Beaconstac Analytics
110 likes | 308 Views
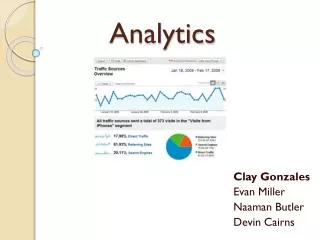
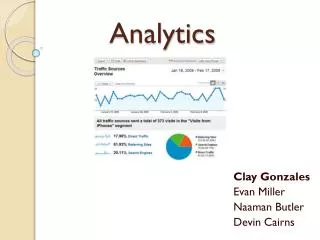
Beaconstac is a proximity marketing and analytics platform for beacons<br>Several beacon specific events are defined to aid proximity marketing<br>The events include Camp on event, beacon exit event, region enter, region exit etc.Beaconstac analytics platform makes it easy for managers/marketers/developers to analyze event data.

Beaconstac Analytics
E N D
Presentation Transcript
Project Morpheus (Beaconstac Analytics) May 2015 Garima Batra Core Platform Engineer | MobStac
A quick intro about Beaconstac 1 • Beaconstac is a proximity marketing and analytics platform for beacons • Several beacon specific events are defined to aid proximity marketing • The events include Camp on event, beacon exit event, region enter, region exit etc. • Beaconstac analytics platform makes it easy for managers/marketers/developers to analyze event data • Components include Beaconstac iOS/Android sdk, beaconstac portal
Why Hadoop? 1 • Collect event logs generated from Beaconstac SDK usage • Needed a system to answer queries like • Heat map of beacons by the number of visits received in a specified time interval. • Heat map of beacons by the amount of time spent in a specified time interval. • Average time spent by users near different beacons • Last seen per user • Last seen per beacon • Analyzing data with custom attributes filters • Traversed path in an area by individual users
Leveraging Amazon's EMR for Beaconstac Analytics 1 • Amazon's Streaming API for writing mapper and reducer functions in Python • Input - Copy programs to Amazon S3 • Output – Copy the processed/output data to S3 • Initial tests were run using Amazon's EMR console. Here you can define the following - • Cluster configuration – Name, Termination protection, Logging, logs location on S3 etc. • Software configuration – Hadoop AMI version, applications to be installed on startup etc. • Hardware configuration – Types of nodes – master, Core and Task • Security keys, allowed users • Bootstrap actions – Configure Hadoop, Custom actions etc. • Steps – Streaming program, Hive program, Pig program
Batch processing for Morpheus 1 AWS Data pipeline
How Does AWS Data Pipeline Work? 1 • Pipeline definition - specifies the business logic of your data management • AWS Data pipeline web service - interprets the pipeline definition and assigns tasks to workers to move and transform data. • Task runner - polls the AWS Data Pipeline web service for tasks and then performs those tasks.
Morpheus version of Data pipeline 1 Copy the output to Elastic Search Copy logs from Kafka to S3 Run EMR jobs • Runs once every day • Inserts output in Elastic search • Runs every hour • Requires a Kafka consumer script • Runs once every day • Processes each job and produces output • Each job comprises of mapper and reducer scripts
Settings file in each job 1 1 Questions?? Source: Lorem Ipsum