Download

1 / 16
160 likes | 307 Views
Un Sistema di Speaker Identification per la segmentazione Automatica di Videogiornali. G. Percannella 1 , C. Sansone 2 , D. Sorrentino 1 , M. Vento 1 1 Dipartimento di Ing. dell’Informazione e Ing. Elettrica Università degli Studi di Salerno 2 Dipartimento di Informatica e Sistemistica

E N D
Un Sistema di Speaker Identification per la segmentazione Automatica di Videogiornali G. Percannella1,C. Sansone2,D. Sorrentino1, M. Vento1 1 Dipartimento di Ing. dell’Informazione e Ing. Elettrica Università degli Studi di Salerno 2 Dipartimento di Informatica e Sistemistica Università degli Studi di Napoli “Federico II” E-mail: d.sorrentino@unisa.it
Il contesto • La Segmentazione dei video è il passo preliminare per l’indicizzazione ed il retrieval attraverso contenuti. • La traccia video è la sorgente di informazioni più comune. • Non è raro l’impiego dell’audio come sorgente alternativadi informazioni per la segmentazione. • E’ possibile impiegare un sistema di speaker identification in tempo reale per la segmentazione automatica e per la metadatazione automatica dei notiziari.
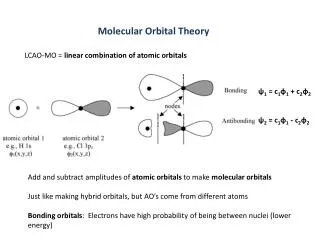
Speaker identification • Sistemi Closed Set • Lo Speaker da identificare è parte di un insieme finito di persone noto a priori. • Sistemi Open Set • Lo Speaker da identificare può non appartenere all’insieme di Speaker noti. • Sistemi Text-Dependent • E’ richiesto l’inserimento di un testo fisso per l’identificazione di uno Speaker (ad esempio una password). • Sistemi Text-Independent • Non è imposto alcun vincolo al testo degli Speaker per la loro identificazione.
Il nostro sistema • E’ Text Indipendent e opera in tempo reale ed in modalità closed set. • Utilizza feature calcolate nel dominio del tempo e quello della frequenza. • La classificazione è effettuata attraverso una rete neurale LVQ in due diverse configurazioni prototipali.
Architettura del sistema Sorgente Audio Buffer Preprocessing Normalizzazione Feature Estrazione Feature Classificazione Speaker Identificato
Pre-processing • Frame blocking • Il segnale audio è partizionato in frame sovrapposti. • La sovrapposizione è pari ad due terzi della lunghezza del frame. • La durata di un frame è di circa 23 ms. • Pre-enfasi • Un filtro passa basso riduce significativamente le componenti in alta frequenza, in modo da aumentare il rapporto segnale rumore. • Finestramento • Una finestra di Hamming elimina le discontinuità agli estremi del frame. • Si assegna un peso maggiore ai campioni centrali che compongono il frame.
Feature utilizzate • Linear Predictive Cepstral Coefficients(LPCC) • Estratti nel dominio del tempocon un analisi di predizione lineare • Si utilizza il metodo di Levinson-Durbin. • Post Filter Linear(PF) • Estratti ancora nel dominio del tempo attraverso un analisi di predizione lineare. • Migliorano le prestazioni del LPCC alle basse frequenze. • Mel Filtered Cepstral Coefficients (MFCC) • Ricavati nel dominio della frequenza mediante la trasformata inversa di Fourier del logaritmo dello spettro di ampiezza del segnale di ingresso.
Normalizzazione e classificazione delle feature • Normalizzazione • Rende assoluto il sistema di riferimento. • Migliora il potere discriminante delle feature. • Classificazione • Addestramento • Una rete LVQ è addestrata con algoritmo FSCL come classificatore. • La classificazione di uno speaker è basata sul concetto di minima distanza. • Testing • Il sistema provvederà alla classificazione di un blocco di vettori di feature, riportando in uscita lo speaker più occorrente. • Ogni vettore di feature è calcolato in un intervallo di circa 23 msec (frame audio). • La risposta del sistema viene effettuata dopo aver analizzato una sequenza di frame di durata prefissata (shot audio). • La durata degli shot può variare da 0.5 sec a 5 sec.
Il database • L’intero database ha una durata complessiva di circa 1h e 2 min. • 12 differenti telegiornali italiani. • 10 speaker (5 di sesso maschile e 5 femminile). • 25 segmenti audio per ogni speaker. • Ogni segmento audio nel data base ha una durata di 15 sec.
La sperimentazione • Tre training set (TRS) sono stati usati, ogni uno costituito da segmenti audio di durata multipla di 15 sec. • 15 sec • 30 sec • 45 sec • La dimensione del test set (TS) è sempre fissata a 30 sec. • Il classificatore LVQ opera con 50 e 100 prototipi per classe. • Si sono utilizzati 3 differenti set di feature • solo LPCC • solo MFCC • MFCC insieme alle LPCC e PF.
Risultati sperimentali - Caso 1 35% 50 prototipi per classe 30% 45 sec Tasso di errore in funzione della durata degli shot in secondi per i tre TRS. 25% 15 sec 20% 15% 30 sec 10% 5% 0% 0.5 1 1.5 2 3 5 35% 100 prototipi per classe 30% 45 sec 25% Solo LPCC feature. 15 sec 20% 15% 30 sec 10% 5% 0% 0.5 1 1.5 2 3 5
Risultati sperimentali - Caso 2 45% 45 sec 40% 30 sec 35% Tasso di errore in funzione della durata degli shot in secondi per i tre TRS. 30% 25% 15 sec 20% 15% 10% 5% 50 prototipi per classe 0% 45% 0.5 1 1.5 2 3 5 40% 30 sec 35% 45 sec 30% 25% Solo MFCC feature. 15 sec 20% 15% 10% 5% 100 prototipi per classe 0% 0.5 1 1.5 2 3 5
Risultati sperimentali - Caso 3 18% 50 prototipi per classe 16% Tasso di errore in funzione della durata degli shot in secondi per i tre TRS. 14% 12% 10% 8% 15 sec 6% 30 sec 4% 45 sec 2% 16% 100 prototipi per classe 0.5 1 1.5 2 3 5 14% 12% LPCC, MFCC e PF feature 10% 8% 6% 30 sec 15 sec 4% 45 sec 2% 0% 0.5 1 1.5 2 3 5
Shot Length: L’applicativo di speaker identification 5 speakers L’applicazione è basata su un sistema addestrato con un TRS avente segmenti di 30 sec, usando un classificatore LVQ con 50 prototipi. Shot length = 1 sec
Shot Length: L’applicativo di speaker identification • Il tasso di riconoscimento è del 96.46%. • L’affidabilità R è valutata come:100*(1-N2/N1). • N1 è il numero di vettori di feature attribuiti alla classe vincente. • N2 è il numero di vettori di feature attribuiti runner-up. • Il tasso di riconoscimento sulle classificazioni affidabili è del99.79%. SIRTA
Conclusioni • Presentiamo un sistema di speaker identification in tempo reale che utilizza feature estratte sia dal dominio del tempo che in quello delle frequenze. • Attraverso un criterio di votazione a maggioranza, il sistema proposto è più robusto rispetto ai silenzi e ai segmenti unvoiced. • I risultati sul database di segmenti audio estratti dai notiziari dimostrano l’efficacia del sistema nell’identificazione degli speaker in tempo reale. • Il sistema può coadiuvare l’implementazione di una applicazione che usa l’informazione audio per la segmentazione automatica degli stream video.