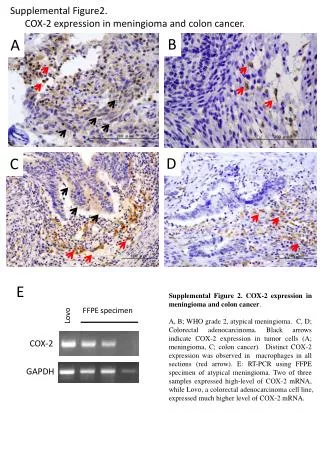
Download

1 / 26
260 likes | 427 Views
Comparing Cox Model with a Surviving Fraction with regular Cox model. Liping Huang & Yumin Zhao. Introduction:

E N D
Comparing Cox Model with a Surviving Fraction with regular Cox model Liping Huang & Yumin Zhao
Introduction: • In some clinical follow-up studies, a positive proportion of patients who respond favorably to treatment appear subsequently to be free of any signs or symptoms of the disease and may be considered “cured” . • While the remaining subjects who are susceptible to the event are referred to as “uncured” .
A typical case: A clinical study of breast cancer patients, analyzed by Farewell (1986) In this study, the time to relapse or death for three treatments was observed from 139 patients. Four covariates, clinical stage, pathological stage, histological stage and the number of lymph nodes having disease involvement were also observed for each patient. The Kaplan-Meier survival curves of patients from the three treatment groups are given in Figure 1.
All of them are above 40%. Of particular interest here is the curve for treatment B, which levels off at 73%. • At the tails of these curves a number of long-term censored observations exist, which correspond to patients who may be cured in each of 3 groups.
Objective: compare the most popular cure model, mixture model, with the regular Cox model, in which, we assume all observations are susceptible to event of interest, in other words, all observations are “uncured”. Statistical tools: SAS Splus
Notations: Let T be a nonnegative random variable denoting the time to relapse or death due to the disease. ---probability density function of T ---survival function of T where x, z are two observed covariate vectors on which the distribution of T may depend; ---probability density function of T of uncured patients ---survival function of T of uncured patients where x is a covariate vector on which T of uncured patients may depend; ---probability density function of T of cured patients ---survival function of T of cured patients. Because cured patients will never experience a relapse or death due to the disease, survival time is infinite. So, for all finite values of t
Let U be an indicator of uncured patients, i.e. U=1 if the patient is not cured and U=0 otherwise. Let be the probability of being uncured given a covariate vector z. Farewell (1982, 1986) modeled the distribution of cure rate, defined as the proportion of cured observations in the population, following a logistic model: where b0 is a scalar parameter, b is a row vector of parameters and z a column vector of covariates. Then the mixture model is given as follows: (1) (2)
The proportional hazards assumption which is used in regular Cox model is also used in cure model to describe the effect of x on the distribution of the failure time of uncured patients. That is, the hazard function of an uncured patient with the covariate x at time t, denoted by hu (t | x), is given as where is an arbitrary unspecified baseline hazard function.
Suppose we have data in the form (ti,δi,xi,zi), i=1,2,…,n, where ti denotes the observed survival time for the ith patient, δi is the censoring indicator with 0 if ti is censored and 1 otherwise, and xi and zi are observed values of the two covariate vectors. The likelihood function for the mixture model is Plug in (1) and (2), we have (3)
a vector u=(u1,…,un) is defined where ui is the value of U for the ith patient. Recall, ui=1 if the patient is uncured and zero otherwise, i=1, 2,…, n. Obviously, the vector u is partially missing information because if δi =1, then ui=1, but if δi =0, ui is not observable and it can be 1 or 0. So ui is latent variable in our case. Given ui, i.e., the complete data are available, the complete likelihood function is (4) Comparing (3) and (4), If ui=1, then π(zi)= 1 and 1-π(zi)=0, so (3) and (4) is reduced to If ui=0, then π(zi)= 0 and 1-π(zi)=1, so (3) and (4) is reduced to Therefore, (4) which takes account of ui is equivalent to (3) which does not.
An expectation-maximization (EM) algorithm is used to find the maximum likelihood estimates of parameters in probalilistic models, where the model depends on unobserved latent variables. EM alternates between performing an expectation (E) step, which computes an expectation of the likelihood by including the latent variables as if they were observed, and a maximization (M) step, which computes the maximum likelihood estimates of the parameters by maximizing the expected likelihood found on the E step. The parameters found on the M step are then used to begin another E step, and the process is repeated. The E-step in the EM algorithm calculates the expectation of (4) for given the current estimates of fu(ti|xi), Su(ti|xi) and π(zi), which is the sum of following functions: (5) (6) where gi is the expectation of ui conditional on the current estimates of Su(t|x) and π(zi), given by (7)
which is the probability of the ith patient being uncured. Therefore, the E-step of the EM algorithm for this problem consists of assigning the probability gi to each patient. The M-step of the EM algorithm consists of maximizing (5) and (6) with respect to fu(.), Su(.) and b0, b for fixed gi. The advantage of using EM algorithm here is that the maximum likelihood estimates of the failure time distribution of uncured patients and b0, b can be obtained separately because (5) only depends on b0 and b while (6) only depends on the failure time distribution of uncured patients. Following Kalbfleisch and Prentice(1973), (6) can be approximated by If all patients are uncured, then gi=1. In this case, (8) reduces to the usual likelihood function used in Cox’s PH model which is (8)
Simulation We let x=z Control group: x=0 Trt group: x=1 Logistic parameters: b0=2 and b=-1 Control group uncured rate: 0.8808 Trt group uncured rate: 0.7311
Simulation We let ~ exp(1) and set Then ~exp(0.5) = = = = -0.693 =0.5 Since x=1, so
Simulation We will use function called semicure from Dr. Yingwei Peng (http://www.math.mun.ca/~ypeng/research/) semicure(Surv(time, cens) ~ transplant, ~ transplant, data = goldman.data)
Simulation Function: present.txt Simulation results: recall the true beta is -0.693 and b0=2 and b=-1
Simulation Histogram of beta:
Data Analysis Breast data set from textbook. 45 breast cancer patients SURV ---survival time The variable x: x=1 if the tumor had a positive marker for possible metastasis and x=0 otherwise Sort data by survival time in increasing order
Data Analysis---original breast cancer data Survival curve from SAS output 1.The curve is above 0.35 2.a number of long-term censored observations at the right tail
Data Analysis---original breast cancer data • For Coxph, p>0.05, metastasis is not significant in model survival time • ---contradiction with medical expectation • 2. For seimcure, p<0.05, metastasis is significant in model survival time • ---consistent with medical expetation • 3. Semicure gives higher hazard ratio compared to coxph
Data Analysis---modified breast cancer data with higher surv prob Change observations 32, 33, 34, 37 to be censored to make higher survival probability and more number of long-term censored observations at the tail of curve
Data Analysis---modified breast cancer data with higher surv prob • For Coxph, p=0.05, metastasis is still not significant in model survival time • ---result does not change a lot compared to original data set analysis • 2. For seimcure, p>0.70, metastasis is not significant in model survival time • ---reverse the conclusion compared to original data set analysis • 3. Semicure gives lower hazard ratio compared to coxph
Data Analysis---modified breast cancer data with lower surv prob Change observations 42, 43, 45 to be uncensored to make lower survival probability and less number of long-term censored observations at the tail of curve.
Data Analysis---modified breast cancer data with lower surv prob Two methods give almost same results
Data Analysis Betas in above three data sets are positive, which means patients with metastasis increase hazard to die compared to patients without.
Conclusion 1.Theoretically,gi=1, semicure is reduced to regular cox. 2.If survival curve satisfy: • High survival probabilty • A number of censored obs at the end of curve(tail) then Cox model with surviving fraction(semicure) gives more accurate result 3.If survival curve does not satisfy a, b then considering surviving fraction or not will not influence conclusion