Download
1 / 22
250 likes | 265 Views
Introduction to Deep Learning. What is DL? (1). “...a class of machine learning techniques, developed mainly since 2006, where many layers of non-linear information processing stages or hierarchical architectures are exploited.” - http://www.icassp2012.com/Tutorial_09.asp

E N D
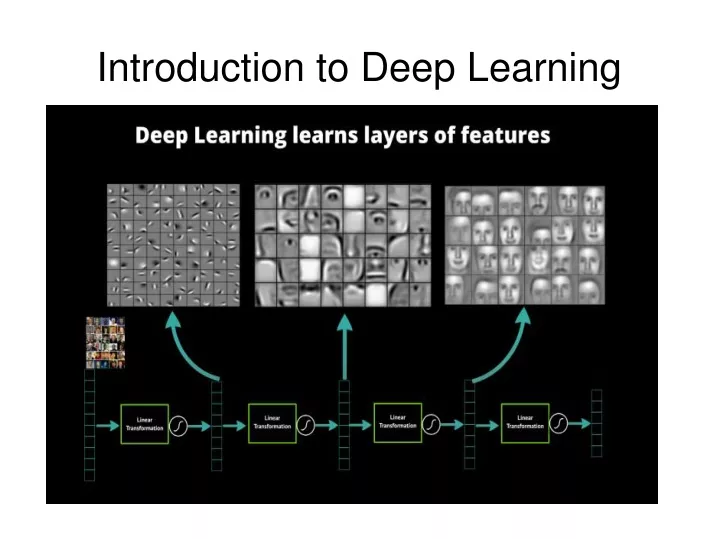
What is DL? (1) • “...a class of machine learning techniques, developed mainly since 2006, where many layers of non-linear information processing stages or hierarchical architectures are exploited.” - http://www.icassp2012.com/Tutorial_09.asp • Deep learning is distinguished by its learning of multiple levels of features, a hierarchy of features • These multiple levels of representation correspond to multiple levels of abstraction
What is DL? (3) • So basically... We're interested in learning representations of data that are useful • We want to do this automatically because designing features is hard • Representation learning is the field of study concerned with automatically finding features from data
A (very brief) history (1) • First artificial neuron was the Threshold Logic Unit (or binary threshold neuron) – McCulloch-Pitts • Hebbian Learning – Weights (synapses) adapt during learning. These are physical changes in the brain • Led to Perceptron learning rule and also Widrow-Hoff learning rule. Early implementations at Stanford: Adaline and Madaline ([Many] Adaptive Linear Element[s]) • 1960's: Workable AI just 10 years away! • Spoiler alert: It wasn't
A (very brief) history (2) • Problems: • Can't learn or even represent XNOR, XOR • Can't learn to discriminate between non-linearly seperable inputs [Minsky and Papert, 1969] • In order to overcome these limitations, we need an extra layer in the network
A (very brief) history (3) • Backpropagation! • Discovered in the 1970's • Forgotten • Discovered in the 1980's (Hinton) • Hype, excitement • Lots of failure in industry • “AI Winter” • SVMs
A (very brief) history (4) • Training deep architectures met mostly with failure • (Why should we care about deep architectures anyway?) • A Fast Learning Algorithm for Deep Belief Nets – 2006 • Efficient Learning of Sparse Representations with an Energy-Based Model • Greedy Layer-Wise Training of Deep Networks • Since these papers, hundreds of papers have been published
Why do we want deep nets? (1) • Artificial neural nets with one hidden layer can approximate any* function • Number of nodes required to do so could grow very quickly • For some function classes, a network with (k-1) layers would need a number of nodes exponential in the number of inputs, whilst a k layer network would be polynomial (parity function is an example of this). • http://ufldl.stanford.edu/wiki/index.php/Deep_Networks:_Overview • *under some assumptions
Why do we want deep nets? (2) • Brain has a deep architecture • Cognitive processes seem deep • Humans organize thoughts hierarchically • First learn simple concepts and then compose them into more difficult ones • http://www.iro.umontreal.ca/~pift6266/H10/notes/deepintro.html
Why is training so difficult? • Before 2006, training deep networks yielded worse results (with the exception of convolutional neural nets) • Until then, researchers were randomly initializing weights, then training using a labeled training set. • This was unsuccesful • Scarcity of labeled data • Bad local optima – minimizing error involves optimizing a highly non-convex function. Not only local minima, but saddle points • Diffusion of gradients – when error derivatives are propagated back, the gradients rapidly diminish as the depth of the network increases
What to do? • 2006 – 3 important papers, spearheaded by Hinton et al's “A fast learning algorithm for deep belief nets” • 3 Key principles in the papers: • Unsupervised learning of representations is used to pre-train each layer • Unsupervised learning is used to learn representations from the features learned in the previous layer • Supervised learning used to fine tune all the layers.
Greedy Layerwise learning • Unsupervised learning is about finding structure in data • It is used to initialize the parameters of the hidden layers • Turns out this procedure initializes weights in a region near good local minima • We want to learn not only a good classifier, but also something about the structure of the input • Greedy? (point 2 of previous slide)
Distributed Belief Networks • Idea of unsupervised pretraining came from Hinton's work on distributed belief networks • These use Restricted Boltzmann Machines as the building blocks • Train 2 layers at a time and ignore the rest • Use features learned in previous layer to train next layer
Different Architectures • The paper by Deng [1] outlines three broad classes of deep learning architectures: • Generative • Discriminative • Hybrid [1] Li Deng. Three classes of deep learning architectures and their applications: A tutorial survey.
Generative • “...are intended to characterize the high-order correlation properties of the observed or visible data for pattern analysis or synthesis purposes, and/or characterize the joint statistical distributions of the visible data and their associated classes...” • Can still use this type of architecture via Bayes rule as discriminative type
Discriminative • “...are intended to directly provide discriminative power for pattern classification, often by characterizing the posterior distributions of classes conditioned on the visible data...”
Hybrid • “...the goal is discrimination but is assisted with the outcomes of generative architectures, or discriminative criteria are used to learn the parameters in any of the deep generative models...”
Applications • http://people.idsia.ch/~juergen/superhumanpatternrecognition.html • “...our NN achieved 0.56% error rate in the IJCNN Traffic Sign Recognition Competition of INI/RUB [14,14b]. Humans got 1.16% on average (over 2 times worse - some humans will do better than that though)...” Single-image, multi-class classification problem More than 40 classes More than 50,000 images in total Large, lifelike database
Applications • “...has already been put to use in services like Apple’s Siri virtual personal assistant, which is based on Nuance Communications’ speech recognition service, and in Google’s Street View, which uses machine vision to identify specific addresses” • http://www.nytimes.com/2012/11/24/science/scientists-see-advances-in-deep-learning-a-part-of-artificial-intelligence.html?hpw&pagewanted=all

















