10? Is there N10? No Then find the first node follows N10 N14 !
Lookup Algorithm-Scalable Key blind point
Dynamic operations and failures • Chord needs to deal with nodes joining the system or leaving dynamically.
Conclusion • Chord simplifies the design of peer-to-peer systems and applications based on it by addressing these difficult problems: • Load balance: Chord acts as distributed hash function, spreading keys evenly over the nodes.(proved in paper). This provides a degree of natural load balance. • Decentralization: Chord is fully distributed; no node is more important than any other. It belongs to the "Decentralized and structured" category. "structure" means files are placed not at random nodes but at specified locations that will make subsequent queries easier. We will see the structure of Chord later. • Scalability: The cost of a Chord lookup grows as the log of the number of nodes O(log n). • (each Chord node needs routing information about only a few other nodes while previous work assumes that each node is aware of most of other nodes in the system so that very large system is not feasible.) • Availability: Chord automatically adjusts its internal tables to reflect newly jointed nodes and failed nodes.
Definition: Content-Addressable Network, AKA, CAN, is a distributed, decentralized P2P infrastrucuture that provide hash table functionality on Internet-scale It was one of the original four distributed hash tables introduced concurrently. (Chord, Pastry and Tapestry)
Features: scalability, robustness and low latency. Usage: P2P file-sharing systems, large scale storage management systems, wide-area name resolution services.
Design: Operations performed on CAN are similar to a hash table: insertion, lookup and deletion the (key, value) pairs. Each node stores a zone (a chunk of the entire hash table), and contains a coordinate routing table that holds the IP address and virtual coordinate zone of its immediate neighbors in the coordinate space.
Construction of CAN: When a new node wants to join the CAN, it must first find a node already in the CAN. Then using the CAN routing mechanisms, it must find a node whose zone will be split. Finally, the neighbors of the split zone must be notified so that routing can include the new node.
CAN recovery and maintenance: When a node leave CAN, the zone it occupied has to be taken over by other nodes. Normally, the node will explicitly hand over its zone and the associated(key, value) database to one of its neighbors. However, if it is the network failure that disables the node immediately, the (key, value) pairs held by the disabled node are lost until the state is refreshed by the holder of the data
Design improvements: Multi-dimensioned coordinate spaces Reality: multiple coordinate spaces Better routing metrics: RTT-weighted routing Overloading coordinate zones Multiple hash functions Topologically-sensitive construction
Multi-dimensioned coordinate spaces Increasing the dimensions of the CAN coordinate space reduces the routing path length, and hence the path latency, only a small increase in the size of the coordinate routing table • Reality is multiple independent coordinate Spaces with each node in the system being assigned a different zone in each coordinate space. The contents of the hash table are replicated on every reality, this replication provides better availability of the data and also provide fault tolerance.
Better routing metrics: RTT-weighted routing This method aims at reducing the latency of individual hops along the path rather than the path length. • Overloading coordinate zones A node maintains a list of its peers in addition to its neighbor list. This mechanism reduces path length, reduces per-hop latency and improve fault tolerance
Multiple hash functions Used to improve data availability by redundancy. • Topologically-sensitive construction Basic design which does not include this can lead to seemingly strange routing scenarios where two geographically adjacent nodes may communicate through some node far away. So topologically sensitive construction of the overlay network avoid this.