Download

1 / 37
370 likes | 484 Views
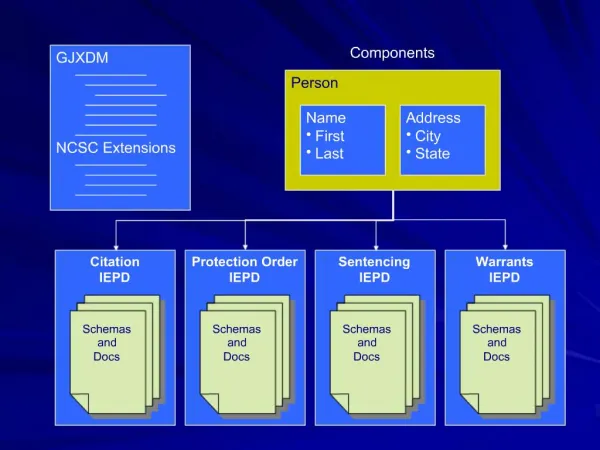
Consistent Cuts. Ken Birman. Idea. We would like to take a snapshot of the state of a distributed computation We’ll do this by asking participants to jot down their states Under what conditions can the resulting “puzzle pieces” be assembled into a consistent whole?. An instant in real-time.

E N D
Consistent Cuts Ken Birman
Idea • We would like to take a snapshot of the state of a distributed computation • We’ll do this by asking participants to jot down their states • Under what conditions can the resulting “puzzle pieces” be assembled into a consistent whole?
An instant in real-time • Imagine that we could photograph the system in real-time at some instant • Process state: • A set of variables and values • Channel state • Messages in transit through the network • In principle, the system is fully defined by the set of such states
Problems? • Real systems don’t have real-time snapshot facilities • In fact, real systems may not have channels in this sense, either • How can we approximate the real-time concept of a cut using purely “logical time”?
Deadlock detection • Need to detect cycles A B C D
Deadlock is a “stable” property • Once a deadlock occurs, it holds in all future states of the system • Easy to prove that if a snapshot is computed correctly, a stable condition detected in the snapshot will continue to hold • Insight is that adding events can’t “undo” the condition
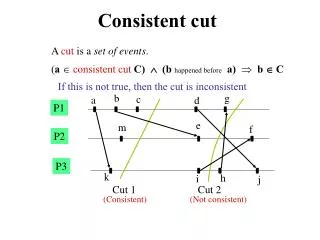
Leads us to define consistent cut and snapshot • Think of the execution of a process as a history of events, Lamport-style • Events can be local, msg-send, msg-rcv • A consistent snapshot is a set of history prefixes and messages closed under causality • A consistent cut is the frontier of a consistent snapshot – the “process states”
Deadlock detection • Need to detect cycles A B C D
Deadlock detection • Need to detect cycles A B C D
Deadlock detection • Need to detect cycles A B C D
Deadlock detection • A “ghost” or “false” cycle! A B C D
A ghost deadlock • Occurs when we accidently snapshot process states so as to include some events while omitting prior events • Can’t occur if the cut is computed consistently since this violates causal closure requirement
A ghost deadlock A B C D
A ghost deadlock A B C D
A ghost deadlock A B C D
Algorithms for computing consistent cuts • Paper focuses on a flooding algorithm • We’ll consider several other methods too • Logical timestamps • Flooding algorithm without blocking • Two-phase commit with blocking • Each pattern arises commonly in distributed systems we’ll look at in coming weeks
Cuts using logical clocks • Suppose that we have Lamport’s basic logical clocks • But we add a new operation called “snap” • Write down your process state • Create empty “channel state” structure • Set your logical clock to some big value • Think of clock as (epoch-number, counter)? • Record channel state until rcv message with big incoming clock value
How does this work? • Recall that with Lamport’s clocks, if e is causally prior to e’ then LT(e) < LT(e’) • Our scheme creates a snapshot for each process at instant it reaches logical time t • Easy to see that these events are concurrent: a possible instant in real-time • Depends upon FIFO channels, can’t easily tell when cut is complete – a sort of lazy version of the flooding algorithm
Flooding algorithm • To make a cut, observer sends out messages “snap” • On receiving “snap” the first time, A • Writes down its state, creates empty channel state record for all incoming channels • Sends “snap” to all neighbor processes Waits for “snap” on all incoming channels • A’s piece of the snapshot is its state and the channel contents once it receives “snap” from all neighbors • Note: also assumes FIFO channels
With 2-phase commit • In this, the initiator sends to all neighbors: • “Please halt” • A halts computation, sends “please halt” to all downstream neighbors • Waits for “halted” from all of them • Replies “halted” to upstream caller • Now initiator sends “snap” • A forwards “snap” downstream • Waits for replies • Collects them into its own state • Send’s own state to upstream caller and resumes
Why does this work? • Forces the system into an idle state • In this situation, nothing is changing… • Usually, sender in this scheme records unacknowledged outgoing channel state • Alternative: upstream process tells receiver how many incoming messages to await, receiver does so and includes them in its state. • So a snapshot can be safely computed and there is nothing unaccounted for in the channels
Observation • Suppose we use a two-phase property detection algorithm • In first phase, asks (for example), “what is your current state” • You reply “waiting for a reply from B” and give a “wait counter” • If a second round of the same algorithm detects the same condition with the same wait-counter values, the condition is stable…
A ghost deadlock A B C D
Look twice and it goes away… • But we could see “new” wait edges mimicking the old ones • This is why we need some form of counter to distinguish same-old condition from new edges on the same channels… • Easily extended to other conditions
Consistent cuts • Offer the illusion that you took a picture of the system at an instant in real-time • A powerful notion widely used in real systems • Especially valuable after a failure • Allows us to reconstruct the state so that we can repair it, e.g. recreate missing tokens • But has awkward hidden assumptions
Hidden assumptions • Use of FIFO channels is a problem • Many systems use some form of datagram • Many systems have multiple concurrent senders on same paths • These algorithms assume knowledge of system membership • Hard to make them fault-tolerant • Recall that a slow process can seem “faulty”
High costs • With flooding algorithm, n2messages • With 2-phase commit algorithm, system pauses for a long time • We’ll see some tricky ways to hide these costs either by continuing to run but somehow delaying delivery of messages to the application, or by treating the cut algorithm as a background task • Could have concurrent activities that view same messages in different ways…
Fault-tolerance • Many issues here • Who should run the algorithm? • If we decide that a process is faulty, what happens if a message from it then turns up? • What if failures leave a “hole” in the system state – missing messages or missing process state • Problems are overcome in virtual synchrony implementations of group communication tools
Systems issues • Suppose that I want to add notions such as real-time, logical time, consistent cuts, etc to a complex real-world operating system (list goes on) • How should these abstractions be integrated with the usual O/S interfaces, like the file system, the process subsystem, etc? • Only virtual synchrony has really tackled these kinds of questions, but one could imagine much better solutions. A possible research topic, for a PhD in software engineering
Theory issues • Lamport’s ideas are fundamentally rooted in static notions of system membership • Later with his work on Paxos he adds the idea of dynamically changing subsets of a static maximum set • Does true dynamicism, of sort used when we look at virtual synchrony, have fundamental implications?
Example of a theory question • Suppose that I want to add a “location” type to a language like Java: • Object o is at process p at computer x • Objects {a,b,c} are replicas of • Now notions of system membership and location are very fundamental to the type system • Need a logic of locations. How should it look? • Extend to a logic of replication and self-defined membership? But FLP lurks in the shadows…
Other questions • Checkpoint/rollback • Processes make checkpoints, probably when convenient • Some systems try to tell a process “when” to make them, using some form of signal or interrupt • But this tends to result in awkward, large checkpoints • Later if a fault occurs we can restart from the most recent checkpoint
So, where’s the question? • The issue arises when systems use message passing and want to checkpoint/restart • Few applications are deterministic • Clocks, signals, threads & scheduling, interrupts, multiple I/O channels, order in which messages arrived, user input… • When rolling forward from a checkpoint actions might not be identical • Hence anyone who “saw” my actions may be in a state that won’t be recreated!
Technical question • Suppose we make checkpoints in an uncoordinated manner • Now process p fails • Which other processes should roll back? • And how far might this rollback cascade?
Avoiding cascaded rollback? • Both making checkpoints, and rolling back, should happen along consistent cuts • In mid 1980’s several papers developed this into simple 2-phase protocols • Today would recognize them as algorithms that simply run on consistent cuts • For those who are interested: sender-based logging is the best algorithm in this area. (Alvisi’s work)