Download

1 / 63
630 likes | 914 Views
Achieving Semantic Interoperability – Architectures and Methods. Denise A. D. Bedford Senior Information Officer World Bank. Semantic Interoperability (SI). Semantic interoperability means different things to different people primarily because the context is always different Semantics –

E N D
Achieving Semantic Interoperability – Architectures and Methods Denise A. D. Bedford Senior Information Officer World Bank
Semantic Interoperability (SI) • Semantic interoperability means different things to different people primarily because the context is always different • Semantics – • Resolved at the understanding and reasoning level • Word level, Concept level, Language level, Grammatical level, Domain Vocabulary level, Representation level • Interoperability • Resolved at the architecture level • Different sources using different semantics
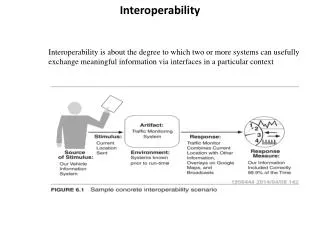
What Does SI Look Like? • Answer to this question is always, “It depends…” • Achieving semantic interoperability means that the semantic and the interoperability challenges are resolved at the system level – not at the user level • Practical examples • Cross application discovery • Cross language discovery • Recommender engines • Workflow management • Scenario inferencing • Let’s look at a high level model of the enterprise search model and find the SI points
Vision of Semantic Interoperability Site Specific Searching Publications Catalog World Bank Catalog/ Enterprise Search (Oracle Intermedia) Recommender Engines Personal Profiles Portal Content Syndication Browse & Navigation Structures Metadata Repository Of Bank Standard Metadata (Oracle Tables & Indexes) Reference Tables (CDS+) Topics, Countries Document Types (Oracle data classes) Data Governance Bodies Transformation Rules/Maps Metadata Extract Metadata Extract Metadata Extract Metadata Extract Metadata Extract Metadata Extract Metadata Extract TRIM Archives Web Content Mgmt. Metadata SAP Financial System People Soft SIRSI System InfoShop Metadata IRIS Oracle Concept Extraction, Categorization & Summarization Technologies
Basic Assumptions and Constraints • There are many layers of semantic challenges between the user experience and architecture • Ideally, semantic interoperability is grounded in your enterprise architecture – regardless of the level of sophistication of your enterprise architecture • Semantic interoperability is a question of degree - some of the layers are interoperable at the enterprise level and others may be at a local level • Some layers may be universal – beyond the enterprise – and others are by definition limited to the enterprise
Managing Interoperability Challenges • Option 1: Integrate, map and reconcile at a superficial level • Reference mappings • Continuous monitoring – always after the fact • Consultation and reconciliation and fixing • SI solution is always a partial solution • Option 2: Provide the capability to generate semantically interoperable solutions early in the development stages • Use the technologies to model what people would do if they had unlimited time and resources • Develop consistent profiles which distributed throughout an enterprise, but managed centrally • Govern and manage the profiles, not the ‘mess’
Combining Options • Option 1 is feeding the beast – you never get ahead and it consumes resources you could use for other products and services • My experience is that we have to use both options • Mapping and managing the legacy data unless you can recon • Trying to push a programmatic solution for new content • At least trying to stop the reconciliation at a given point in time • I’d like to talk first about the idea behind the architecture and second, about the actual semantic methods
Teragram Tools • Teragram is a company located in Boston and Paris which offers COTS natural language processing(NLP) technologies • Teragram’s Natural Language Processing technologies include: • Rules Based Concept Extraction (also called classifier) • Grammar Based Concept Extraction • Categorization • Summarization • Clustering • Language detection • Semantic engines are available in 30+ languages
Teragram Use • Operationalized in the System • IRIS – Retrospective Processing • ImageBank – daily processing of incoming documents • Structured service descriptions – terse text • Self-Service Model • WBI Library of Learning • Africa Region Operations Toolkit • External Affairs – eLibrary • External Affairs – Media Monitoring • External Affairs – Disease Control Priorities Website • ICSID -- Document Management • PICs MARC Record attributes • Web Archives metadata
Structured & Unstructured Data • Range of formats processed • Anything in electronic format – MS Office, html, xml, pdf, … • Range of types of text processed • 17M pdf documents • Very short structured service descriptions • Different writing styles • Formal publications, internal informal emails, web pages, data reports • Depending on what you are trying to do with the data – may or may not have to adjust the profile and your strategy • Most important consideration, though, is the nature of the writing style – informal requires some adjustments
Business Drivers • In order to get ahead of the problem, we decided to: • ‘Institutionalize’ the Teragram profiles so that outputs are consistently generated across applications and content • Have a single installation of the technologies to ensure consistent management and efficient maintenance • Allow different systems to call and consume the outputs from the technologies while using the same profiles • Avoid tight integration of the Teragram technologies with any existing system
Teragram Components & Configuration Concept Profile Concept Engine Categorization Profile Language Grammars Categorization Engine Concept List for Clustering Authority Lists Taxonomies Summarization Engine Summarization Rules File Master Data Stores Controlled Vocabularies Clustering Engine TK240 Client Testing Sets Training Sets XML formatted output Enterprise Profile Development & Maintenance IQ Teragram Team
Content Owners Content Owners Dedicated Server – Teragram Semantic Engine – Concept Extraction, Categorization, Clustering, Rule Based Engine, Language Detection APIs & Integration APIs & Integration ISP Integration IRIS Functional Team IRIS Integration Business Analyst Enterprise Metadata Capture Strategy TK240 Client XML Output Content Capture Content Capture XML Wrapped Metadata XML Wrapped Metadata APIs & Integration APIs & Technical Integration Enterprise Profile Development & Maintenance Factiva Metadata Database ImageBank Integration e-CDS Reference Sources IDU Indexers SITRC Librarians Enterprise Metadata Capture – Functional Reference Model
Information Architecture Best Practices • Build profiles at the attribute level so that everyone can use the same profile and there is only one profile to maintain • Each calling system, though, can specify the attributes that they want to use in their processing • ImageBank can specify Topics and Keywords • WBI can specify Topics, Keywords, Country, Regions • Media Monitoring can specify Topics, Organization Names, People Names • eLibrary can specify Author, Title, Publisher, Publication Date, Topics, Library of Congress Class No. • Each of these users is calling the same Topic profile even though their overall profiles are different
Enterprise Profile Creation and Maintenance • Enterprise Metadata Profile Concept Extraction Technology • Country • Organization Name • People Name • Series Name/Collection Title • Author/Creator • Title • Publisher • Standard Statistical Variable • Version/Edition Categorization Technology • Topic Categorization • Business Function Categorization • Region Categorization • Sector Categorization • Theme Categorization Rule-Based Capture • Project ID • Trust Fund # • Loan # • Credit # • Series # • Publication Date • Language Summarization UCM Service Requests Update & Change Requests Data Governance Process for Topics, Business Function, Country, Region, Keywords, People, Organizations, Project ID e-CDS Reference Sources for Country, Region, Topics Business Function, Keywords, Project ID, People, Organization Enterprise Profile Development & Maintenance JOLIS E-Journals Factiva ISP TK240 Client IRIS ImageBank Teragram Team
Context • I will use today a simple application to illustrate the problems and the solutions • Context is programmatic capture of high quality, consistent, persistent, rich metadata to support parametric enterprise search • Parametric enterprise search looks simple but there are a lot of underlying semantic problems • Implementation has expanded beyond core metadata at this point in time and continues to grow but that’s another discussion – also expanding into other languages
World Bank Core Metadata Identification/ Distinction Search & Browse Compliant Document Management Use Management Human Creation Programmatic Capture Extrapolate from Business Rules Inherit from System Context
Semantic Methods • Each of these parameters presents a different kind of semantic challenge • Need to find the right semantic solution to fit the semantic problem • Semantic methods should always mirror how a human approaches, deconstructs and solves the semantic challenge • Purely statistical approaches to solving semantic problems are only appropriate where a human being would take a statistical approach • Mistake we have made in the profession is to assume that statistical methods can solve semantic problems – they cannot
NLP Technologies – Two Approaches • Over the past 50 years, there have been two competing strategies in NLP - statistical vs. semantic • In the mid-1990’s at the AAAI Stanford Spring Workshops it was agreed by the active practitioners that the statistical NLP approach had hit a rubber ceiling – there were no further productivity gains to be made from this approach • About that time, the semantic approach showed practical gains – we have been combining the two approaches since the late 1990’s • Most of the tools on the market today are statistical NLP, but some have a more robust underlying semantic engine
Problem with Statistical NLP • We experimented with several of these tools in the early 2000s – including Autonomy, Semio, Northern Lights Clustering – but there were problems • the statistical associations you generate are entirely dependent upon the frequency at which they occur in the training set • Without a semantic base you cannot distinguish types of entities, attributes, concepts or relationships • If the training set is not representative of your universe, your relationships will not be representative and you cannot generalize from the results • If the universe crosses domains, then the data that have the greatest commonality (least meaning) have the greatest association value
Semantic NLP • For years, people thought the semantic could not be achieved so they relied on statistical methods • The reason they thought it would never be practical is that it took a long time to build the foundation – understanding human language is not a trivial exercise • Building a semantic foundation involves: • developing grammatical and morphological rules – language by language • Using parsers and Part of Speech (POS) taggers to semantically decompose text into semantic elements • Building dictionaries or corpa for individual languages as fuel for the semantic foundation to run on • Making it all work fast enough and in a resource efficient way to make it economically practical
Problem with Statistical Tools • There are problems with the way the statistical tools are packed in tools… • Resource intense to run – to cluster 100 documents may take several hours and give you suboptimal results • Results are dynamic not persistent - you can’t do anything else with the results but look at them and point back to the documents • They only live in the index that was built to support the cluster and generally are not consumable by any other tools • Outputs are not persistently associated with the content • We wanted to generate persistent metadata which could then be manipulated by other tools
Implementing Teragram • The package consists of a developers client (TK240) and multiple servers to support the technologies • Client is the tool we use to build the profiles/rules – server interprets the rules • Recall the earlier model of enterprise profiles • Each attribute is supported by its own profile – there is a profile for countries, one for regions, one for topics, one for people names, and so on • We keep a ‘table’ of the profiles that any application uses – call the profiles at run time • Language profiles are separate – English, French, Spanish, …
Implementing Teragram • The first step is not applying the tool to content, but analyzing the semantic challenge • Understand how a person resolves the semantic problem - then devise a machine solution that resembles the human solution • The solution involves selecting a tool from the Teragram set, building the rules, testing and refining the rules, then rolling out as QA for end user review • End user feedback and signoff is important – helps build confidence and improves the quality of the result • Depending on the complexity of the problem and whether the rules require a reference source, putting the solution together might take a week to two months
Examples of Solutions • There are different kinds of semantic tools – you have to find the one that suits your semantic problem • Let’s look at some solution examples: • Rules Based Concept Extraction • Grammar Based Concept Extraction • Categorization • Summarization • Clustering • Language detection • As I talk about each solution, I’ll describe what we tried that didn’t work, as well as what did work in the end
Rule Based Concept Extraction • What is it? • Rule based concept or entity extraction is a simple pattern recognition technique which looks for and extracts named entities • Entities can be anything – but you have to have a comprehensive list of the names of the entities you’re looking for • How does it work? • It is a simple pattern matching program which compares the list of entity names to what it finds in content • Regular expressions are used to match sets of strings that follow a pattern but contain some variation • List of entity names can be built from scratch or using existing sources – we try to use existing sources • A rule-based concept extractor would be fueled by a list such as Working Paper Series Names, edition or version statement, Publisher’s names, etc. • Generally, concept extraction works on a “match” or “no match” approach – it matches or it doesn’t • Your list of entity names has to be pretty good
Rule Based Concept Extraction • How do we build it? • Create a comprehensive list of the names of the entities – most of the time these already exist, and there may be multiple copies • Review the list, study the patterns in the names, and prune the list • Apply regular expressions to simplify the patterns in the names • Build a Concept Profile • Run the concept profile against a test set of documents (not a training set because we build this from an authoritative list not through ‘discovery’) • Review the results and refine the profile • State of Industry • The industry is very advanced – this type of work has been under development and deployed for at least three decades now. It is a bit more reliable than grammatical extraction, but it takes more time to build.
Loan # Credit # Report # Trust Fund # ISBN, ISSN Organization Name(companies, NGOs, IGOs, governmental organizations, etc.) Address Phone Numbers Social Security Numbers Library of Congress Class Number Document Object Identifier URLs ICSID Tribunal Number Edition or version statement Series Name Publisher Name Rules Based Concept Extraction Examples Let’s look at the Teragram TK240 profiles for Organization Names, Edition Statements, and ISBN
ISBN Concept Extraction Profile – Regular Expressions (RegEx) Replace this slide with the ISBN screen – with the rules displayed Concept based rules engine allows us to define patterns to capture other kinds of data Use of concept extraction, regular expressions, and the rules engine to capture ISBNs. Regular expressions match sets of strings by pattern, so we don’t need to list every exact ISBN we’re looking for.
List of entities matches exact strings. This requires an exhaustive list– but gives us extensive control. (It would be difficult to distinguish by pattern between IGOs and other NGOs.) Classifier concept extraction allows us to look for exact string matches
Another list of entities matches exact strings. In this case, though, we’re making this into an ‘authority control list’– We’re matching multiple strings to the one approved output. (In this case, the AACR2-approved edition statement.)
Grammatical Concept Extractions • What is it? • A simple pattern matching algorithm which matches your specifications to the underlying grammatical entities • For example, you could define a grammar that describes a proper noun for people’s names or for sentence fragments that look like titles • How does it work? • This is also a pattern matching program but it uses computational linguistics knowledge of a language in order to identify the entities to extract – if you don’t have an underlying semantic engine, you can’t do this type of extraction • There is no authoritative list in this case – instead it uses parsers, part-of-speech tagging and grammatical code • The semantic engine’s dictionary determines how well the extraction works – if you don’t have a good dictionary you won’t get good results • There needs to be a distinct semantic engine for each language you’re working with
Grammatical Concept Extractions • How do we build it? • Model the type of grammatical entity we want to extract and use the grammar definitions to build a profile • Test the profile on a set of test content to see how it behaves • Refine the grammars • Deploy the profile • State of Industry • It has taken decades to get the grammars for languages well defined • There are not too many of these tools available on the market today but we are pushing to have more open source • Teragram now has grammars and semantic engines for 30 different languages commercially available • IFC has been working with ClearForest • Let’s look at some examples of grammatical profiles – People’s Names, Noun Phrases, Verb Phrases, Book Titles
TK240 Grammars for People Names Grammar concept extraction allows us to define concepts based on semantic language patterns.
Grammatical Concept Extraction Proper Noun Profile for People Names uses grammars to find and extract the names of people referenced in the document. <?xml version="1.0" encoding="UTF-8"?> <Proper_Noun_Concept> <Source><Source_Type>file</Source_Type> <Source_Name>W:/Concept Extraction/Media Monitoring Negative Training Set/ 001B950F2EE8D0B4452570B4003FF816.txt</Source_Name> </Source><Profile_Name>PEOPLE_ORG</Profile_Name> <keywords>Abdul Salam Syed, Aruna Roy, Arundhati Roy, Arvind Kesarival, Bharat Dogra, Kwazulu Natal, Madhu Bhaduri, </keywords><keyword_count>7</keyword_count> </Proper_Noun_Concept>
Grammatical Concept Extraction –People Names Client testing mode
Rule-Based Categorization • What is it? • Categorization is the process of grouping things based on characteristics • Categorization technologies classify documents into groups or collections of resources • An object is assigned to a category or schema class because it is ‘like’ the other resources in some way • Categories form part of a hierarchical structure when applied to such subjects as a taxonomy • How does it work? • Automated categorization is an ‘inferencing’ task- meaning that we have to tell the tools what makes up a category and then how to decide whether something fits that category or not • We have to teach it to think like a human being – • When I see -- access to phone lines, analog cellular systems, answer bid rate, answer seizure rate – I know this should be categorized as ‘telecommunications’ • We use domain vocabularies to create the category descriptions
Rule Based Categorization • How do we build it? • Build the hierarchy of categories • Manually if you have a scheme in place and maintained by people • Programmatically if you need to discover what the scheme should be • Build a training set of content category by category – from all kinds of content • Describe each category in terms of its ‘ontology’ – in our case this means the concepts that describe it (generally between 1,000 and 10,000 concepts) • Filter the list to discover groups of concepts • The richer the definition, the better the categorization engine works • Test each category profile on the training set • Test the category profile on a larger set that is outside the domain • Insert the categirt profile into the profile for the larger hierarchy
Rule Based Categorization • State of the Industry • Only a handful of rule-based categorizers are on the market today • Most of the existing technologies are dynamic clustering tools • However, the market will probably grow in this area as the demand grows
Categorization Examples • Let’s look at some working examples by going to the Teragram TK240 profiles • Topics • Countries • Regions • Sector • Theme • Disease Profiles • Other categorization profiles we’re also working on… • Business processes (characteristics of business processes) • Sentiment ratings (positive media statements, negative media statements, etc.) • Document types (by characteristics found in the documents) • Security classification (by characteristics found in the documents)
Topic Hierarchy From Relationships across data classes Build the rules at the lowest level of categorization
Subtopics Domain concepts or controlled vocabulary
Automatically Generated XML Metadata for Business Function attribute • Office memorandum on requesting CD’s clearance of the Board Package for NEPAL: Economic Reforms Technical Assistance (ERTA)