Download

1 / 49
610 likes | 1.05k Views
Hardware Accelerator . SangHeon Oh. Overview. Why we design Accelerators. Performance analysis. Architectural templates. Architecture design . Scheduling & Allocation A video accelerator design. Accelerated system architecture. accelerator. CPU. memory. I/O. CPUs and Accelerators.

E N D
Hardware Accelerator SangHeon Oh
Overview • Why we design Accelerators. • Performance analysis. • Architectural templates. • Architecture design . • Scheduling & Allocation • A video accelerator design. Digital Signal Processing
Accelerated system architecture accelerator CPU memory I/O Digital Signal Processing
CPUs and Accelerators • A co-processor executes instructions. • Co-processor is not Accelerator • Instructions are dispatched by the CPU. • An accelerator appears as a device on the bus. • The accelerator is controlled by registers. • 구현 • Custom IC 설계 (Application-specific integrated circuit.) • Field-programmable gate array (FPGA) 이용 . • Standard component. • Example: graphics processor. CODEC Processor • Processing Element (PE) • Mean any unit responsible for computation, Digital Signal Processing
용어 : FPGA(Field Programable Gate Array) • 특징 • 사용자가 프로그램 할 수 있는 게이트 배열. • 임의의 논리 회로를 사용자가 의도한대로 설계하고, 작동하도록 회로에 실장하여 하여 사용. • 사용중 설계 사항이 바뀌면 새롭게 바뀐 논리 회로를 FPGA 소자에입력하여, 바뀐 논리 회로로 즉시 작동 가능. • 장점 • ASIC 이전에 간단한 프로그래밍 기술로써 ASIC에 가까운 시스템 구현가능 • 용도 • 조기에 회로 설계구현 하고자 할때 • PCB 제작을 완료하고, 시험이나 사용하는 과정에서 세부 설계를 완성하고 수정하는 용도. • 혹은 ASIC 회로 설계 전에 중간 단계로 FPGA를 활용하는 방법 • FPGA 는 대략 3개의 공급 회사가 시장 점유가 높은편. Altera, Xilinx, Actel 등, Digital Signal Processing
request result data data Accelerated system architecture accelerator CPU memory I/O Digital Signal Processing
Why Accelerators? • Better cost/performance. • Custom logic may be able to perform operation faster than a CPU of equivalent cost. • CPU cost is a non-linear function of performance. • 성능을 조금 향상 되는데 고비용이 요구될 때가 있음. cost performance Digital Signal Processing
Why Accelerators(2) • Accelerators 사용에 관한 다른 몇 가지 경우 • Good for processing I/O in real-time. • May consume less energy. • May be better at streaming data. • May not be able to do all the work on even the largest single CPU. • 너무 많은 레지스터를 사용해야만 할때 • 그리고 산술연산과 관련된 식 구조상 precision의 컨트롤하기 위해서. Digital Signal Processing
Accelerator design • First, determine that the system really needs to be accelerated • How much faster is the accelerator on the core function? • Small microcontroller,-> GOOD Choice • high-performance CPU -> Challenge.. 괜한… • The accelerated function is real bottleneck? • READ/WRITE Speed 가 느려 병목현상을 불러 일으키는 것도 주의 • How much data transfer overhead? • 결국 실제 설계단계에서는 다음을 고려해줘야 한다. • CPU 상의 Application 이 Accelerator 의 레지스터와 어떻게 통신을 할것인가? • Shared Memory를 사용하여 구현하는점에 대해서 어떻게 동기화 할것인가. • 시스템 메모리로 부터 많은 양의 데이터를 read/write 할수 있는 address generation logic 구현을 어떻게 할것인가.. • 마지막으로 CPU에서 모든제어를 완료해야 하기때문에 CPU 상이 Application이 Accelerator 에게 언제 데이터를 가져가야 하는지 를 정확이 알려주고 • Accelerator가 동작을 마치는것을 기다리면서 동작을 마치면 Applicatioon이 데에터를 가져오는 작업을 해줘야 한다. Digital Signal Processing
Accelerated system design • Design Phase(단계) 는 아래의 것으로 구성된다. • Architecture(구조) • Component Design(요소 설계) • System Integration(시스템 통합) • 이러한 Accelerated System은 다음과 같은 특징이 있다 • 사용자는 어찌 돌아가는 지모른다. • SPEC 상 시스템의 동작은 동일하기 때문에 • The Design of the system architecture 무지 복잡해진다. • 대부분 multi-processor와 유사한 형태를 가지고 • Processing Elements 의 Computation 과 communication 이 병렬적으로 이루어진다. • => 덕분에 Performance analysis 는 복잡해지고, 새로운 설계를 고려해야만한다. Digital Signal Processing
Performance analysis • Critical parameter is speedup: how much faster is the system with the accelerator? • Speedup factor 는? • Depends on whether the system is single threaded or multithreaded • Blocking versus nonblocking. => 결국 병렬처리와 실행시간이 중요한데 문제는 Accelerator가 메인 메모리와의 데이터 통신 때문에 Data 를 읽고 쓰고 하는 시간도 결국 수행시간에 포함된다. • 수행성능 분석을 위해서 반드시 체크해야 하는것들. • Accelerator execution time • Data transfer time • Synchronization with the master CPU • Ease of programming (C, assembly language, etc.) Digital Signal Processing
Accelerator execution time • Total accelerator execution time: • taccel = tin + tx + tout Data input Data output Accelerated computation • - flushing register/cache values to main memory • - time required for CPU to set up transaction • - overhead of data transfers by bus packets, handshaking, etc. Memory Accelerator P CPU Digital Signal Processing
FIR Implementation y(n) = h(0)*dly(0)+h(1)*dly(2)+ … + h(N-1)*dly(N-1) Input_sample() dly(0) dly(1) dly(2) dly(N-2) dly(N-1) h(0) h(1) h(2) h(N-2) h(N-1) x x x x 입출력버퍼 x Output_sample() y + Processing Digital Signal Processing
Notch Filter을 이용한 Undesired signal 제거 • 테스트 음성신호에 특정잡음 제거 dly1[0] = input_sample(); //newest input @ top of buffer y1out = 0; //init output of 1st filter y2out = 0; //init output of 2nd filter for (i = 0; i< N; i++) y1out += h900[i]*dly1[i]; //y1(n)+=h900(i)*x(n-i) dly2[0]=(y1out >>15); //out of 1st filter->in 2nd filter for (i = 0; i< N; i++) y2out += h2700[i]*dly2[i]; //y2(n)+=h2700(i)*x(n-i) for (i = N-1; i > 0; i--) //from bottom of buffer { dly1[i] = dly1[i-1]; //update samples of 1st buffer dly2[i] = dly2[i-1]; //update samples of 2nd buffer } Digital Signal Processing
Accelerator speedup • Assume loop is executed n times • Compare accelerated system to non-accelerated system: • S = n(tCPU - taccel) = n[tCPU - (tin + tx + tout)] Execution time on CPU (by SW) Digital Signal Processing
Single- vs. multi-threaded • One critical factor is available parallelism: • single-threaded/blocking: CPU waits for accelerator • multithreaded/non-blocking: CPU continues to execute along with accelerator • To multithread, CPU must have useful work to do • But software must also support multithreading Digital Signal Processing
Single-threaded: Multi-threaded: A1 A1 P1 P2 P3 P4 P1 P3 P2 P4 Total execution time P1 P1 P2 A1 P2 A1 P3 P3 P4 Accelerator P4 Accelerator CPU CPU Digital Signal Processing
Accelerated systems(1) • Accelerator 는 2가지 관점에서 항상 고려되어 질수 있다 • Core 기능 => 무슨 기능을 할거냐… Filter? • CPU 와의 interface => CPU와 어떻게 통신할거냐? Bus ,register. => 이러한 연결에서는 internally Logic과 bus가 무자게 꼬인다. • Several off-the-shelf boards are available for acceleration in PCs: • FPGA-based core • Xlinks SRAM-based FPGA • ARM Integrator Logic Module • PC bus interface Digital Signal Processing
Accelerated systems(2) • Accelerator Core • 내부 레지스터를 사용함에 따라 Accelerator는 동작 • 주된 관점 : 얼마나 많은 레지스터를 사용할것이냐. • 메인 메모리 사용은 결국 시간적은 관점에서 Accelerator의 전체 동작시간을 느리게 만든다. • 이러한것을 극복하기 위해서 알고리즘이 Acceleratored 되어질경우 확정된 데이터를 미리 읽어 오는 작업을 수행함으로써 수행시간을 단축시킬수는 있다. • Accelerator/CPU interface • 기본적인 accelerator 의 control 은 레지스터를 이용함. • Status Registers 는 • accelerator 의 상태를 점검할수 있는 좋은방법으로 제공됨. • 기본적인 동작의 Start,Stop,and Reset 명령 방식으로 이용. • 데이터 전송을 위해서는 DMA 를 주로 이용 Digital Signal Processing
Memory CPU DMA Read Unit Interface Core Registers Write Unit Accelerator Read/write units in an accelerator Digital Signal Processing
Caching problems • Programs must ensure that a memory system behaves coherently • CPU reads location S • Accelerator writes location S • CPU reads S from Cache [BAD] Digital Signal Processing
Synchronization • If CPU and accelerator operate concurrently and communicate via shared memory system • Want access to the same block of mem at the same time • Need synchronization • Test-and-set operation (semaphore) for Shared Memory Digital Signal Processing
Partitioning • Divide functional specification into units. • Map units onto PEs • Units may become processes • Determine proper level of parallelism: 결과값이 독립적 f1() f2() f3(f1(),f2()) vs. f3() Partitioning 는 결국 수행성능평가를 직접실행해봐야 정확히 체크가됨 Digital Signal Processing
Partitioning methodology • Divide CDFG into pieces, shuffle functions between pieces • Hierarchically decompose CDFG to identify possible partitions Digital Signal Processing
P1 P2 P4 P5 P3 Partitioning example cond 1 cond 2 Block 1 Block 2 Block 3 Digital Signal Processing
Scheduling and allocation • Must: • schedule operations in time • allocate computations to processing elements • Scheduling and allocation interact, but separating them helps • Alternatively allocate, then schedule Digital Signal Processing
Example: scheduling and allocationand Process execution time unit P1 P2 d1 d2 P3 4 time Task graph M1 M2 2 time process execution times P3 이란 프로세싱을 못함 eX) multiply 못하는경우 Hardware platform Digital Signal Processing
Example communication model • Assume communication within PE is free • Cost of communication from P1 to P3 is d1 =2; • cost of P2->P3 communication is d2 = 4 Digital Signal Processing
Time = 19 First design • Allocate P1, P2 -> M1; P3 -> M2. M1 P1 P2 M2 P3 network d2 5 10 15 20 time Digital Signal Processing
Time = 18 Second design • Allocate P1 -> M1; P2, P3 -> M2: M1 P1 M2 P2 P3 network d1 5 10 15 20 Digital Signal Processing
Time = 12 Third design • Allocate P1 -> M1; P2, P3 -> M2: M1 P1 M2 P2 P3 network d2 5 10 15 20 Digital Signal Processing
Ex) TMS3206711 에서 스케줄링과 Allocation • 8 Independent Functional units • Split into two identical datapaths • each contains the same four units (L, S, D, M) • L : 32/40bit arithmetic and compare operation,32bit logical operation, • S : 32/40bit arithmetic Operation, Branches • D : 32bit Integer adder, Subtract, linear and circular address, Load-Store, 32bit logical Operation. • M : 16 bit Multiplier /32bit Fixed point multiplier, • Note that Integer additions can be done on 6 of 8 units. • It’s because it is common. Digital Signal Processing
Ex) TMS3206711 에서 스케줄링과 Allocation MVK .S1 50,A1 || ZERO .L1 A7 || ZERO .L2 B7 LOOP: LDW .D1 *A4++,A2 ; Word 단위 READ || LDW .D2 *B4++,B2 SUB .S1 A1,1,A1 [A1] B .S2 LOOP NOP 2 MPY .M1x A2,B2,A6 || MPY .M2x A2,B2,B6 NOP ADD .L1 A6,A7,A7 || ADD .L2 B6,B7,B7 ;Branch occurs here ADD .L1x A7,B7,A4 a[i]&a[i+1] b[i] & b[i+1] D1 D2 5 5 5 5 P[i] P[i+1] M2x M1x 2 2 L1 L2 Suml Sumh 1 1 S1 -1 1 Count Loop S2 1 Digital Signal Processing
Ex) TMS3206711 에서 스케줄링과 Allocation Digital Signal Processing
Ex) TMS3206711 에서 스케줄링과 Allocation Digital Signal Processing
System integration and debugging • Accelerator system의 디자인에서는 • 기본적으로 자신의 Logic 에 대한 Debugging도 필요하지만. • 반드시 하드웨어적인 상호적용을 염두에 두어야 한다. • Try to debug the CPU/accelerator interface separately from the accelerator core • Build scaffolding to test the accelerator • Hardware/software co-simulation can be useful • 종합적인 시뮬레이션을 돌려라. Digital Signal Processing
Accelerators • Example: video accelerator Digital Signal Processing
Concept • Build accelerator for block motion estimation, one step in video compression. • Perform two-dimensional correlation: Frame 1 f2 f2 f2 f2 f2 f2 f2 f2 f2 f2 Digital Signal Processing
Block motion estimation • MPEG divides frame into 16 x 16 macroblocks for motion estimation. • Search for best match within a search range. • Measure similarity with sum-of-absolute-differences (SAD): • S | M(i,j) - S(i-ox, j-oy) | Digital Signal Processing
Best match • Best match produces motion vector for motion block: Digital Signal Processing
Full search algorithm bestx = 0; besty = 0; bestsad = MAXSAD; for (ox = - SEARCHSIZE; ox < SEARCHSIZE; ox++) { for (oy = -SEARCHSIZE; oy < SEARCHSIZE; oy++) { int result = 0; for (i=0; i<MBSIZE; i++) { for (j=0; j<MBSIZE; j++) { result += iabs(mb[i][j] - search[i-ox+XCENTER][j-oy-YCENTER]); } } if (result <= bestsad) { bestsad = result; bestx = ox; besty = oy; } } } Digital Signal Processing
Computational requirements • Let MBSIZE = 16, SEARCHSIZE = 8. • Search area is 8 + 8 + 1 in each dimension. • Must perform: • nops = (16 x 16) x (17 x 17) = 73984 ops • CIF format has 352 x 288 pixels -> 22 x 18 macroblocks. Digital Signal Processing
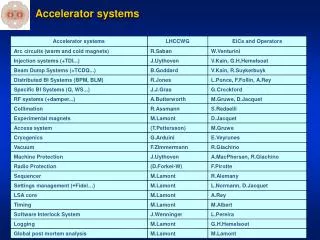
Accelerator requirements Digital Signal Processing
Accelerator data types, basic classes Motion-vector Macroblock Search-area x, y : pos pixels[] : pixelval pixels[] : pixelval PC Motion-estimator memory[] compute-mv() Digital Signal Processing
Sequence diagram :PC :Motion-estimator compute-mv() Search area memory[] memory[] macroblocks memory[] Digital Signal Processing
Architectural considerations • Requires large amount of memory: • macroblock has 256 pixels; • search area has 1,089 pixels. • May need external memory (especially if buffering multiple macroblocks/search areas). Digital Signal Processing
Motion estimator organization PE 0 search area network PE 1 comparator ctrl Address generator ... Motion vector macroblock network PE 15 Digital Signal Processing
M(0,0) S(0,2) Pixel schedules Digital Signal Processing
System testing • Testing requires a large amount of data. • Use simple patterns with obvious answers for initial tests. • Extract sample data from JPEG pictures for more realistic tests. Digital Signal Processing