Download

1 / 72
720 likes | 1.03k Views
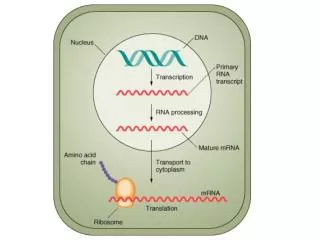
GENOME ANNOTATION AND FUNCTIONAL GENOMICS The protein sequence perspective. GENOME ANNOTATION. Two main levels: STRUCTURAL ANNOTATION – Finding genes and other biologically relevant sites thus building up a model of genome as objects with specific locations

E N D
GENOME ANNOTATION AND FUNCTIONAL GENOMICSThe protein sequence perspective
GENOME ANNOTATION • Two main levels: • STRUCTURAL ANNOTATION – Finding genes and other biologically relevant sites thus building up a model of genome as objects with specific locations • FUNCTIONAL ANNOTATION – Objects are used in database searches (and expts) aim is attributing biologically relevant information to whole sequence and individual objects
WHY PROTEIN RATHER THAN DNA? • Larger alphabet -more sensitive comparisons • Protein sequences lower signal to noise ratio • Less redundancy and no frameshifts • Each aa has different properties like size, charge etc • Closer to biological function • 3D structure of similar proteins may be known • Evolutionary relationships more evident • Availability of good, well annotated protein sequence and pattern databases
Large-scale genome analysis projects • Rate-limiting step is annotation • Whole genome availability provides context information • Main goal is to bridge gap between genotype and phenotype
Definitions of Annotation • Addition of as much reliable and up-to-date information as possible to describe a sequence • Identification, structural description, characterisation of putative protein products and other features in primary genomic sequence • Information attached to genomic coordinates with start and end point, can occur at different levels • Interpreting raw sequence data into useful biological information
ANNOTATION/FUNCTION CAN BE MAPPED TO DIFFERENT LEVELS: ORGANISM -phenotypic function (morphology, physiology, behaviour, environemntal response), context NB CELLULAR -metabolic pathway, signal cascades, cellular localisation. Context dependent MOLECULAR -binding sites, catalytic activity, PTM, 3D structure DOMAIN SINGLE RESIDUE
Annotation is the description of: • Function(s) of the protein • Post-translational modification(s) • Domains and sites • Secondary structure • Quaternary structure • Similarities to other proteins • Disease(s) associated with deficiencie(s) in the protein • Sequence conflicts, variants, etc.
ALTERNATIVE PRODUCTS CATALYTIC ACTIVITY COFACTOR DEVELOPMENTAL STAGE DISEASE DOMAIN ENZYME REGULATION FUNCTION INDUCTION PATHWAY PHARMACEUTICALS POLYMORPHISM PTM SIMILARITY SUBCELLULAR LOCATION SUBUNIT TISSUE SPECIFICITY Additional information for proteins
Amino-acid sites are: • Post-translational modification of a residue • Covalent binding of a lipidic moiety • Disulfide bond • Thiolester bond • Thioether bond • Glycosylation site • Binding site for a metal ion • Binding site for any chemical group (co-enzyme, prosthetic group, etc.)
SIGNAL SEQUENCE TRANSIT PEPTIDE PROPEPTIDE CHAIN PEPTIDE DOMAIN ACTIVE SITE DNA BIND SITE METAL BIND SITE MOLECULE BIND SITE TRANSMEMBRANE Regions:
Annotation sources: • publications that report new sequence data • review articles to periodically update the annotation of families or groups of proteins • external experts • protein sequence analysis
Approaches to functional annotation: • Automatic annotation (sequence homology, rules, transfer info from pdb) • Automatic classification (pattern databases, clustering, structure) • Automatic characterisation (functional databases) • Context information (comparitive genome analysis, metabolic pathway databases) • Experimental results (2D gels, microarrays) • Full manual annotation (SWISS-PROT style)
PROTEIN SEQUENCE ANALYSIS • Protein sequence can come from gene predictions, literature or peptide sequencing • Analysis on different levels: • molecular • cellular • organism • Simplest case- match for whole sequence in database- determination of structure and function • In between- partial matches across sequence to diverse or hypothetical proteins • Difficult case- no match, have to derive information from amino acid properties, pattern searches etc
Predicting function from sequence similarity • Orthologues- arose from speciation, same gene in different organisms -can have <30% homology • Paralogues- from duplication within a genome, second copy may have new or changed function (difficult to distinguish between otho- and paralogues unless whole genome is available) • Equivalog- proteins with equivalent functions • Analog- proteins catalyzing same reaction but not structurally related • Some enzymes may have seq similarity simply because common catalytic site, substrate, pathway.
TYPES OF HOMOLOGY Superfamily PROTEIN/DOMAIN Duplication within species Paralogues may have different functions A B Speciation Orthologues may have different functions, if same - Equivalogs B1 B2
Incorrect predictions Maverick genes shared with some other species Common genes Maverick genes unique function Sequence homology in genomes When you do a whole genome BLAST search there is a general pattern of results: Maverick genes tend to diverge more frequently than core genes
Using homology information for automatic annotation- automatic annotation of TrEMBL as an example
Well-annotated reference database (eg SWISS-PROT) Highly reliable diagnostic protein family signature database with the means to assign proteins to groups (eg CDD, InterPro, IProClass) A RuleBase to store and manage the annotation rules, their sources and their usage Requirements for automatic annotation
Search target Transfer annotation to target database Example:FASTA against sequence database and transfer of DE line of best hit Direct Transfer XDB Target
Usually more than one external database is used Combine the different results Multiple Sources XDB Target
Conflicts • Contradiction • Inconsistencies • Synonyms • Redundancy
Use a translator to map XDB language to target language Translation XDB Target
Translation Examples • ENZYME TrEMBLCA L-ALANINE=D-ALANINECC -!- CATALYTIC ACTIVITY: L-ALANINE=CC D-ALANINE. • PROSITE TrEMBL/SITE=3,heme_ironFT METAL IRON • Pfam TrEMBL FT DOMAIN zf_C3HC4FT ZN_FING C3HC4-TYPE
Demands on a system for automated data analysis and annotation • Correctness • Scalability • Updateable • Low level of redundant information • Completeness • Standardized vocabulary
SWISS-PROT RuleBase TrEMBL PROSITE (and Pfam, PRINTS, ProDom, SMART, Blocks etc) SWISS-PROT/TrEMBL/RuleBase in Oracle What do we have?
Standardized transfer of annotation from characterized proteins in SWISS-PROT to TrEMBL entries • TrEMBL entry is reliably recognized by a given method as a member of a certain group of proteins • corresponding group of proteins in SWISS-PROT shares certain annotation • common annotation is transferred to the TrEMBL entry and flagged as annotated by similarity
Automatic annotation information flow • Get information necessary to assign proteins to groups eg using InterPro or other biological or family information- store in RuleBase • Group proteins in SWISS-PROT by these conditions • Extract common annotation shared by all these proteins- store in RuleBase • Group unannotated sequences by the conditions • Transfer common annotation flagged with evidence tags • Note: can add taxonomic constraints
Use XDB to extract entries from standard database Example:Pfam:PF00509 HemagglutininHEMA_IAVI7/P03435HEMA_IANT6/P03436HEMA_IAAIC/P03437HEMA_IAX31/P03438HEMA_IAME2/P03439HEMA_IAEN7/P03440HEMA_IABAN/P03441HEMA_IADU3/P03442HEMA_IADA1/P03443HEMA_IADMA/P03444HEMA_IADM1/P03445HEMA_IADA2/P03446HEMA_IASH5/P03447 Extract Reference Entries Pfam SWISS-PROT TrEMBL
Extract Common Annotation 132 entries read131 ID HEMA_XXXXX125 DE HEMAGGLUTININ PRECURSOR. 6 DE HEMAGGLUTININ.131 GN HA130 CC -!- FUNCTION: HEMAGGLUTININ IS RESPONSIBLE FOR ATTACHING THE130 CC VIRUS TO CELL RECEPTORS AND FOR INITIATING INFECTION.125 CC -!- SUBUNIT: HOMOTRIMER. EACH OF THE MONOMER IS FORMED BY TWO125 CC CHAINS (HA1 AND HA2) LINKED BY A DISULFIDE BOND. 75 DR HSSP; P03437; 1HGD. 31 DR HSSP; P03437; 1DLH.131 KW HEMAGGLUTININ; GLYCOPROTEIN; ENVELOPE PROTEIN102 KW SIGNAL 1 KW COAT PROTEIN; POLYPROTEIN; 3D-STRUCTURE130 FT CHAIN HA1 CHAIN.107 FT CHAIN HA2 CHAIN.102 FT SIGNAL
Store the used conditions and the extracted common annotation in a separate database Store Common Annotation XDB SWISS-PROT TrEMBL RuleBase
RULES • Rules describe: • the content of the annotation to be transferred (ACTIONS), • the CONDITIONS which the target TrEMBL entry must fulfill in order to allow transfer of the annotation. • Rules uniquely describe or delineate a set of SWISS-PROT entries. • The common annotation in these entries is transferred to TrEMBL.
// #RULE RU000482 #DATE 2001-01-11 #USER OPS$WFL #PACK PROSITE ?PSAC PS00449 ?EMOT PS00449 !ECNO 3.6.1.34 !SPDE ATP synthase A chain !CCFU KEY COMPONENT OF THE PROTON CHANNEL; IT MAY PLAY A DIRECT ROLE IN THE TRANSLOCATION OF PROTONS ACROSS THE MEMBRANE (BY SIMILARITY) !CCSU F-TYPE ATPASES HAVE 2 COMPONENTS, CF(1) - THE CATALYTIC CORE - AND CF(0) - THE MEMBRANE PROTON CHANNEL. CF(1) HAS FIVE SUBUNITS: ALPHA(3), BETA(3), GAMM A(1), DELTA(1), EPSILON(1). CF(0) HAS THREE MAIN SUBUNITS: A, B AND C (BY SIMILARITY) !CCLO INTEGRAL MEMBRANE PROTEIN (By Similarity) !CCSI TO THE ATPASE A CHAIN FAMILY !SPKW CF(0) !SPKW Hydrogen ion transport !SPKW Transmembrane // ACTIONS } CONDITIONS
Use conditions to extract entries from TrEMBL Add common annotation to the entries Add Annotation to Target XDB SWISS-PROT TrEMBL RuleBase
Extract conditions from XDB Group SWISS-PROT by conditions Extract common annotation Group TrEMBL by conditions Add common annotation to TrEMBL Automatic annotation using multiple dbs ENZYME Pfam INTERPRO PROSITE SWISS-PROT TrEMBL RuleBase
RU000652 with additional condition connected by ‘AND’ // #RULE RU000652 #DATE 2001-01-11 #USER OPS$WFL #PACK PROSITE ?IPRO IPR002379 ?PSAC PS00605 ?EMOT PS00605 !SPDE ATP synthase C chain (Lipid-binding protein) (Subunit C) !ECNO 3.6.1.34 !CCSU F-TYPE ATPASES HAVE 2 COMPONENTS, CF(1) - THE CATALYTIC CORE - AND CF(0) - THE MEMBRANE PROTON CHANNEL. CF(1) HAS FIVE SUBUNITS: ALPHA(3), BETA(3), GAMMA(1), DELTA(1), EPSILON(1). CF(0) HAS THREE MAIN SUBUNITS: A, B AND C (By Similarity) !CCSI TO THE ATPASE C CHAIN FAMILY !SPKW CF(0) !SPKW Hydrogen ion transport !SPKW Lipid-binding !SPKW Transmembrane // Additional condition (parent signature)
Condition types • Signature hits: • - Prosite, Prints, Pfam, Prodom • Taxonomy: • - Broad groups like: • Archaea • Bacteriophage • Eukaryota • Prokaryota • Eukaryotic viruses • - more specific such as species • Organelle • Conditions • Negated conditions
Rule-building • Grouping and extraction of common annotation: • - semi automated but involves manual data-mining • assisted by perl/shell scripts. • Algorithmic data-mining: • - fully automated. • - fast. • - exhaustive exploration of condition-set/annotation • search-space . • - non-biological, validity of rules being assessed • by comparison with semi-manual approach.
Advantages of this method • Uses reliable ref database, prevents propagation of incorrect annotation • Using common annotation of multiple entries, lower over-prediction than from best hit of BLAST • Can standardize annotation and nomenclature of target sequences, since reference is standardized • Can have different levels of common annotation from different levels of family hierarchy • Independent of multi-domain organisation • Evidence tags allow for easy tracking and updating
Pitfalls of automatic functional analysis • Multifunctional proteins- genome projects often assign single function, info is lost in homology search • Hypothetical proteins (40% oRFs unknown), and poorly or even wrongly annotated proteins • No coverage of position-specific annotation eg active sites • Current methods provide only a phrase describing some properties of the unknown protein It is important to have evidence for all annotation added
Predicting function from non-homology • Look at position of genes relative to others, compare with other organisms • Can still build up rules from annotated sequences using information you have on other features like fold, physical properties etc. • Use physical properties and known attributes
Protein functions from regions • Active sites- short, highly conserved regions • Loops- charged residues and variable sequence • Interior of protein- conservation of charged amino acids
Polar (C,D,E,H,K,N,Q,R,S,T) - active sites Aromatic (F,H,W,Y) - protein ligand- binding sites Zn+-coord (C,D,E,H,N,Q) - active site, zinc finger Ca2+-coord (D,E,N,Q) - ligand-binding site Mg/Mn-coord (D,E,N,S,R,T) - Mg2+ or Mn2+ catalysis, ligand binding Ph-bind (H,K,R,S,T) - phosphate and sulphate binding C disulphide-rich, metallo- thionein, zinc fingers DE acidic proteins (unknown) G collagens H histidine-rich glycoprotein KR nuclear proteins, nuclear localisation P collagen, filaments SR RNA binding motifs ST mucins Protein functions from specific residues
Supplement annotation with Xrefs to other databases • DDBJ/EMBL/GenBank Nucleotide Sequence Database • PDB • Genomic databases (FlyBase, MGD, SGD) • 2D-Gel databases (ECO2DBASE, SWISS-2DPAGE, Aarhus/Ghent, YEPD, Harefield), Gene expression data • Specialized collections (OMIM, InterPro, PROSITE, PRINTS, PFAM, ProDom, SMART, ENZYME, GPCRDB, Transfac, HSSP)
Approaches to functional annotation: • Automatic annotation (sequence homology, rules, transfer info from pdb) • Automatic classification (pattern databases, clustering, structure) • Automatic characterisation (functional databases) • Context information (comparitive genome analysis, metabolic pathway databases) • Experimental results (2D gels, microarrays) • Full manual annotation (SWISS-PROT style)
AUTOMATIC CLASSIFICATION Annotation can by using Clustering methods eg CluSTR (EBI), and pattern searches (InterPro etc)- classification of proteins into different families