Download

1 / 63
630 likes | 693 Views
Computational Intelligence for Data Mining. Włodzisław Duch Department of Informatics Nicholas Copernicus University Torun, Poland W ith help from R . Adamczak , K . Grąbczewski K . Grudziński , N . Jankowski , A . Naud http://www.phys.uni.torun.pl/kmk.

E N D
Computational Intelligence for Data Mining Włodzisław Duch Department of Informatics Nicholas Copernicus University Torun, Poland With help from R. Adamczak, K. Grąbczewski K. Grudziński, N. Jankowski, A. Naud http://www.phys.uni.torun.pl/kmk WCCI 2002, Honolulu, HI
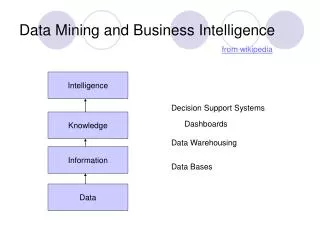
What this tutorial is about ? How to discover knowledge in data; how to create comprehensible models of data; how to evaluate new data. Plan • AI, CI & Data Mining • Forms of useful knowledge • GhostMiner philosophy • Exploration & Visualization • Rule-based data analysis • Neurofuzzy models • Neural models • Similarity-based models • Committees of models
Artificial Intelligence: symbolic models of knowledge. Higher-level cognition: reasoning, problem solving,planning, heuristic search for solutions. Machine learning, inductive, rule-based methods. Technology: expert systems. AI, CI & DM Computational Intelligence, Soft Computing: methods inspired by many sources: • biology – evolutionary, immune, neural computing • statistics, patter recognition • probability – Bayesian networks • logic – fuzzy, rough … Perception, object recognition. Data Mining, Knowledge Discovery in Databases. • discovery of interesting patterns, rules, knowledge. • building predictive data models.
Forms of useful knowledge AI/Machine Learning camp: Neural nets are black boxes. Unacceptable! Symbolic rules forever. But ... knowledge accessible to humans is in: • symbols, • similarity to prototypes, • images, visual representations. What type of explanation is satisfactory? Interesting question for cognitive scientists. Different answers in different fields.
Forms of knowledge • Humans remember examples of each category and refer to such examples – as similarity-based or nearest-neighbors methods do. • Humans create prototypes out of many examples – as Gaussian classifiers, RBF networks, neurofuzzy systems do. • Logical rules are the highest form of summarization of knowledge. Types of explanation: • exemplar-based: prototypes and similarity; • logic-based: symbols and rules; • visualization-based: maps, diagrams, relations ...
GhostMiner Philosophy GhostMiner, data mining tools from our lab. • Separate the process of model building and knowledge discovery from model use => GhostMiner Developer & GhostMiner Analyzer • There is no free lunch – provide different type of tools for knowledge discovery. Decision tree, neural, neurofuzzy, similarity-based, committees. • Provide tools for visualization of data. • Support the process of knowledge discovery/model building and evaluating, organizing it into projects.
Wine data example Chemical analysis of wine from grapes grown in the same region in Italy, but derived from three different cultivars.Task: recognize the source of wine sample.13 quantities measured, continuous features: • alcohol content • ash content • magnesium content • flavanoids content • proanthocyanins phenols content • OD280/D315 of diluted wines • malic acid content • alkalinity of ash • total phenols content • nonanthocyanins phenols content • color intensity • hue • proline.
Exploration and visualization General info about the data
Exploration: data Inspect the data
Exploration: data statistics Distribution of feature values Proline has very large values, the data should be standardized before further processing.
Exploration: data standardized Standardized data: unit standard deviation, about 2/3 of all data should fall within [mean-std,mean+std] Other options: normalize to fit in[-1,+1], or normalize rejecting some extreme values.
Exploration: 1D histograms Distribution of feature values in clasess Some features are more useful than the others.
Exploration: 1D/3D histograms Distribution of feature values in clasess, 3D
Exploration: 2D projections Projections on selected 2D Projections on selected 2D
Visualize data Hard to imagine relations in more than 3D. SOM mappings: popular for visualization, but rather inaccurate, no measure of distortions. Measure of topographical distortions: map all Xipoints from Rnto xipoints inRm, m < n, and ask: how well are Rij = D(Xi,Xj) distances reproduced by distances rij = d(xi,xj) ?Use m = 2 for visualization, use higher m for dimensionality reduction.
Visualize data: MDS Multidimensional scaling: invented in psychometry by Torgerson (1952), re-invented by Sammon (1969) and myself (1994) … Minimize measure of topographical distortions moving the x coordinates.
Visualize data: Wine 3 clusters are clearly distinguished, 2D is fine. The green outlier can be identified easily.
Decision trees Simplest things first: use decision tree to find logical rules. Test single attribute, find good point to split the data, separating vectors from different classes. DT advantages: fast, simple, easy to understand, easy to program, many good algorithms.
Decision borders Univariate trees: test the value of a single attribute x < a. Multivariate trees: test on combinations of attributes. Result: feature space is divided in hyperrectangular areas.
SSV decision tree Separability Split Value tree: based on the separability criterion. Define left and right sides of the splits: SSV criterion: separate as many pairs of vectors from different classes as possible; minimize the number of separated from the same class.
SSV – complex tree Trees may always learn to achieve 100% accuracy. Very few vectors are left in the leaves!
SSV – simplest tree Pruning finds the nodes that should be removed to increase generalization – accuracy on unseen data. Trees with 7 nodes left: 15 errors/178 vectors.
SSV – logical rules Trees may be converted to logical rules. Simplest tree leads to 4 logical rules: • if proline > 719 and flavanoids > 2.3 then class 1 • if proline < 719 and OD280 > 2.115 then class 2 • if proline > 719 and flavanoids < 2.3 then class 3 • if proline < 719 and OD280 < 2.115 then class 3 How accurate are such rules? Not 15/178 errors, or 91.5% accuracy! Run 10-fold CV and average the results.85±10%? Run 10X!
SSV – optimal trees/rules Optimal: estimate how well rules will generalize. Use stratified crossvalidation for training; use beam search for better results. • if OD280/D315 > 2.505 and proline > 726.5 then class 1 • if OD280/D315 < 2.505 and hue > 0.875 and malic-acid < 2.82 then class 2 • if OD280/D315 > 2.505 and proline < 726.5 then class 2 • if OD280/D315 < 2.505 and hue > 0.875 and malic-acid > 2.82 then class 3 • if OD280/D315 < 2.505 and hue < 0.875 then class 3 Note 6/178 errors, or 91.5% accuracy! Run 10-fold CV: results are 90.4±6.1%? Run 10X!
Crisp logic rules: for continuous x use linguistic variables (predicate functions). Logical rules sk(x) şTrue [XkŁxŁX'k], for example: small(x) = True{x|x<1} medium(x) = True{x|xÎ[1,2]} large(x) = True{x|x>2} Linguistic variables are used in crisp (prepositional, Boolean) logic rules: IF small-height(X) AND has-hat(X) AND has-beard(X) THEN (X is a Brownie) ELSE IF ... ELSE ...
Crisp logic is based on rectangular membership functions: Crisp logic decisions True/False values jump from 0 to 1. Step functions are used for partitioning of the feature space. Very simple hyper-rectangular decision borders. Sever limitation on the expressive power of crisp logical rules!
Logical rules, if simple enough, are preferable. IF the number of rules is relatively small AND the accuracy is sufficiently high. THEN rules may be an optimal choice. Logical rules - advantages • Rules may expose limitations of black box solutions. • Only relevant features are used in rules. • Rules may sometimes be more accurate than NN and other CI methods. • Overfitting is easy to control, rules usually have small number of parameters. • Rules forever !? A logical rule about logical rules is:
Logical rules are preferred but ... Logical rules - limitations • Only one class is predicted p(Ci|X,M) = 0 or 1 black-and-white picture may be inappropriate in many applications. • Discontinuous cost function allow only non-gradient optimization. • Sets of rules are unstable: small change in the dataset leads to a large change in structure of complex sets of rules. • Reliable crisp rules may reject some cases as unclassified. • Interpretation of crisp rules may be misleading. • Fuzzy rules are not so comprehensible.
How to use logical rules? Data has been measured with unknown error. Assume Gaussian distribution: x – fuzzy number with Gaussian membership function. A set of logical rules R is used for fuzzy input vectors: Monte Carlo simulations for arbitrary system => p(Ci|X) Analytical evaluationp(C|X) is based on cumulant: Error function is identical to logistic f. < 0.02
Rules - choices Simplicity vs. accuracy. Confidence vs. rejection rate. p++ is a hit; p-+ false alarm; p+- is a miss.
Rules – error functions The overall accuracy is equal to a combination of sensitivity and specificity weighted by the a priori probabilities: A(M) = p+S+(M)+p-S-(M) Optimization of rules for the C+ class; large g means no errors but high rejection rate. E(M+;g)= gL(M+)-A(M+)= g(p+-+p-+)-(p+++p--)minM E(M;g) minM{(1+g)L(M)+R(M)} Optimization with different costs of errors minM E(M;a) = minM{p+-+ a p-+} = minM{p+(1-S+(M)) -p+r(M)+a [p-(1-S-(M)) -p-r(M)]} ROC (Receiver Operating Curve): p++ (p-+), hit(false alarm).
Fuzzification of rules RuleRa(x) = {x>a} is fulfilled byGxwith probability: Error function is approximated by logistic function; assuming error distributions(x)(1- s(x)), fors2=1.7 approximates Gauss<3.5% RuleRab(x) = {b> x>a} is fulfilled byGxwith probability:
Soft trapezoids and NN The difference between two sigmoids makes a soft trapezoidal membership functions. Conclusion: fuzzy logic withs(x) -s(x-b)m.f. is equivalent to crisp logic + Gaussian uncertainty.
Optimization of rules Fuzzy: large receptive fields, rough estimations. Gx – uncertainty of inputs, small receptive fields. Minimization of the number of errors – difficult, non-gradient, but now Monte Carlo or analytical p(C|X;M). • Gradient optimization works for large number of parameters. • Parameterssxare known for some features, use them as optimization parameters for others! • Probabilities instead of 0/1 rule outcomes. • Vectors that were not classified by crisp rules have now non-zero probabilities.
Mushrooms The Mushroom Guide: no simple rule for mushrooms; no rule like: ‘leaflets three, let it be’ for Poisonous Oak and Ivy. 8124 cases, 51.8% are edible, the rest non-edible. 22 symbolic attributes, up to 12 values each, equivalent to 118 logical features, or 2118=3.1035 possible input vectors. Odor: almond, anise, creosote, fishy, foul, musty, none, pungent, spicy Spore print color: black, brown, buff, chocolate, green, orange, purple, white, yellow. Safe rule for edible mushrooms: odor=(almond.or.anise.or.none) Ů spore-print-color = Ř green 48 errors, 99.41% correct This is why animals have such a good sense of smell! What does it tell us about odor receptors?
Mushrooms rules To eat or not to eat, this is the question! Not any more ... A mushroom is poisonous if: R1) odor = Ř (almond Ú anise Ú none); 120 errors, 98.52% R2) spore-print-color = green 48 errors, 99.41% R3) odor = none Ů stalk-surface-below-ring = scaly Ů stalk-color-above-ring = Ř brown 8 errors, 99.90% R4) habitat = leaves Ů cap-color = white no errors! R1 + R2are quite stable, found even with 10% of data; R3and R4may be replaced by other rules, ex: R'3): gill-size=narrow Ů stalk-surface-above-ring=(silky Ú scaly) R'4): gill-size=narrow Ů population=clustered Only 5 of 22 attributes used! Simplest possible rules? 100% in CV tests - structure of this data is completely clear.
Recurrence of breast cancer Institute of Oncology, University Medical Center, Ljubljana. 286 cases, 201 no (70.3%), 85 recurrence cases (29.7%) 9 symbolic features: age (9 bins), tumor-size (12 bins), nodes involved (13 bins), degree-malignant (1,2,3), area, radiation, menopause, node-caps. no-recurrence,40-49,premeno,25-29,0-2,?,2, left, right_low, yes Many systems tried, 65-78% accuracy reported. Single rule: IF (nodes-involved [0,2] Ù degree-malignant = 3 THEN recurrence ELSE no-recurrence 77% accuracy, only trivial knowledge in the data: highly malignant cancer involving many nodes is likely to strike back.
Neurofuzzy system Fuzzy: m(x)=0,1 (no/yes) replaced by a degree m(x)[0,1]. Triangular, trapezoidal, Gaussian or other membership f. Feature Space Mapping (FSM) neurofuzzy system. Neural adaptation, estimation of probability density distribution (PDF) using single hidden layer network (RBF-like) with nodes realizing separable functions: M.f-s in many dimensions:
FSM Initialize using clusterization or decision trees. Triangular & Gaussian f. for fuzzy rules. Rectangular functions for crisp rules. Rectangular functions: simple rules are created, many nearly equivalent descriptions of this data exist. If proline > 929.5 then class 1 (48 cases, 45 correct + 2 recovered by other rules). If color < 3.79285 then class 2 (63 cases, 60 correct) Interesting rules, but overall accuracy is only 88±9% Between 9-14 rules with triangular membership functions are created; accuracy in 10xCV tests about 96±4.5% Similar results obtained with Gaussian functions.
Prototype-based rules C-rules (Crisp), are a special case of F-rules (fuzzy rules). F-rules (fuzzy rules) are a special case of P-rules (Prototype). P-rules have the form: IF P = arg minR D(X,R) THAN Class(X)=Class(P) D(X,R) is a dissimilarity (distance) function, determining decision borders around prototype P. P-rules are easy to interpret! IF X=You are most similar to the P=SupermanTHAN You are in the Super-league. IF X=You are most similar to the P=Weakling THAN You are in the Failed-league. “Similar” may involve different features or D(X,P).
P-rules Euclidean distance leads to a Gaussian fuzzy membership functions + product as T-norm. Manhattan function =>m(X;P)=exp{-|X-P|} Various distance functions lead to different MF. Ex. data-dependent distance functions, for symbolic data:
Promoters DNA strings, 57 aminoacids, 53 + and 53 - samples tactagcaatacgcttgcgttcggtggttaagtatgtataatgcgcgggcttgtcgt Euclidean distance, symbolic s =a, c, t, g replaced by x=1, 2, 3, 4 PDF distance, symbolic s=a, c, t, g replaced by p(s|+)
P-rules New distance functions from info theory => interesting MF. MF => new distance function, with local D(X,R) for each cluster. Crisp logic rules: use Lnorm: DCh(X,P) = ||X-P|| = maxiWi |Xi-Pi| DCh(X,P) = const => rectangular contours. Chebyshev distance with thresholds P IF DCh(X,P) PTHENC(X)=C(P) is equivalent to a conjunctive crisp rule IFX1[P1-P/W1,P1+P/W1] …XN[PN -P/WN,PN+P/WN]THENC(X)=C(P)
Decision borders D(P,X)=const and decision borders D(P,X)=D(Q,X). Euclidean distance from 3 prototypes, one per class. Minkovski a=20 distance from 3 prototypes.
P-rules for Wine Manhattan distance: 6 prototypes kept, 4 errors, f2 removed Chebyshev distance: 15 prototypes kept, 5 errors, f2, f8, f10 removed Euclidean distance: 11 prototypes kept, 7 errors Many other solutions.
Neural networks • MLP – Multilayer Perceptrons, most popular NN models. Use soft hyperplanes for discrimination. Results are difficult to interpret, complex decision borders. Prediction, approximation: infinite number of classes. • RBF – Radial Basis Functions. • RBF with Gaussian functions are equivalent to fuzzy systems with Gaussian membership functions, but … • No feature selection => complex rules. • Other radial functions => not separable! • Use separable functions, not radial => FSM. • Many methods to convert MLP NN to logical rules.
Why is it difficult? Rules from MLPs Multi-layer perceptron (MLP) networks: stack many perceptron units, performing threshold logic: M-of-N rule: IF (M conditions of N are true) THEN ... Problem: for N inputs number of subsets is 2N. Exponentially growing number of possible conjunctive rules.
Converts MLP neural networks into a network performing logical operations (LN). MLP2LN Input layer Output: one node per class. Aggregation: better features Linguistic units: windows, filters Rule units: threshold logic
Constructive algorithm: add as many nodes as needed. MLP2LN training Optimize cost function: minimize errors + enforce zero connections + leave only +1 and -1 weights makes interpretation easy.