Download
1 / 9
90 likes | 100 Views
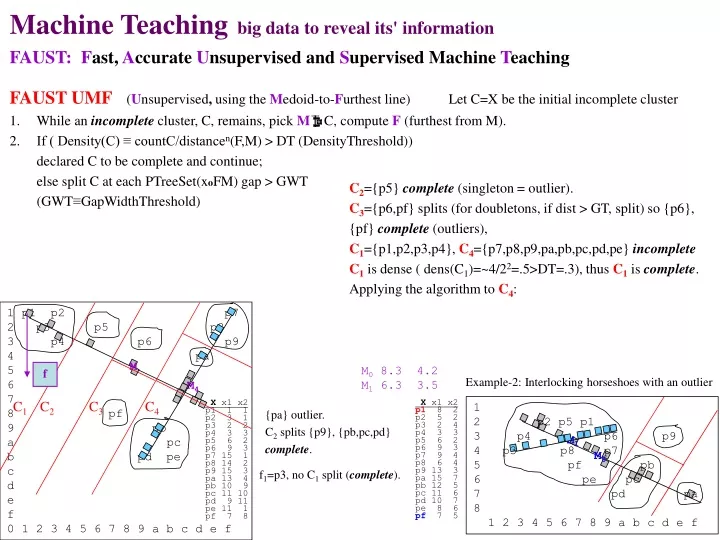
Machine Teaching big data to reveal its' information FAUST: F ast, A ccurate U nsupervised and S upervised Machine T eaching FAUST UMF ( U nsupervised , using the M edoid-to- F urthest line) Let C=X be the initial incomplete cluster

E N D
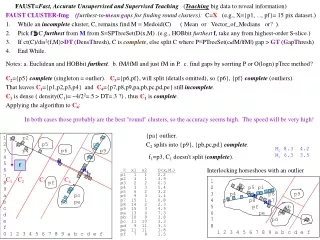
Machine Teaching big data to reveal its' information • FAUST:Fast, Accurate Unsupervised and Supervised Machine Teaching • FAUST UMF(Unsupervised, using theMedoid-to-Furthest line)Let C=X be the initial incomplete cluster • While an incomplete cluster, C, remains, pick MC, compute F (furthest from M). • If ( Density(C) ≡ countC/distancen(F,M) > DT (DensityThreshold)) • declared C to be complete and continue; • else split C at each PTreeSet(xoFM) gap > GWT • (GWT≡GapWidthThreshold) 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f Example-2: Interlocking horseshoes with an outlier X x1 x2 p1 8 2 p2 5 2 p3 2 4 p4 3 3 p5 6 2 p6 9 3 p7 9 4 p8 6 4 p9 13 3 pa 15 7 pb 12 5 pc 11 6 pd 10 7 pe 8 6 pf 7 5 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 1 pf 7 8 1 2 p2 p5 p1 3 p4 p6 p9 4 p3 p8 p7 5 pf pb 6 pe pc 7 pd pa 8 1 2 3 4 5 6 7 8 9 a b c d e f C2={p5} complete (singleton = outlier). C3={p6,pf} splits (for doubletons, if dist > GT, split) so {p6}, {pf} complete (outliers), C1={p1,p2,p3,p4}, C4={p7,p8,p9,pa,pb,pc,pd,pe} incomplete C1 is dense ( dens(C1)=~4/22=.5>DT=.3), thus C1is complete. Applying the algorithm to C4: M M0 8.3 4.2 M1 6.3 3.5 f M4 C1 C2 C3 C4 {pa} outlier. C2 splits {p9}, {pb,pc,pd} complete. M1 M0 f1=p3, no C1 split (complete).
F=p1 and xoFM, T=23. Illustration of the first round of finding gaps p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 pTree gap finderusing PTreeSet(xofM) xofM 11 27 23 34 53 80 118 114 125 114 110 121 109 125 83 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p2 0 0 1 0 1 0 1 0 1 0 1 0 1 1 0 p1 1 1 1 1 0 0 1 1 0 1 1 0 0 0 1 p0 1 1 1 0 1 0 0 0 1 0 0 1 1 1 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p2' 1 1 0 1 0 1 0 1 0 1 0 1 0 0 1 p1' 0 0 0 0 1 1 0 0 1 0 0 1 1 1 0 p0' 0 0 0 1 0 1 1 1 0 1 1 0 0 0 0 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 f= For FAUST SMM (Oblique), do a similar thing on the MrMv line. Record the number of r and v errors if RtEndPt is used to split. Take RtEndPt where sum min Parallelizes easily. Useful in pTree sorting? OR between gap 2 and 3 for cluster C2={p5} width=23 =8 gap: [010 1000, 010 1111] =[40,48) width=23=8 gap: [000 0000, 000 0111]=[0,8) width=23 =8 gap: [011 1000, 011 1111] =[56,64) width = 24 =16 gap: [100 0000, 100 1111]= [64,80) width= 24 =16 gap: [101 1000, 110 0111]=[88,104) OR between gap 1 & 2 for cluster C1={p1,p3,p2,p4} between 3,4 cluster C3={p6,pf} Or for cluster C4={p7,p8,p9,pa,pb,pc,pd,pe}
FAUST UFF(Unsupervised, using theFurthest-to-Furthest line)Let C=X be the initial incomplete cluster • While an incomplete cluster, C, remains, pick MC, compute F (furthest from M) and compute G (furthest from F) • If ( Density(C) ≡ countC/distancen(F,M) > DT (DensityThreshold)) declared C to be complete and continue; else split C into {Ci} at each PTreeSet(xoFG) gap > GWT (GapWidthThreshold) C21: closer p7 than pd C22↓ C1= pts closer to f=p1 than g=pe C11 C12 ↓ 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c 0 1 2 3 4 5 6 7 8 9 a b c d e f M1 M0 dis toM0 8.4 6.7 7.1 5.8 3.7 1.7 7.4 6.0 6.6 4.4 4.4 5.7 6.2 6.7 3.6 distoF(=p1) 0 2 1.41 2.82 5.09 8.24 14 13.0 14.1 12.3 12.0 13.4 12.8 14.1 9.21 distoG(=pe) 14.1 12.8 12.7 11.3 10.2 8.24 10.7 9.48 8.94 7.28 2.23 1 2 0 5 M2 dis toM 2.1 0.8 1.0 1.2 3.0 dis toF 5.09 3.16 4 3.16 0 dis toG 0 2 1.41 2.82 5.09 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 8 11.6 10.2 10 8.06 2.23 2.23 0 2 3.60 4.2 2.4 1 1.8 1.4 6.3 0 1.4 2 3.6 6.32 0 1.41 2 3.60 9.43 9.84 11.6 10.7 10.6 0 6.3 5.0 6 4.1 4 6.3 4.9 4.8 2.7 3.1 3.8 5.3 4.8 4.7 0 1.4 2 3.6 3.6 2.2 2.2 0 1.6 0.5 0.9 1.9 2.2 1 2 0 5 3.1 4.4 3.6 5 0 0.8 1.4 1.3 1.8 3.1 M0 8.6 4.7 M1 3 1.8 M2 11 6.2 dens(X)= 16/8.42=.23<DT=1.5 incomplete densC2121=3/12=3>DT complete. dens(C1)= 5/32=.55<DT, C1incomplete C2122={pa}complete M21 (13.2 2.6) C12={p5} complete. C114/1.42= 2>DT, dens complete. M212 (14.2 2.5) C222 = {pf} singleton so complete( outlier). densC2≡ct/d(M2,F2)2=10/6.32=.25<DT, incomplete. M22 ( 9.6 9.8) C221 density= 4/1.42= 2.04>DT, complete densC21=5/4.22=.28<DT incomplete. M221 (10.2 10.2)
vomV vomR d-line d v2 v1 std of distances, vod, from origin along the d-line FAUST SMM Supervised Medoid-to-Medoid version(AKA, FAUST Oblique) PR=P(X o dR ) < aR1 pass gives classR pTree D≡ mRmV d=D/|D| Separate class R using midpoint of means method: Calc a (mR+(mV-mR)/2)od = a = (mR+mV)/2od(works also if D=mVmR, Training≡placingcut-hyper-plane(s) (CHP) (= n-1 dim hyperplane cutting space in two). Classification is 1 horizontal program (AND/OR) across pTrees, giving a mask pTree for each entire predicted class (all unclassifieds at-a-time) Accuracy improvement? Consider the dispersion within classes when placing the CHP. E.g., use the 1. vectors_of_median, vom, to represent each class, not the mean mV, where vomV ≡(median{v1|vV}, 2. midpt_std, vom_std methods: project each class on d-line; then calculate std (one horizontal formula per class using Md's method); then use the std ratio to place CHP (No longer at the midpoint between mr and mv median{v2|vV}, ...) dim 2 Note:training (finding a and d) is a one-time process. If we don’t have training pTrees, we can use horizontal data for a,d (one time) then apply the formula to test data (as pTrees) r r vv r mR r v v v r r v mV v r v v r v dim 1 Next, use "Gap Finder" to find all gaps with different endpts (rv or vr): Record the number of r and v errors if GapMidPt is used to split. Select as split pt, the GPM where errors are minimized.
FAUST SMM PR=P(X o dR ) < aRD≡ mRmB Use "Gap Finder" to find all gaps with different EndPoints: Record the number of R and B errors if GapEndPoint is used to split. Select as split pt, the GEP where the sum of the R errors and the B errors are minimized. That is, on the MR-MB line, record the sum of the R and B errors if RtEndPt is used to split. X x1 x2 p1 3 6 p2 6 1 p3 4 2 p4 3 4 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 12 3 pa 10 3 pb 10 6 pc 9 7 pd 9 8 pe 12 6 pf 12 5 1 p2 p7 2 p3 p5 p8 3 p6 pa p9 4 p4 5 pf 6p1 pb pe 7 pc 8 pd 9 a b c 1 2 3 4 5 6 7 8 9 a b c d e f M M
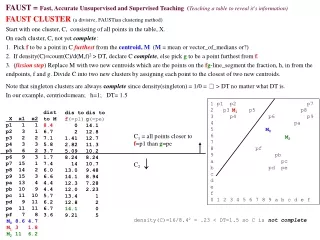
APPENDIX: FAUST UMF (no density) Initially C=X. • While an incomplete C, remains (1 pTree calculation) find M (=mean(C)). • Create PTreeSet(D(x,M). (1 pTree calculation) Pick F to be a furthest point from M. • Create PTreeSet(xoFM) (1 pTree calculation) • Split at each PTS(xoFM)-gap > T (1 pTree calculation). If there are none, continue (declaring C complete). Example-2: Interlocking horseshoes with an outlier X x1 x2 p1 8 2 p2 5 2 p3 2 4 p4 3 3 p5 6 2 p6 9 3 p7 9 4 p8 6 4 p9 13 3 pa 15 7 pb 12 5 pc 11 6 pd 10 7 pe 8 6 pf 7 5 1 2 p2 p5 p1 3 p4 p6 p9 4 p3 p8 p7 5 pf pb 6 pe pc 7 pd pa 8 1 2 3 4 5 6 7 8 9 a b c d e f C2={p5} complete (singleton = outlier). C3={p6,pf}, will split (details omitted), so {p6}, {pf} complete (outliers). That leaves C1={p1,p2,p3,p4} and C4={p7,p8,p9,pa,pb,pc,pd,pe} still incomplete. C1 doesn't split and is complete. Applying the algorithm to C4: This algorithm takes 4 pTree calculations only. If we use "any point" rather than M=mean, that eliminates create mean (next slide, M=bottom point rather than the Mean.) {pa} outlier. C2 splits into {p9}, {pb,pc,pd} which doesn't split so complete. 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f M0 8.3 4.2 M1 6.3 3.5 f1=p3, C1 doesn't split so complete. M f M4 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 C1 C2 C3 C4 M1 M0
FAUST UMF (no density, M=bottom point) Initially C=X. • While an incomplete cluster, C, remains find M (no pTree calculations). • Create S ≡ PTreeSet(D(x,M). Pick f to be a furthest point from M (1 pTree calculation) • Split at each PTreeSet(coFM)-gap > T. If none, continue (C complete) (1 pTree calculation). Example-2: Interlocking horseshoes with an outlier X x1 x2 p1 8 2 p2 5 2 p3 2 4 p4 3 3 p5 6 2 p6 9 3 p7 9 4 p8 6 4 p9 13 3 pa 15 7 pb 12 5 pc 11 6 pd 10 7 pe 8 6 pf 7 5 1 2 p2 p5 p1 3 p4 p6 p9 4 p3 p8 p7 5 pf pb 6 pe pc 7 pd pa 8 1 2 3 4 5 6 7 8 9 a b c d e f This FAUST CLUSTER is minimal, with just 3 pTree calculations. Pick a point (e.g., bottom point- 0 pTree calculations). 1. Find the furthest point (e.g., using ScalarPTreeSet(distance(x,M), 1 pTree calculation) 2. Find gaps (e.g., using ScalarPTreeSet(xofM), ( 1 pTree calculation). split when the gap>GT ( 1 pTree calculation). Continue when there are no gaps (declare C complete) ( 0 pTree calculations). However, we may want a density-based stop condition (or a combination). Even if we don't create the mean, we can get a "radius" (for n-dim volume = rn) from the length of the fM. So with a density SC it's 3 pTree calcs + a 1-count. Note: M=bottom pt is likely better then M=mean, because the point M will then be on one side of the Mean and closer to an edge. Therefore the FM line might be more of a diameter than ith FMean. No gaps so complete 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f M Note on Stop Conditions: "dense" "no gaps, but not vice versa. M M No gaps so complete X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 f M M M M M
FAUST UMF (M=top, F=bottom, FM_affinity_splitting)Initially C=X. • While an incomplete cluster, C, remains find F=top, M=bottom pts. ( 0 pTree calculations). • Split C into C1=PTree(xoFM<FMoFM/2) and C2=C-C1 (uses mdpt(F,M) as in Oblique FAUST ( 1 pTree calculation) • If Ci dense (ct(Ci)/disnFM > DT) declare Ci complete. ( 1 pTree 1-count). Example-2: Interlocking horseshoes with an outlier X x1 x2 p1 8 2 p2 5 2 p3 2 4 p4 3 3 p5 6 2 p6 9 3 p7 9 4 p8 6 4 p9 13 3 pa 15 7 pb 12 5 pc 11 6 pd 10 7 pe 8 6 pf 7 5 1 2 p2 p5 p1 3 p4 p6 p9 4 p3 p8 p7 5 pf pb 6 pe pc 7 pd pa 8 1 2 3 4 5 6 7 8 9 a b c d e f Note: pb is found to be an outlier but isn't. Otherwise the version works. An absolute minimal version with 1pTree calculation (=PT(xoFM<FMoFM/2): Split iff FMoFM/2>Threshold ("large gap" splitting, "no gap" stopping, If density stopping is used, then add a 1-count.). My "best UMF version" choice: Top-to-Furthest_splitting with the pTree gap finder, density stopping. (3 pTree calculations, 1 one-count). Top Research Need: Better pTree "gap finder". It is useful in both FAUST UMF clustering and in FAUST SMM classification. X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 X p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf X p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf X p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf X p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf X p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf X x1 x2 p1 8 2 p2 5 2 p3 2 4 p4 3 3 p5 6 2 p6 9 3 p7 9 4 p8 6 4 p9 13 3 pa 15 7 pb 12 5 pc 11 6 pd 10 7 pe 8 6 pf 7 5 p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf p1 p2 p3 p4 p5 p6 p7 p8 p9 pa pb pc pd pe pf
FAUST UMF density parameter settings effects If DensityThreshold=DT=1.1 then{pa} joins {p7,p8,p9}. If DT=0.5 then also {pf} joins {pb,pc.pd,pe} and {p5} joins {p1,p2,p3,p4}. We call the overall method FAUST CLUSTER because it resembles FAUST CLASSIFY algorithmically and k (# of clusters) is dynamically determined. Improvements? Better stop condition? Is UMF better than UFF? In affinity splitting, what if k over shoots its' optimal value? Add a fusion step each round? As Mark points out, having k too large can be problematic?. The proper definition of outlier or anomaly is a huge question. An outlier or anomaly should be a cluster that is both small and remote. How small? How remote? What combination? Should the definition be global or local? We need to research this (give users options and advice for their use). Md: create F=furthest pt from M, d(F,M) while creating PTreeSet(d(x,M)? Or as a separate procedure, start with P=Dh (h=High Bit Pos.) then recursively Pk<-- P & Dh-k until Pk+1=0. Then back up to Pk and take any of those points as f and that bit pattern is d(f,M). Note that this doesn't necessarily give the furthest pt from M but gives a pt sufficiently far from M. Or use HOBbit dis? Modify to get absolute furthest pt by jumping (when AND gives zero) to Pk+2 and continuing AND from there. (Dh gives a decent f (at furthest HOBbit dis). 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f centriod=mean; h=1; DT= 1.5 gives 4 outliers and 3 non-outlier clusters