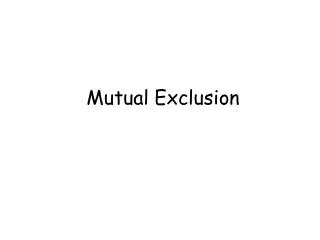Download

1 / 8
90 likes | 248 Views
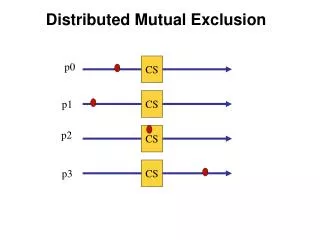
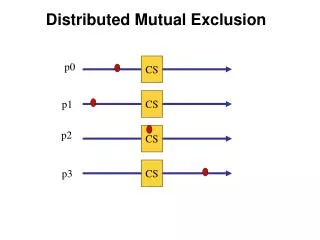
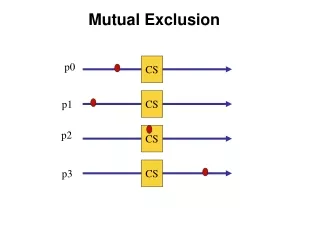
Mutual Exclusion. System involving multiple processes are often most easily programmed using critical regions.

E N D
Mutual Exclusion • System involving multiple processes are often most easily programmed using critical regions. • When a process has to read or update certain shared data structures, it first enters a critical region to achieve mutual exclusion and ensure that no more than one process can use the shared data structure at the same time. • In single-processor system, critical regions are protected using semaphores, monitors, and similar constructs. • In a distributed systems, mutual exclusion can be enforced by the following methods: • A Centralized Algorithm • A Distributed Algorithm • A Token Ring Algorithm • We will study each of these algorithms and do a comparison among them.
A Centralized Algorithm • One process is elected to be the co-ordinator -- For example, the process that bears with the highest network address. • When a process wants to enter a critical region, it sends a request message to the co-ordinator stating which critical region it wants to enter. • If no other process is currently in that CR, the co-ordinator sends back a reply granting the permission. When the reply arrives, the requesting process enters the CR. • If some other process is already inside the CR, the co-ordinator will queue the request and either send a “permission denied” message back or no reply at all. • When a process exits the CR, it sends a message to the co-ordinator releasing its exclusive access. • The co-ordinator will then takes the first item off the queue of deferred requests and sends that process a grant message. If the process is still blocked, it enters the CR. If an “denied” message has been sent, the process will have to poll for incoming traffic. Either way, upon receiving the grant, it enters the CR. • Advantages: Fair & no starvation (FIFO), and only 3 msg type -- request, grant, release. • Disadvantages: single point of failure, cannot distinguish a dead co-ordinator from a “denied” situation, and the single co-ordinator becomes the performance bottleneck.
A Distributed Algorithm • Ricart & Agrawala’s algorithm requires that there be a total ordering of all events in the system. That is for any pairs of events, such as messages, it must be unambiguous which one happened first. • When a process wants to enter a CR, it builds a message by the name of the CR, its pid, and the current time, and sends the message to all other processes including itself. • When a process receives a request message from another process, one of the three cases are identified: • 1. If the receiver is not in the CR and does not want to enter it, it send back an OK message to the sender; • 2. If the receiver is already in the CR, it does not reply, but it queue the request. • 3. If the receiver wants to enter the CR but has not yet done so, it compares the timestamp it receives with its own message, and the lower one wins. That is, if the incoming is lower, the receiver send an OK to the sender. Otherwise, the receiver queue the request and sends nothing. • After sending the requests, a process sit back and waits until everyone has answered. • As soon as the permissions are in, it enters the CR. When it exits the CR, it sends OK messages to all processes on its queue and deletes them all from the queue.
A Distributed Algorithm -- how it works • Process 0sends everyone a request with timestamp 8, while process 2 sends a request with timestamp 12. • Process 1 is not interested in entering the CR, so it sends OK to both process 0 & 2. • Process 0 & 2 both see the conflict and compare the timestamp, Process 2 sees that it has lost, so it grants permission to 0 by sending process 0 an OK. • Process 0 queue the request from Process 2 and enter the CR. When it finishes, it removes the request from Process 2 from its queue and send an OK to Process 2, allowing Process 2 to enter the CR. • The algorithm works because in the case a conflict, the lowest timestamp wins and everyone agrees on the ordering of the timestamps. 8 enter CR 0 0 0 12 OK 8 8 OK OK 1 2 12 1 2 1 2 enter CR 12 OK
A Distributed Algorithm -- Problems • As with the centralized algorithm, mutual exclusion is guaranteed without deadlock or starvation, and no single point of failure. • The number of messages required per entry is now 2 * (n-1). • The single point of failure is replaced by a n points of failure. If any process crashes, it will fail to respond to requests. • Since the probability of one of the n processes failing is n times as large as a single co-ordinator failing, we have a poor algorithm replaced by one that is n times worse and require more network traffic to boot. • All processes are involved in all decisions concerning entry into a CR. If one process is unable to handle the load, it is unlikely that forcing everyone to do exactly the same thing in parallel is going to help much. • Minor improvement: modified to allow a process to get into a CR by collecting a simple majority permissions. • Anyway, the algorithm is allowed, more complicated, more expensive, and less robust than the original centralized algorithm. However, it stimulates the development of distributed algorithms that are actually useful.
A Token Ring Algorithm • A logical ring is constructed over a bus network in which each process is assigned a position in the ring. So a process knows who is next in line. • When the ring is initialized, Process 0 is given a token. The token circulates around the ring, passes from process to process in point-to-point messages. • Only when a process have the token, then it can enter a CR. When it exits, it passes the token to the next in line -- a process cannot enter a second CR by the same token. • If token arrived and the process is not going to enter a CR, it passes the token to the next process. Hence, if no process is entering a CR, the token keep on circulating in the ring. • Once a process decides to enter a CR, at worst it will have to wait for every other process to enter and leave one CR. • Problems: • If the token is lost, it must be re-generated. • Detecting the lost of a token is difficult because the amount of time between successive appearances of the token is unbounded. • If a process crashes, the ring configuration must be maintained.
A Comparison of the 3 Algorithms Algorithms Msg/Entry Delay B4 Entry Problems Centralized 3 2 Crash of Co-ordinator Distributed 2 (n - 1) 2 (n - 1) Crash of any process Token Ring 1 to infinity 0 to (n - 1) Lost token, process crash • Many distributed algorithms requires a co-ordinator. In the following section, we will look at algorithms for electing a co-ordinator. • We assume that each process has a unique number, for example, its network address. In general, election algorithms attempt to locate the process with the highest process number and designate it as the co-ordinator. • The goal of an election algorithm is to ensure that when election starts, it concludes with all processes agreeing on who the new co-ordinator is to be. Election Algorithms
The Bully Algorithm • When any process notices that the co-ordinator is no longer responding to requests, it initiates an election. A process, P, holds an election as follows: • 1. P sends an ELECTION message to all processes with higher numbers. • 2. If no one responds, P wins the election and becomes the co-ordinator. • 3. If one of the higher-ups answers, it takes over. P’s job is done. • At any time, a process can get an ELECTION message from one of its lower-numbered colleagues. When such message arrives, the receiver sends an OK message back to the sender to indicate that he is alive and will take over. • Eventually, all processes give up but one, and that becomes the co-ordinator. • It announces its victory by sending all processes a message telling them that starting immediately it is the new co-ordinator. • If a process that was previously down comes back up, it holds an election. • If it happens to be the highest-numbered process running, it will win the election and take over the co-ordinator’s job. Otherwise, the biggest guy in the system always wins, hence the name “bully algorithm”.