Download

1 / 15
180 likes | 670 Views
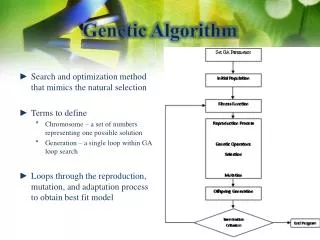
Genetic Algorithm. What is a genetic algorithm? “Genetic Algorithms are defined as global optimization procedures that use an analogy of genetic evolution of biological organisms.” Basically genetic algorithms tend to find the best solution to a problem by following an evolutionary process.

E N D
Genetic Algorithm • What is a genetic algorithm? • “Genetic Algorithms are defined as global optimization procedures that use an analogy of genetic evolution of biological organisms.” • Basically genetic algorithms tend to find the best solution to a problem by following an evolutionary process.
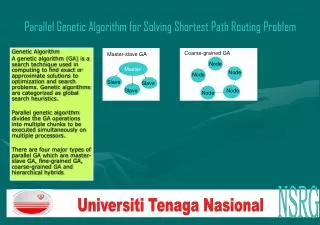
Parallel Genetic Algorithm • For large population sizes, G.A. is computationally infeasible. • Hence the use of Parallel Genetic Algorithms.
Model and Encoding • Island Model -: Each processor runs a G.A. on a subset of the population and there is periodic migration. • Fixed Length Binary String Encoding -: Here if gene is included in the subset then value is 1 else 0.
Fitness Evaluation • Two Different Criteria • Classification Accuracy • Size of the subset fitness(x) = w1 * accuracy(x) + w2 *(1 – dimensionality(x)) • Here, • accuracy(x) =test accuracy of the classifier built with the gene subset represented by x • dimensionality(x) [0,1] = the dimension of the subset
Fitness Evaluation • w1 = weight assigned to accuracy • w2 = weight assigned to dimensionality • High classification accuracy and low dimension has high fitness.
Test Parameters • The tests were run on two processors. • The parameters of G.A. in each processor were set as -: • Population Size : 1000 • Trials : 400000 • Crossover probability: 0.6 • Mutation probability: 0.001
Test Parameters • Selection Strategy: Elitist • Migration Probability: 0.002 • Crossover probability of average level to get different subpopulation with good traits of the parents. • Mutation Probability low to avoid randomness of selection. • Selection Strategy is Elitist which ensures that the best individuals are kept and hence leads to more accurate subsets of genes.
Results • Leukemia Data Set • Subset with 29 Genes found • Classifies 36/38 training instances correctly • Classifies 30/34 test instances correctly • Colon Data Set • Subset with 30 genes found • 92% accuracy on the training data set
Results Comparison • Results better than other algorithms such as G-S and NB algorithms which have accuracies less than 90% and gene numbers varying from 10 to 500.
Conclusion • Method does well in finding smaller gene subsets and better accuracies. • Fitness function needs to be something more sophisticated than the simple one used right now to ensure a final compact subset every time.