Download

1 / 27
270 likes | 394 Views
Padmini Srinivasan Computer Science Department Department of Management Sciences http:// cs.uiowa.edu / ~ psriniva padmini-srinivasan@uiowa.edu. Crawlers. Basics. What is a crawler? HTTP client software that sends out an HTTP request for a page and reads a resppnse . Timeouts

E N D
Padmini Srinivasan Computer Science Department Department of Management Sciences http://cs.uiowa.edu/~psriniva padmini-srinivasan@uiowa.edu Crawlers
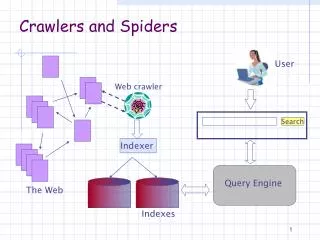
Basics • What is a crawler? • HTTP client software that sends out an HTTP request for a page and reads a resppnse. • Timeouts • How much to download? • Exception handling • Error handling • Collect statistics: time-outs, etc. • Follows Robot Exclusion Protocol (de facto, 1994 onwards)
Tippie web site • # robots.txt for http://www.tippie.uiowa.edu/ or http://tippie.uiowa.edu/ • # Rules for all robots accessing the site. • User-agent: * • Disallow: /error-pages/ • Disallow: /includes/ • Disallow: /Redirects/ • Disallow: /scripts/ • Disallow: /CFIDE/ • # Individual folders that should not be indexed • Disallow: /vaughan/Board/ • Disallow: /economics/mwieg/ • Disallow: /economics/midwesttheory/ • Disallow: /undergraduate/scholars/ • Sitemap: http://tippie.uiowa.edu/sitemap.xml
Robots.txt User-agent: * Disallow: User-agent: BadBot Disallow: / User-agent: Google Disallow: User-agent: * Disallow: / <html> <head> <meta name="googlebot" content="noindex"> http://www.robotstxt.org/ Legal? No. But has been used in legal cases.
Types of crawlers • Get everything? • Broad….. • Get everything within on a topic? • Preferential, topical, focused, thematic • What are your objectives behind the crawl? • Keep it fresh • When does one run it? Get new versus check old? • How does one evaluate performance? • Sometimes? Continuously? What’s the Gold Standard?
Crawler Parts • Frontier • List of “to be visited” URLS • FIFO (first in first out) • Priority queue (preferential) • When the Frontier is full • Does this happen? What to do? • When the Frontier is empty • Does this happen? • 10,000 pages crawled, average 7 links / page: 60,000 URLS in the frontier, how so? • Unique URLS?
Crawler Parts • History • Time-stamped listing of visited URLS – take out of frontier first • Can keep other information too: quality estimate, update frequency, rate of errors (in accessing page), last update date, anything you want to track related to the fetching of the page. • Fast lookup • Hashing scheme on the URL itself • Canonicalize: • Lowercasing; • remove anchor reference parts: • http://www……./faq.html#time • http://www……./faq.html • Remove tildas • Add or subtract trailing / • Remove default pages: index.html • Normalize paths: removing parent pointers in url • http://www…./data/../mydata.html • Normalize port numbers: default numbers (80) • Spider traps: long URLS, limit length.
Crawler Parts • Page Repository • Keep all of it? Some of it? Just the anchor texts? • You decide • Parse the web page • Index and store information (if creating a search engine of some kind) • What to index? How to index? How to store? • Stopwords, stemming, phrases, Tag tree evidence (DOM), • NOISE! • Extract URLS • Google initially: show you next time.
And… • But why do crawlers actually work? • Topical locality hypothesis • An on topic page tends to link to other on topic pages. • Empirical test : that two pages that are topically similar have higher probability of linking to each other than two random pages on the web. (Davison, 2000) • And too browsing works! • Status locality? • high status web pages are more likely to link to other high status pages than to low status pages • Rationale from social theories: relationship asymmetry in social groups and the spontaneous development of social hierarchies.
Crawler Algorithms • Naïve best-first crawler • Best-N-first crawler • SharkSearch crawler • FishSearch • Focused crawler • Context Focused crawler • InfoSpiders • Utility-biased web crawlers
Naïve Best First Crawler • Compute cosine between page and query/description as URL score • Term frequency (TF) and Inverse Document Frequency (IDF) weights • Multi-threaded: Best-N-crawler (256)
Naïve best-first crawler • Bayesian classifier to score URLS Chakrabartiet al. 1999 • SVM (Pant and Srinivasan, 2005) better. Naïve Bayes tends to produce skewed scores. • Use PageRank to score URLS? • How to compute? Partial data. Based on crawled data – poor results • Later: utility-biased crawler
Shark Search Crawler • From earlier Fish Search (de Bra et al.) • Depth bound; anchor text; link context; inherited scores score(u) = g * inherited(u) + (1 – g) * neighbourhood (u) inherited(u) = x * sim(p, q) if sim(p, q) > 0 else inherited(p) (x < 1). neighbourhood(u) = b * anchor(u) + (1-b) * context(u) (b < 1) context(u) = 1 if anchor(u) > 0 else sim(aug_context, q) Depth: controls travel in a sub space; no more ‘relevant’ information found.
Focused Crawler • Chakrabarti et al. Stanford/IIT • Topic taxonomy • User provided sample URLs • Classify these onto the taxonomy • (Prob(c|url) where Prob(root|url) = 1. • User iterates selecting and deselecting categories • Mark the ‘good’ categories • When page crawled: relevance(page) = sum(Prob(c|page)) where sum is over the good categories; score URLS • When crawling: • Soft mode: use this relevance score to rank URLS • Hard mode: find leaf node with highest score, if any ancestor marked relevant then add to frontier else not
Context Focused Crawler • A rather different strategy • Topic locality hypothesis somewhat explicitly used here • Classifiers estimate distance to relevant page from a crawled page. This estimate scores urls.
Context Graph Levels: L Probability (page in class, i.e., level x) x = 1, 2, 3 (other) Bayes theorem: Prob(L1|page) = {Prob(page|L1) * Prob(L1)}/Prob(page) Prob(L1) = 1/L (number of levels)
Utility-Biased Crawler • Considers both topical and status locality. • Estimates status via local properties • Combines using several functions. • One: Cobb-Douglas function • Utility(URL) = topicalitya * statusb (a + b = 1) • if a page is twice as high in topicality and twice as high in status then twice as high utility as well. • Increases in topicality (or status) cause smaller increases in utility as the topicality (or status) increases.
Estimating Status ~ cool part • Local properties • M5’ decision tree algorithm • Information volume • Information location • http://www.somedomain.com/products/news/daily.html • Information specificity • Information brokerage • Link ratio: # links/ # words • Quantitative ratio: # numbers/# words • Domain traffic: ‘reach’ data for domain obtained from Alexa Web Information Service • Pant & Srinivasan, 2010, ISR
Utility-Biased Crawler • Cobb-Douglas function • Utility(URL) = topicalitya * statusb (a + b = 1) • Should a be fixed? “one size fits all” Or should it vary based on the subspace? • Target topicality level (d) • a = a + delta (d – t), 0 <= a <= 1 • t: average estimated topicality of the last 25 pages fetched • Delta is a step size (0.01) • Assume a = 0.7, delta = 0.01 and t = 0.9 • a = 0.7 + 0.01(0.7 – 0.9) = 0.7 – 0.002 • Assume a = 0.7, delta = 0.01 and t = 0.4 • a = 0.7 + 0.01(0.7 – 0.4) = 0.7 + 0.003
Crawler Evaluation • What are good pages? • Web scale is daunting • User based crawls are short, but web agents? • Page importance assessed • Presence of query keywords • Similarity of page to query/description • Similarity to seed pages (held out sample) • Use a classifier – not the same as used in crawler • Link-based popularity (but within topic?)
Summarizing Performance • Precision • Relevance is Boolean: yes/no • Harvest rate: # of good pages/total # pages • Relevance is continuous • Average relevance over crawled set • Recall • Target recall: held out seed pages (H) • |H ∧ pages crawled|/|pages crawled| • Robustness • Start same crawler on disjoint seed sets. Examine overlap of fetched pages
Summary • Crawler architecture • Crawler algorithms • Crawler evaluation • Assignment 1 • Run two crawlers for 5000 pages. • Start with the same set of seed pages for a topic. • Look at overlap and report this over time (robustness)