Download

1 / 87
910 likes | 1.1k Views
Parallel Architectures. Martino Ruggiero martino.ruggiero@unibo.it. Why Multicores ?. The SPECint performance of the hottest chip grew by 52% per year from 1986 to 2002 , and then grew only 20% in the next three years (about 6% per year ). [from Patterson & Hennessy].

E N D
Parallel Architectures Martino Ruggiero martino.ruggiero@unibo.it
WhyMulticores? The SPECintperformance of the hottest chip grew by 52% per year from 1986 to 2002, and then grew only 20% in the next three years (about 6% per year). [from Patterson & Hennessy] Diminishingreturns from uniprocessordesigns
PowerWall [from Patterson & Hennessy] • The design goal for the late 1990’s and early 2000’s was to drive the clock rate up. • This was done by adding more transistors to a smaller chip. • Unfortunately, this increased the power dissipation of the CPU chip beyond the capacity of inexpensive cooling techniques
Roadmap for CPU Clock Speed: Circa 2005 [from Patterson & Hennessy] Here is the result of the best thought in 2005. By 2015, the clock speed of the top “hot chip” would be in the 12 – 15 GHz range.
The CPU Clock Speed Roadmap (A Few Revisions Later) [from Patterson & Hennessy] This reflects the practical experience gained with dense chips that were literally “hot”; they radiated considerable thermal power and were difficult to cool. Law of Physics: All electrical power consumed is eventually radiated as heat.
The MultiCore Approach Multiple cores on the same chip • Simpler • Slower • Less power demanding
The Memory Gap [from Patterson & Hennessy] • Bottom-line: memory access is increasingly expensive and computer architect must devise new ways of hiding this cost
Transition to Multicore Sequential App Performance Spring 2011 -- Lecture #15
Parallel Architectures • Definition: “A parallel architecture is a collection of processing elements that cooperate and communicate to solve large problems fast” • Questions about parallel architectures: • How many are the processing elements? • How powerful are processing elements? • How do they cooperate and communicate? • How are data transmitted? • What type of interconnection? • What are HW and SW primitives for programmer? • Does it translate into performance?
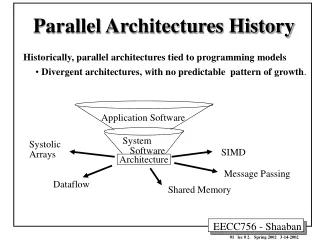
Flynn Taxonomy of parallel computers M.J. Flynn, "Very High-Speed Computers", Proc. of the IEEE, V 54, 1900-1909, Dec. 1966. • Flynn's Taxonomy provides a simple, but very broad, classification of computer architectures: • Single Instruction, Single Data (SISD) • A single processor with a single instruction stream, operating sequentially on a single data stream. • Single Instruction, Multiple Data (SIMD) • A single instruction stream is broadcast to every processor, all processors execute the same instructions in lock-step on their own local data stream. • Multiple Instruction, Multiple Data (MIMD) • Each processor can independently execute its own instruction stream on its own local data stream. • SISD machines are the traditional single-processor, sequential computers - also known as Von Neumann architecture, as opposed to “non-Von" parallel computers. • SIMD machines are synchronous, with more fine-grained parallelism - they run a large number parallel processes, one for each data element in a parallel vector or array. • MIMD machines are asynchronous, with more coarse-grained parallelism - they run a smaller number of parallel processes, one for each processor, operating on the large chunks of data local to each processor.
Single Instruction/Single Data Stream:SISD • Sequential computer • No parallelism in either the instruction or data streams • Examples of SISD architecture are traditional uniprocessor machines Processing Unit
Multiple Instruction/Single Data Stream:MISD • Computer that exploits multiple instruction streams against a single data stream for data operations that can be naturally parallelized • For example, certain kinds of array processors • No longer commonly encountered, mainly of historical interest only
Single Instruction/Multiple Data Stream:SIMD • Computer that exploits multiple data streams against a single instruction stream to operations that may be naturally parallelized • e.g., SIMD instruction extensions or Graphics Processing Unit (GPU) • Single control unit • Multiple datapaths (processing elements – PEs) running in parallel • PEs are interconnected and exchange/share data as directed by the control unit • Each PE performs the same operation on its own local data
Multiple Instruction/Multiple Data Streams:MIMD • Multiple autonomous processors simultaneously executing different instructions on different data. • MIMD architectures include multicore and Warehouse Scale Computers (datacenters)
Centrilizedmemory Physically distributed memory Pro- Pro- Pro- Pro- ... ... cessor cessor cessor cessor Shared address space Interconnection Local Memory Local Memory Shared Memory Interconnection NUMA (Non-Uniform Memory Access) distributed-shared-memory multiprocessor UMA (Uniform Memory Access) (SMP) symmetric multiprocessor Pro- Pro- ... cessor cessor empty Private address spaces Local Memory Local Memory receive send Interconnection MPP (Massively Parallel Processors) message-passing (shared-nothing) multiprocessor Parallel Computing Architectures Memory Model Parallel Architecture = Computer Architecture + Communication Architecture • Question: how do we organize and distribute memory in a multicore architecture? • 2 classes of multiprocessors WRT memory: • Centralized Memory Multiprocessor • Physically Distributed-Memory multiprocessor • 2 classes of multiprocessors WRT addressing: • Shared • Private
Memory Performance Metrics • Latencyis the overhead in setting up a connection between processors for passing data. • This is the most crucial problem for all parallel architectures - obtaining good performance over a range of applications depends critically on low latency for accessing remote data. • Bandwidthis the amount of data per unit time that can be passed between processors. • This needs to be large enough to support efficient passing of large amounts of data between processors, as well as collective communications, and I/O for large data sets. • Scalabilityis how well latency and bandwidth scale with the addition of more processors. • This is usually only a problem for architectures with manycores.
Distributed Shared Memory Architecture:NUMA • Data set is distributed among processors: • each processor accesses only its own data from local memory • if data from another section of memory (i.e. another processor) is required, it is obtained by a remote access. • Much larger latency for accessing non-local data, but can scale to large numbers (thousands) of processors for many applications. • Advantage:Scalability • Disadvantage:Locality Problems and Connection congestion • Aggregated memory of the whole system appear as one single address space. Communication Network P Processor M Local Memory Host Processor P 1 P 2 P 3 M 1 M 2 M 3
Interconnect Network NI NI NI NI NI NI NI NI P P P P P P P P Mem Mem Mem Mem Mem Mem Mem Mem Distributed Memory—Message Passing Architectures • Each processor is connected to exclusive local memory • i.e. no other CPU has direct access to it • Each node comprises at least one network interface (NI) that mediates the connection to a communication network. • On each CPU runs a serial process that can communicate with other processes on other CPUs by means of the network. • Non-blocking vs. Blocking communication • MPI Problems: • All data layout must be handled by software • Message passing has high software overhead
Pro- cessor Pro- cessor Pro- cessor Pro- cessor Primary Cache Primary Cache Primary Cache Primary Cache Secondary Cache Secondary Cache Secondary Cache Secondary Cache Bus Global Memory Shared Memory Architecture: UMA • Each processor has access to all the memory, through a shared memory bus and/or communication network • Memory bandwidth and latency are the same for all processors and all memory locations. • Lower latency for accessing non-local data, but difficult to scale to large numbers of processors, usually used for small numbers (order 100 or less) of processors.
Pro- cessor Pro- cessor Pro- cessor Pro- cessor Primary Cache Pro- cessor Pro- cessor Pro- cessor Pro- cessor Pro- cessor Pro- cessor Pro- cessor Pro- cessor Primary Cache Primary Cache Primary Cache Primary Cache Primary Cache Primary Cache Primary Cache Primary Cache Secondary Cache Secondary Cache Secondary Cache Secondary Cache Secondary Cache Secondary Cache Global Memory Global Memory Global Memory Shared memory candidates Shared-main memory Shared-primary cache Shared-secondary cache • Caches are used to reduce latency and to lower bus traffic • Must provide hardware to ensure that caches and memory are consistent (cache coherency) • Must provide a hardware mechanism to support process synchronization
Challenge of Parallel Processing • Two biggest performance challenges in using multiprocessors • Insufficient parallelism • The problem of inadequate application parallelism must be attacked primarily in software with new algorithms that can have better parallel performance. • Long-latency remote communication • Reducing the impact of long remote latency can be attacked both by the architecture and by the programmer.
Exec time w/o E Speedup w/ E = ---------------------- Exec time w/ E Amdahl’s Law • Speedup due to enhancement E is • Suppose that enhancement E accelerates a fraction F (F <1) of the task by a factor S (S>1) and the remainder of the task is unaffected Execution Time w/o E [ (1-F) + F/S] Execution Time w/ E = 1 / [ (1-F) + F/S ] Speedup w/ E =
Amdahl’s Law Speedup = Example: the execution time of half of the program can be accelerated by a factor of 2.What is the program speed-up overall?
Amdahl’s Law Speedup = 1 Example: the execution time of half of the program can be accelerated by a factor of 2.What is the program speed-up overall? (1 - F) + F S Non-speed-up part Speed-up part 1 1 = = 1.33 0.5 + 0.5 0.5 + 0.25 2
Amdahl’s Law If the portion ofthe program thatcan be parallelizedis small, then thespeedup is limited The non-parallelportion limitsthe performance
Strong and Weak Scaling • To get good speedup on a multiprocessor while keeping the problem size fixed is harder than getting good speedup by increasing the size of the problem. • Strong scaling: when speedup can be achieved on a parallel processor without increasing the size of the problem • Weak scaling: when speedup is achieved on a parallel processor by increasing the size of the problem proportionally to the increase in the number of processors Needed to amortizesources of OVERHEAD (additional code, notpresent in the originalsequentialprogram, needed to execute the program in parallel)
Pro- cessor Pro- cessor Pro- cessor Pro- cessor Primary Cache Primary Cache Primary Cache Primary Cache Secondary Cache Secondary Cache Secondary Cache Secondary Cache Bus Global Memory Symmetric Shared-Memory Architectures Symmetric shared-memory machines usually support the caching of both shared and private data. Private data are used by a single processor, while shared data are used by multiple processors. When a private item is cached, its location is migrated to the cache, reducing the average access time as well as the memory bandwidth required. Since no other processor uses the data, the program behavior is identical to that in a uniprocessor. When shared data are cached, the shared value may be replicated in multiple caches. In addition, This replication also provides a reduction in contention that may exist for shared data items that are being read by multiple processors simultaneously. Caching of shared data, however, introduces a new problem : cache coherence
u = ? u = ? u = 7 5 4 3 1 2 u u u :5 :5 :5 Example Cache Coherence Problem P P P • Cores see different values for u after event 3 • With write back caches, value written back to memory depends on the order of which cache flushes or writes back value • Unacceptable for programming, and it is frequent! 2 1 3 $ $ $ I/O devices Memory
Keeping Multiple Caches Coherent • Architect’s job: shared memory => keep cache values coherent • Idea: When any processor has cache miss or writes, notify other processors via interconnection network • If only reading, many processors can have copies • If a processor writes, invalidate all other copies • Shared written result can “ping-pong” between caches
Shared Memory Multiprocessor Memory Bus Snoopy Cache M1 Physical Memory Snoopy Cache M2 DMA Snoopy Cache DISKS M3 Use snoopy mechanism to keep all processors’ view of memory coherent
u = ? u = ? u = 7 5 4 3 1 2 u u u :5 :5 :5 u = 7 Example: Write-thru Invalidate P P P • Must invalidate before step 3 • Write update uses more broadcast medium BW all recent SMP multicores use write invalidate 2 1 3 $ $ $ I/O devices Memory
Need for a more scalable protocol • Snoopy schemes do not scale because they rely on broadcast • Hierarchical snoopy schemes have the root as a bottleneck • Directorybased schemes allow scaling • They avoid broadcasts by keeping track of all CPUs caching a memory block, and then using point-to-point messages to maintain coherence • They allow the flexibility to use any scalable point-to-point network
Scalable Approach: Directories • Every memory block has associated directory information • keeps track of copies of cached blocks and their states • on a miss, find directory entry, look it up, and communicate only with the nodes that have copies if necessary • in scalable networks, communication with directory and copies is through network transactions • Many alternatives for organizing directory information
Basic Operation of Directory • Read from main memory by processor i: • If dirty-bit OFF then { read from main memory; turn p[i] ON; } • if dirty-bit ON then { recall line from dirty proc (downgrade cache state to shared); update memory; turn dirty-bit OFF; turn p[i] ON; supply recalled data to i;} • Write to main memory by processor i: • If dirty-bit OFF then {send invalidations to all caches that have the block; turn dirty-bit ON; supply data to i; turn p[i] ON; ... } • k processors • With each cache-block in memory: k presence-bits, 1 dirty-bit • With each cache-block in cache: 1 valid bit, and 1 dirty (owner) bit
Real Manycore Architectures • ARM Cortex A9 • GPU • P2012
ARM Cortex-A9 processors • 98% of mobile phones use at least on ARM processor • 90% of embedded 32-bit systems use ARM • The Cortex-A9 processors are the highest performance ARM processors implementing the full richness of the widely supported ARMv7 architecture.
Cortex-A9 CPU • Superscalar out-of-order instruction execution • Any of the four subsequent pipelines can select instructions from the issue queue • Advanced processing of instruction fetch and branch prediction • Up to four instruction cache line prefetch-pending • Further reduces the impact of memory latency so as to maintain instruction delivery • Between two and four instructions per cycle forwarded continuously into instruction decode • Counters for performance monitoring
The Cortex-A9 MPCore Multicore Processor • Design-configurable Processor supporting between 1 and 4 CPU • Each processor may be independently configured for their cache sizes, FPU and NEON • Snoop Control Unit • Accelerator Coherence Port
Snoop Control Unit and Accelerator Coherence Port • The SCU is responsible for managing: • the interconnect, • arbitration, • communication, • cache-2-cache and system memory transfers, • cache coherence • The Cortex-A9 MPCore processor also exposes these capabilities to other system accelerators and non-cached DMA driven mastering peripherals: • To increase the performance • To reduce the system wide power consumption by sharing access to the processor’s cache hierarchy • This system coherence also reduces the software complexity involved in otherwise maintaining software coherence within each OS driver.
What is GPGPU? • The graphics processing unit (GPU) on commodity video cards has evolved into an extremely flexible and powerful processor • Programmability • Precision • Power • GPGPU: an emerging field seeking to harness GPUs for general-purpose computation other than 3D graphics • GPU accelerates critical path of application • Data parallel algorithms leverage GPU attributes • Large data arrays, streaming throughput • Fine-grain SIMD parallelism • Low-latency floating point (FP) computation • Applications – see //GPGPU.org • Game effects (FX) physics, image processing • Physical modeling, computational engineering, matrix algebra, convolution, correlation, sorting
Motivation 1: • Computational Power • GPUs are fast… • GPUs are getting faster, faster
Motivation 2: • Flexible, Precise and Cheap: • Modern GPUs are deeply programmable • Solidifying high-level language support • Modern GPUs support high precision • 32 bit floating point throughout the pipeline • High enough for many (not all) applications