Download

1 / 41
410 likes | 621 Views
R-Trees A Dynamic Index Structure for Spatial Searching. Antonin Guttman In Proceedings of the 1984 ACM SIGMOD international conference on Management of data (SIGMOD '84). ACM, New York, NY, USA. Outline. Introduction R-Tree Index Structure Searching and Updating Performance Tests

E N D
R-Trees A Dynamic Index Structure for Spatial Searching Antonin Guttman In Proceedings of the 1984 ACM SIGMOD international conference on Management of data (SIGMOD '84). ACM, New York, NY, USA
Outline • Introduction • R-Tree Index Structure • Searching and Updating • Performance Tests • Conclusion
Outline • Introduction • Background • Previous Works • R-Tree Index Structure • Searching and Updating • Performance Tests • Conclusion
Background • Motivation • To deal with spatial data efficiently • Traditional database are for one-dimension data • Traditional Index Structure • Hash Tables • B Trees and ISAM
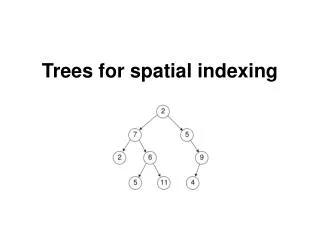
Outline • Introduction • R-Tree Index Structure • R-Tree Index Structure • Properties of the R-Tree • Example of a R-Tree • Searching and Updating • Performance Tests • Conclusion
R-Tree Index Structure • What is a R-tree • Height-balanced tree similar to a B-tree • No need for doing periodic reorganization • What is the contents in the nodes • (I, tuple-identifier) in leaf node • (I, child-pointer) in non-leaf node • It must satisfy following properties
Properties of the R-Tree • Let M be the maximum number of entries that will fit in one node • Let m <= M/2 be a parameter specifying the minimum number of entries in a node
Properties of the R-Tree • Every leaf node contains between m and M index records unless it is the root • For each index record(I, tuple-identifier) in a leaf node, I is the smallest rectangle that spatially contains the n-dimensional data object represented by the indicated tuple • Every non-leaf node has between m and M children unless it is the root • For each entry(I, child-pointer) in a non-leaf node, I is the smallest rectangle that spatially contains the rectangles in the child node • The root node has at least two children unless it is a leaf • All leaves appear on the same level
Outline • Introduction • R-Tree Index Structure • Searching and Updating • Searching • Example of Searching • Insertion • Updates and Other Operations • Node Splitting • Performance Tests • Conclusion
Searching • Problem definition Give an R-Tree whose root node is T, find all index records whose rectangles overlap a search rectangle S • Notations EI is the rectangle part of an index entry E Ep is the tuple-identifier or child-pointer of an E
Searching Search(T, LIST) { IF (T is not a leaf) FOR EACH (E in T) IF (E.EI overlaps S) Search(E.Ep); ELSE FOR EACH (E in T) IF (E.EI overlaps S) LIST.ADD(E.Ep); }
Insertion • It is similar to insert a record in B-treethat new record are added to the leaves, nodes that overflow are split, and splits propagate up the tree Insert(T, E) { L = ChooseLeaf(T, E); INSTALL E; IF (L is full) { LL = SplitNode(L); AdjustTree(L, LL); } }
Insertion - ChooseLeaf() N ChooseLeaf(T, E) { SET N = T; IF (N is a non-leaf node) { find the F that F.FI needs least enlargement to include E.EI IN N SET N = F.Fp; ChooseLeaf(N, E); } ELSE return N; }
Insertion - AdjustTree() AdjustTree(L, LL) { SET N = L; SET NN = LL; IF (N is root) // check if done return; SET P = N.parent; SET En to be N’s entry in P ADJUST EnI so that it tightly encloses all entry rectangles in N IF (NN != NULL) { CREATE Enn; // Enn.p = NN, EnnI enclosing all rectangles in NN P.add(Enn); IF (P is full) { PP = SplitNode(P); AdjustTree(P, PP); } } } These three lines are for adjust covering rectangle in parent entry
Deletion • Remove index record E from an R-tree Delete(T, E) { L = FindLeaf(T, E); IF (L != NULL) { Remove(E, L); // remove E from L CondenseTree(L); IF (root node has only one child) make the child the new root; } }
Deletion - FindLeaf() • Given an R-tree whose root node is T, find the leaf node containing the index entry E T FindLeaf(T, E) { IF (T is not a leaf) { FOR EACH (F in T) { IF (FI overlaps EI) { T = FindLeaf(Fp, E); } } } IF (T is leaf) { FOR EACH (F in T) IF (F MATCH E) return T; } }
Deletion - CondenseTree() CondenseTree(L) { CT1: SET N = L; SET Q = empty; // the set of eliminated nodes. CT2: IF (N is root) { FOR EACH (E in Q) Insert(T, E); } ELSE { SET P = N.parent; SET En to be N’s entry in P; CT3: IF (N has fewer than m entries) { DELETE (En, P) // delete En from P Q.add(N); } ELSE { CT4: adjust EnI to tightly contain all entries in N; CT5: SET N = P; GOTO CT2; } } }
Updates and Other Operations • Update • Just perform deletion and re-insertion to do update • Other operations • To find all data objects completely contained in a search area, or all objects that contain a search area • Range deletion
Node Splitting • We need to perform node splitting when we insert an entry into a full node • The two covering rectangles after a split should be minimized because it affect efficiency seriously • The are three different kind of splitting algorithms: exhaustive algorithm, quadratic-cost algorithm and linear-cost algoritym
Node Splitting- Exhaustive Algorithm • It is the most straightforward approach • To generate all possible groupings and choose the best • It most disadvantage is the high time complexity , and reasonable value of M is 200(4096/4/(4+1))
Node Splitting - Quadratic-Cost Algorithm • It attempts to find a small-area split, but is not guaranteed to find one with the smallest area possible • The cost is quadratic in M and linear in the number of dimensions • Process • Pick first entry for each group • Check if done • Select entry to assign
Quadratic-Cost Algorithm PickSeeds() • Select two entries to be the first elements of the groups • Process • Calculate inefficiency of grouping entries together • Choose the most wasteful pair
Quadratic-Cost Algorithm PickNext() • Select one remaining entry for classification in a group • Process • Determine cost of putting each entry in each group • Find entry with greatest preference for one group
Node Splitting – Linear-Cost Algorithm • It is linear in M and in the number of dimensions • It is identical to Quadratic Split but used a different version of PickSeed, PickNext • Process • Find extreme rectangles along all dimensions • Adjust for shape of the rectangle cluster • Select the most extreme pair
Outline • Introduction • R-Tree Index Structure • Searching and Updating • Performance Tests • Performance Tests • CPU Cost of Inserting Records • CPU Cost of Deleting Records • Search Performance Pages Touched • Search Performance CPU Cost • Space Efficiency • Second Series of Tests • CPU Cost of Inserts and Deletes vs. Amount of Data • Search Performance vs. Amount of Data Pages Touched • Search Performance vs. Amount of Data CPU Cost • Space Required for R-Tree vs. Amount of Data • Conclusion
Performance Tests • Implemented R-trees in C under Unix on a Vax 11/780 computer • It purpose is to choose values for M and m, and to evaluate different node-splitting algorithms • Five page sizes were tested, corresponding to different values of M • Values tested for m were M/2, M/3 and 2 • All tests used two-dimensional data
Second Series of Tests • It measured T-tree performance as a function of the amount of data in the index • The same sequence of test operations as before was run on samples containing 1057, 2238, 3295, and 4559 rectangles • Parameters • Linear algorithm with m = 2 • Quadratic algorithm with m = M/3 • Both with a page size of 1024 bytes(M=50)
Outline • Introduction • R-Tree Index Structure • Searching and Updating • Performance Tests • Conclusion
Conclusion • Author proposed an useful index structure, named R-tree, for multi-dimensional data • Author also gave tree different splitting algorithm, ran some tests on it, and concluded that linear node-split algorithm is the most efficient approach • R-tree would be easy to add to any relational database system