Download
1 / 22
220 likes | 295 Views
Identification of common protein motifs through the application of machine learning. Scott Hollingsworth (Department of Biochemistry & Biophysics, Oregon State University) Mentor: Dr. P. Andrew Karplus (Department Of Biochemistry & Biophysics, OSU)

E N D
Identification of common protein motifs through the application of machine learning Scott Hollingsworth (Department of Biochemistry & Biophysics, Oregon State University) Mentor: Dr. P. Andrew Karplus (Department Of Biochemistry & Biophysics, OSU) In Collaboration With: Dr. Weng-Keen Wong (Department Of Computer Science, OSU) Dr. Donald Berkholz (Department of Biochemistry and Molecular Biology, Mayo Clinic) Dr. Dale Tronrud (Department of Biochemistry & Biophysics, OSU)
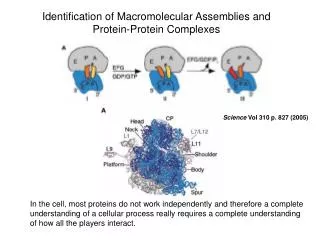
Background • Each protein has an individual structure • Structure flows from function • Understand structure, understand function Ptr Tox A
Protein Structure • Phi & Psi (φ, ψ) • Phi and psi describe the conformation of the planar peptide (amino acid) in regards to other peptides • One amino acid – two angles φ ψ Ramachandran Plot Voet, Voet & Pratt Biochemistry (Upcoming 4th Edition)
Previous Work 310 Helix • Use of Protein Geometry Database (PGD) to identify linear group existence (i.e. α-helix, β-sheet, π-helix…) • Simple repeating structures • Methods: manual searches • Hollingsworth et al. 2009. “On the occurrence of linear groups in proteins.” Protein Sci. 18:1321-25 α-Helix
Project Basis • Linear groups are only part of the picture • Not all common protein motifs are repeating structures • Many have changing conformations • Goal of this research: • Identify all common motifs in proteins • Too complex for manual searches • Enter machine learning
Machine Learning • Form of artificial intelligence • Can identify clusters within a dataset • Cluster – significant grouping of data points • Visual example…
Topographical map of Oregon Data value: Elevation Mt. Hood (11,239 Feet) Mt. Jefferson (10,497 Feet) Three Sisters (10,358-10,047 Feet) Highest points (Individual peaks)
Topographical map of Oregon Data value: Elevation Highest points (Individual peaks)
Topographical map of Oregon Data value: Elevation T U A L A T I N H I L L S W A L L O W A S B L U E M T S C O A S T R A N G E O C H O C O C A S C A D E S S T R A W B E R R I E S P A U L I N A M T S M A H O G A N Y M T S J A C K A S S M T S S T E E N S S I S K I Y O U S ( K A L A M A T H ) H A R T M T N T R O U T C R E E K M T S Mountain ranges (Broad patterns)
φ ψ Similar approach with our data 2-Dimensional Example
α-helix β PII Abundance αL φ ψ Similar approach with our data 2-Dimensional Example
Similar approach… • Complications… • Our Data: 4-dimensional dataset • 4D to 2D distance conversions • What has and hasn’t been observed? • No definitive source • Abundance / Peak Heights
Hypothesis • Machine learning programs can identify both previously documented and unknown common motifs and their abundances
Methods • 1) Create and prep datasets with resolution of at least 1.2Å or higher, 1.75Å or higher • 2) Run cuevas • 3) Analyze identified clusters • Automated process using Python to remove bias • 4) Analyze context of motifs 2D-visual example of cuevas clustering
Results: Everest • “Everest” Method • Locate “highest” peak first • Bad pun : “Mt. Alpha-rest” • Locate second highest peak • Locate third……. • Goal: Definitive list of the most common protein motifs • In order of abundance
Results: Everest I - Identification • Results: • Definitive list of common protein motifs in order of abundance • The list… • Identifying motifs • Search for peaks while looking for ranges
Results: Everest II - Analysis • Results: • New insight into each motif’s structure • Context • Comparisons • Motif “shapes” • Each motif analyzed by plotting of each motif range • Understand the shape of the cluster/motif
Example Cluster Shape Type II Vs. Type II` Type II Vs. Type II` Hairpin turns 180° Turn Two Residues Defined as mirror images of each other Distributions show differences between the two structures Nearly four years in the making… φ ψ
Results • The results go on… • Motif analysis • Viral forming of “Pangea” • Range and peak method sections • Adapting cuevas for our data • Python automation • Identification of 310 Helix & Type I Turn • 6D, 8D, 10D and 12D clustering • Full helix caps, loops, halfturns… • For full story, a manuscript for publication is being prepared: • Hollingsworth et al. “The protein parts list: motif identification through the application of machine learning.”(Unpublished)
Conclusions • Cuevas was successful in identifying both documented and undocumented motifs • Previously described: Linear groups, helix caps, β-turns (& reverses), β-bulges, α-turns, loops, helix bends, π-structures… • Numerous new motifs • Successful from 4D through 20D • Results form the “Protein Parts” List • Comprehensive list of all common protein motifs found in proteins
Acknowledgments • Dr. P. Andrew Karplus • Dr. Weng-Keen Wong • Dr. Donald Berkholz • Dr. Dale Tronrud • Dr. Kevin Ahern • Howard Hughes Medical Institute