Download

1 / 23
230 likes | 330 Views
Http://www.ece.rice.edu/. Arithmetic Acceleration Techniques for Wireless Communication Receivers. Suman Das, Sridhar Rajagopal, Chaitali Sengupta and Joseph R.Cavallaro {suman,sridhar,chaitali,cavallar}@rice.edu Rice University.

E N D
Http://www.ece.rice.edu/ Arithmetic Acceleration Techniques for Wireless Communication Receivers Suman Das, Sridhar Rajagopal, Chaitali Sengupta and Joseph R.Cavallaro {suman,sridhar,chaitali,cavallar}@rice.edu Rice University This work is supported by Nokia, Texas Instruments, Texas Advanced Technology Program and NSF
Objective • Next generation Wireless Base-station • Real-Time Requirements • Multiuser Channel Estimation and Detection • High Complexity Algorithms for Advanced Receiver Structures • Task Decomposition • Potential for parallelism • Application-Specific Design / Single Processor
Outline • Motivation • Real-time Requirements • Joint Estimation and Detection • Task Decomposition • Results • Summary
Motivation • Next Generation Wireless Systems • Higher Data Rates , up to 2 Mbps • Multimedia Capabilities • Multi-rate, QoS • High Complexity in Proposed Algorithms • Pressure on existing hardware • Time, power, size constraints • Acceleration on Hardware Needed
Noise +MAI Base Station Reflected Paths Direct Path User 1 User 2 Wireless Communication Uplink • Asynchronous CDMA System • Multiple Users • Channel Effects • Fading • Multiple paths • Multiple Access Interference
Base-station Receiver Antenna Data Multiuser Detection Decoder Detected Bits Delay Decision Feedback Multiple Users + Demod -ulator Channel Estimation d MU X MU X Pilot b Base-Station Receiver The Physical Layer
Real -Time Requirements • W-CDMA • Transmission done by multiplication of signature waveform (Spreading) • Data Transmission in 10 ms Frames • Multiple Data Rates by Varying Spreading Factors • Detection needs to be done in real-time • 1953 cycles available in a C6x DSP at 250MHz to detect 1 bit at 128 Kbps
Joint Estimation and Detection • Algorithm to jointly estimate the channel response and detect all the user’s bits. • Shown to have better performance as well as reduced computational complexity. • Maximum Likelihood Based Channel Estimation • [C.Sengupta et al. : PIMRC’1998 WCNC’1999] • Differencing Multistage Detection based on Parallel Interference Cancellation • [G.Xu et al. : SPIE’1999]
time bi-1 bi ri Computations Involved delay • Model • Compute Correlation Matrices Bits of K async. users aligned at times I and I-1 Received bits of spreading length N for K users
Multishot Detection Solve for the channel estimate, Ai Multishot Detection
Differencing Multistage Detection • Stage 0 • Stage 1 • Successive Stages S=diag(AHA) y - soft decision d - detected bits (hard decision)
Structure of AHA Block Bi-Diagonal Matrix
Bottlenecks • Identify using C6x DSP Implementation • Channel Estimation • Can be done less frequently • Depends on BER needed • Multiuser Detection • Needs to be done all the time • Differencing Multistage • Less computations on successive stages • Analysis on Various levels of Optimization for Detection
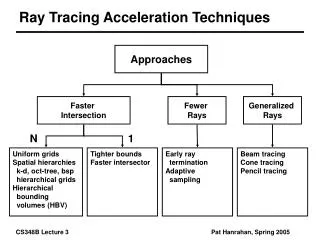
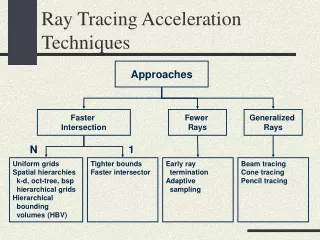
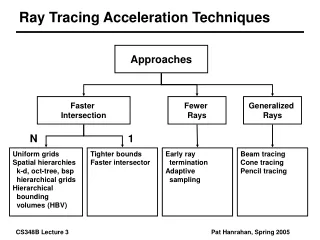
Task Decomposition Block I Block III Block II Task B Correlation Matrices (Per Bit) Inverse Matrix Products Block IV M UX d A0HA1 O(K2N) Multistage Detection (Per Window) RbbAH = Rbr[R] O(K2N) Rbr[R] O(KN) b A0HA0 O(K2N) Rbr[I] O(KN) M UX Data’ RbbAH = Rbr[I] O(K2N) d O(DK2Me) Rbb O(K2) A1HA1 O(K2N) Pilot AHr O(KND) Data Multistage Detection Channel Estimation Task A
Sequential / Pipeline A B Task A Block IV d AHr O(KND) O(DK2Me) Data Real-time 1953 cycles,128 Kbps Task B 13272 cycles 3367*Me cycles (Single PE) Sequential : A+B: 13272 + 3367*Me : 10.7 Kbps (2 PE) Pipeline : A B : max(13272, 3367*Me) : 18.8 Kbps *Me =3
(Parallel A) B Block IV Task A AHr O(ND) 1 O(DK2Me) Data d K Task B Real-time 1953 cycles,128 Kbps 3367*Me cycles 885 cycles (K+1 PE) Parallel A B : 3367*Me : 24.75 Kbps
Parallel A Pipeline B Parallel A Parallel + Pipeline B Task A 1 K Task B Real-time 1953 cycles,128 Kbps 885 cycles O(N) 3367 cycles O(K2) 225 cycles O(K) (K +3 PE) Parallel A Pipeline B : 3367 : 74.25 Kbps ((Me+1)K PE) Parallel A Parallel + Pipeline B : 885 : 282.5 Kbps
At this step Multistage Detection Block I &II 1 Data K Task A Stage 1 Stage2 Stage3… Block IV Block III Task B
5 x 10 Data Rates for Different Levels of Pipelining and Parallelism 3 2.5 (Parallel A) (Parallel+Pipe B) (Parallel A) (Pipe B) (Parallel A) B 2 A B Sequential A + B Data Rates 1.5 Data Rate Requirement = 128 Kbps 1 0.5 0 9 10 11 12 13 14 15 Number of Users Achieved Data Rates
Mapping to Hardware • Analysis independent of hardware • DSP with coprocessors • Multiple Processors • Combination of a processor with ASIC/FPGA • Single ASIC • Minimize Idle time in processing elements • Some computations can be shared • Assumptions • Critical processing elements have functional units similar to C6x • No communication overhead between processors • Number of elements dependent on number of users
Summary • Acceleration Techniques for Multiuser Estimation and Detection : computationally intensive algorithm • Task Decomposition • C6x DSP Simulator • Real-time Analysis • Hardware Mapping Issues • Application Specific Design more effective than a single processor solution
Future Work • Fixed Point Implementation • LU Decomposition • Other Algorithms for decomposition • Matrix Oriented Architectures • Vector Processor with SIMD • 2 Levels of Parallelism • Complex Arithmetic
DSP Implementation • Texas Instruments C6x Simulator • TI TMS320C6701 Floating Point DSP • Code and Program optimized to fit in internal memory • 32 -bit VLIW Architecture • 8 Functional Units • 2 Multipliers • 4 Adders • 2 Load/Store • TI C Compiler