Download

1 / 226
2.27k likes | 2.5k Views
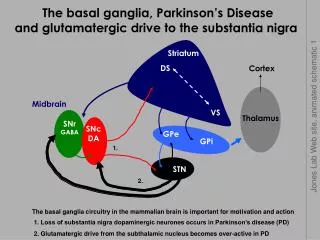
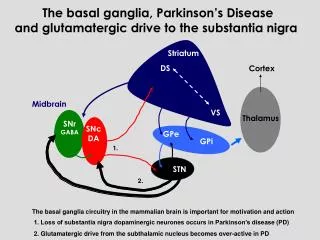
Biosequence Searching on STN. Cell biology. Cell Membrane: the interface to the outside world. Ribosomes: the "production plants" of the cell. There are many of these. Nucleus: the archive of building instructions. Molecular Biology. · Information storage medium in Nucleus. DNA . mRNA .

E N D
Cell biology Cell Membrane: the interface to the outside world. Ribosomes: the "production plants" of the cell. There are many of these. Nucleus: the archive of building instructions.
Molecular Biology ·Information storage medium in Nucleus DNA mRNA Protein ·Information transmission medium ·Manufactured in Ribosomes Transcription Translation
Proteins Within a cell, and on its membrane surface, there is a highly complex network of (bio)chemical processes at work, primarily controlled and/or catalysed by proteins. In higher organisms proteins are also important in extra-cellular features, e.g. hair (keratin). Proteins are manufactured in the ribosomes, from the production instructions received as mRNA molecules. This process is called translation. Chemically, proteins are poly-alpha-aminoacid biopolymers (or polypeptides). For the purposes a simple explanation it is important to focus just on mRNA here. However, note that RNA actually comes in three basic forms: messenger (mRNA), ribosomal (rRNA) and transfer (tRNA). Ribose nucleic acid (RNA) Messenger RNA (mRNA) is the molecular transmission medium by which information is carried from storage, as DNA, to the production plants, the ribosomes. mRNA is translated into protein in the ribosomes. Chemically, RNA is a polysaccharide biopolymer of nucleotide monomers (a polynucleotide). Deoxyribose nucleic acid (DNA) DNA is the molecular storage medium for genetic information, located in the nucleus of a cell. DNA is transcribed into mRNA in the nucleus. Chemically, DNA is also a polysaccharide biopolymer of nucleotide monomers (a polynucleotide).
The Alphabet of Proteins Viewed from a simple chemical perspective, proteins are sequential polyamide copolymers made from up to 20 naturally occurring alpha-aminoacid monomers. The precise order of the aminoacid monomers along the length of the polymer corresponds to a sequence of complementary nucleotides in the mRNA from which the protein was translated. The alpha-aminoacid amide bond in proteins is called a "peptide" bond, so a protein can also be described as a polypeptide; literally "a polymer of peptide linkages". However it is important to note that the word peptide is frequently used, in both scientific literature and patents, as shorthand to mean polypeptide. Polypeptides are sequential molecules which are often represented as a series of letters, e.g. …ALKSPRGFHITD…
The Alphabet of RNA Ribose nucleic acid (RNA) is a sequential copolymer of four monomers called nucleotides. The precise order of the monomers along the length of the polymer corresponds to a sequence of complementary nucleotides in the parent DNA molecule, from which the RNA was transcribed. The four nucleotide monomers, or letters of the RNA alphabet, are: n Adenine n Guanine n Cytosine n Uracil Like polypeptides, RNA can be represented in shorthand as a sequential series of letters, e.g. … AGCUAAUCGAGCUAAUCG ...
Nucleotides in RNA A nucleotide is made up from three components: a base, a sugar and a phosphate group. To be precise, it is the bases in nucleotides which are actually "A, G, C or U", and the sugar component in RNA is ribose. The third component of an RNA nucleotide is a phosphate, which is esterified to the 3'-hydroxyl of the ribose sugar. A nucleotide without this phosphate group is called a nucleoside.
Find in Registry the three components: • The Bases • The Sugar (linear and cyclic) • The Phosphoric Acid
adenine guanine cytosine uracil
The alphabet of DNA Like RNA, deoxyribose nucleic acid (DNA) is also a sequential copolymer of four monomers called nucleotides. The precise order of the monomers along the length of the polymer constitutes specific instructions for defining the structure and function of a living organism. DNA is the cellular storage medium for biological inheritance information. The four nucleotide monomers, or letters of the DNA alphabet, are: n Adenine n Guanine n Cytosine n Thymidine DNA and RNA are chemically very similar, and have closely related alphabets. However, in DNA Thymidine (T) is present, instead of Uracil (U). DNA can also be represented as sequential series of letters, e.g. … AGCTAATCGAGCTAATCG …
Nucleotides in DNA A nucleotide is made up from three components: a base, a sugar and a phosphate group. To be precise, it is the bases in nucleotides which are actually "A, G, C or T", and the sugar for DNA is 2'-deoxyribose, i.e. where the 2'-hydroxyl is absent from ribose. The third component, a phosphate, is esterified to the 3'-hydroxyl of 2'-deoxyribose. A nucleotide without this phosphate group is called a nucleoside.
Find in Registry the three components: • The Bases • The Sugar (cyclic) • The Phosphoric Acid
adenine guanine cytosine Thymidine
CAS Registry REGISTRY Genbank GENBANK Derwent Geneseq DGENE Wipo – FizKarlsruhe PCTGEN Plus.... Derwent WPI WPINDEX Chemical Abstracts CAPLUS Biosequence databases
REGISTRY File • The REGISTRY file is a chemical structure and dictionary database containing unique substance records as identified by the CAS Registry System.
The REGISTRY file contains records for All substances cited in CAplus >1.4 million substances cited in CAOLD Special registrations for regulatory lists such as TSCA and EINECS Nucleic acid sequences from GenBank® All substance records contain a unique CAS Registry Number (CAS RN) and must have an index name. Records may also have synonyms, molecular formulas, alloy composition tables, classes for polymers, nucleic acid and protein sequences, ring analysis data, and structure diagrams – all of which are searchable and displayable. . REGISTRY File
The REGISTRY file is a rich resource for biosequences from patent and non-patent literature. REGISTRY contains ~ 12 million nucleic acid sequences from CAplus and GenBank® ~ 1 million protein sequences from CAplus and CAOLD REGISTRY File
Protein sequences RN 241806-60-0 REGISTRY CN Reductase, thioredoxin (Staphylococcus epidermidis gene trxB) (9CI)(CA INDEX NAME) FS PROTEIN SEQUENCE SQL 310 SEQ 1 MTEVDFDVAI IGAGPAGMTA AVYASRANLK TVMIERGMPG GQMANTEEVE 51 NFPGFEMITG PDLSTKMFEH AKKFGAEYQY GDIKSVEDKG DYKVINLGNK 101 EITAHAVIIS TGAEYKKIGV PGEQELGGRG VSYCAVCDGA FFKNKRLFVI 151 GGGDSAVEEG TFLTKFADKV TIVHRRDELR AQNILQERAF KNDKVDFIWS 201 HTLKTINEKD GKVGSVTLES TKDGAEQTYD ADGVFIYIGM KPLTAPFKNL 251 GITNDAGYIV TQDDMSTKVR GIFAAGDVRD KGLRQIVTAT GDGSIAAQSA 301 ADYITELKDN MF Unspecified CI MAN SR CA LC STN Files: CA, CAPLUS, TOXLIT 1 REFERENCES IN FILE CA (1967 TO DATE) 1 REFERENCES IN FILE CAPLUS (1967 TO DATE) A CA Index Name is given for all biosequences. In some cases, additional names are also given. Depending on the display format selected, sequences can be displayed in 1- or 3-letter format. REGISTRY File
Modified peptide sequence RN 215531-93-4 REGISTRY CN Cyclosporin A, 6-[(3R,4S)-3-hydroxy-N-methyl-5-(methylthio)-L-leucine]-8-[(2R)-N-methyl-2- (methylthio)glycine]- (9CI) (CA INDEX NAME) FS PROTEIN SEQUENCE; STEREOSEARCH SQL 11 NTE cyclic modified (modifications unspecified) ---------------------------------------------------------------------- type ------ location ------ description ---------------------------------------------------------------------- uncommon Abu-1 - - stereo Ala-7 - D ---------------------------------------------------------------------- SEQ 1 XALVLAALLV L (continued on next slide) The definition for X appears in the NTE field (Abu = 2-aminobutyric acid). In this peptide, alanine-7 is the D-isomer. The peptide is cyclic. An X appears in this sequence. This indicates the presence of an uncommon amino acid. REGISTRY File Are you able to find this record?
REGISTRY File => c n/relf(s)=22 c/rel(s)=11 n/rel and 2/sand cyclosporin a/hp and nc=1 and methylthio(w)glycine(l)methylthio(1w)leucine(l)6(l)5(l)8(l)3(l)2
Modified peptide sequence o o o MF C61 H111 N11 O12 S2 SR CA LC STN Files: CA, CAPLUS, USPATFULL Absolute stereochemistry. 1 REFERENCES IN FILE CA (1967 TO DATE) 1 REFERENCES IN FILE CAPLUS (1967 TO DATE) Chemical structures are present for many sequences with <253 non-hydrogen atoms. REGISTRY File
Fusion protein RN 263325-26-4 REGISTRY CN 162-1238-Type I collagen (human subunit .alpha.1 precursor) fusion protein with 309-408-glycoprotein (human bone morphogenetic 2B precursor) (9CI) (CA INDEX NAME) OTHER NAMES: CN 5: PN: EP992586 SEQID: 6 claimed protein FS PROTEIN SEQUENCE SQL 1169 NTE ---------------------------------------------------------------------- type ------ location ------ description ---------------------------------------------------------------------- uncommon Aaa-887 - - uncommon Aaa-890 - - ---------------------------------------------------------------------- SEQ 1 QLSYGYDEKS TGGISVPGPM GPSGPRGLPG PPGAPGPQGF QGPPGEPGEP o o o 1 REFERENCES IN FILE CAPLUS (1967 TO DATE) This sequence originated from a patent. The location of the sequence in the patent is also given (SEQID: 6). Aaa = alpha-amino acid. The uncommon amino acids in positions 887 and 890 are not defined in the patent. REGISTRY File
Nucleic acid sequence RN 261891-06-9 REGISTRY CN DNA, d(P-thio)(A-T-G-C-T-T-C-T-G-A-T-T-T-A-T-C-T-C-A-T) (9CI) (CA INDEX NAME) OTHER NAMES: CN 17: PN: US6043091 TABLE: 1 claimed DNA CN ISIS 104071 FS NUCLEIC ACID SEQUENCE SQL 20 NA 4 a 4 c 2 g 10 t NTE singlestranded modified --------------------------------------------------------------------- type ------ location ------ description --------------------------------------------------------------------- modified link a-1 - t-2 P-thio modified link t-2 - g-3 P-thio modified link g-3 - c-4 P-thio modified link c-4 - t-5 P-thio o o o This nucleic acid has a P-thio linkage at the specified locations. REGISTRY File
Nucleic acid sequence o o o modified link t-12 - t-13 P-thio modified link t-13 - a-14 P-thio modified link a-14 - t-15 P-thio modified link t-15 - c-16 P-thio modified link c-16 - t-17 P-thio modified link t-17 - c-18 P-thio modified link c-18 - a-19 P-thio modified link a-19 - t-20 P-thio ------------------------------------------------------------ SEQ 1 atgcttctga tttatctcat MF Unspecified CI MAN SR CA LC STN Files: CA, CAPLUS, TOXLIT, USPATFULL 1 REFERENCES IN FILE CA (1967 TO DATE) 1 REFERENCES IN FILE CAPLUS (1967 TO DATE) REGISTRY File
Peptide nucleic acid sequence RN 227458-83-5 REGISTRY CN Peptide nucleic acid, (glycyl-T-A-A-A-A-A-A-T-G-A-A-T-T-T-T-T-A-A-A)-L-lys-NH2 (9CI) FS NUCLEIC ACID SEQUENCE SQL 19 NA 11 a 1 g 7 t NTE singlestranded modified ---------------------------------------------------------------------- type ------ location ------ description --------------------------------------------------------------------- modified base t-1 5'-substituted modified base a-19 3'-substituted modified base a-19 3'-deoxy --------------------------------------------------------------------- SEQ 1 taaaaaatga atttttaaa MF Unspecified CI MAN SR CA LC STN Files: CA, CAPLUS The backbone in peptide nucleic acids is made up of repeating units of various amino acids. REGISTRY File
1981-Present 40 Patent issuing authorities (see WPINDEX) High-value annotation and abstracts Over 1,600,000 sequences taken from over 50,000 individual patents (basic patents) DGENE File
DGENE contains titles, patent information, assignee codes from WPINDEX DGENE can be viewed as a biosequence registry for WPINDEX Since a patent may contain more than one sequence there will often be more than one DGENE record per WPINDEX patent record DGENE abstracts are sequence focused DGENE - WPINDEX
To retrieve the corresponding WPINDEX records from a DGENE search transfer the WPINDEX cross-reference accession numbers from DGENE (OS field) to WPINDEX (AN field) Patent family information can be displayed directly in DGENE with D FAM DGENE - WPINDEX
DGENE File
DGENE File
DGENE - WPINDEX WPINDEX accession numbers are in the OS field in DGENE and the AN field in WPINDEX. Use TRANSFER to crossover between the two files => FILE DGENE => S HUMAN AND MDM2 543790 HUMAN 911 MDM2 L1 836 HUMAN AND MDM2 => FILE WPINDEX => TRA L1 1- OS /AN L2 TRANSFER L1 1- OS : 30 TERMS L3 30 L2/AN => D IFULLG Here, 836 DGENE sequence records correspond to 30 WPINDEX patent family records
GenBank is part of REGISTRY GENBANK, DGENE and REGISTRY * * *Early February 2002
August 2001-Present WIPO Over 1,500,000 (300,000 poplypeptides) sequences taken from patents electronically submitted by applicants. PCTGEN File
PCTGEN File => fil pctgen FILE 'PCTGEN' ENTERED AT 05:40:44 ON 04 MAY 2003 COPYRIGHT (C) 2003 WIPO FILE LAST UPDATED: 28 APR 2003 <20030428/UP> PCTGEN CURRENTLY CONTAINS 1,597,591 BIOSEQUENCES >>> DOWNLOAD THE PCTGEN WORKSHOP MANUAL: http://www.stn-international.de/training_center/bioseq/pctgen_wm.pdf >>> DOWNLOAD COMPLETE PCTGEN HELP AS PDF: http://www.stn-international.de/training_center/bioseq/pctgen_help.pdf >>> DOWNLOAD RUN BLAST/GETSIM FREQUENTLY ASKED QUESTIONS: http://www.stn-international.de/service/faq/dgenefaq.pdf
PCTGEN File ACCESSION NUMBER: 2003000906.1389 DNA PCTGEN TITLE: PLANT DISEASE RESISTANCE GENES PATENT ASSIGNEE: Syngenta Participations AG PATENT INFO: WO 2003000906 20030103 REL APPL INFO: US 2001-300112P 20010622; US 2001-325277P 20010926; US 2002-366535P 20020322 FILE UPDATE DATE: 20030117 DOCUMENT TYPE: Patent ORGANISM: Oryza sativa SEQUENCE LENGTH: 690 SEQUENCE 1 atggagcaca gcttcaaaac cataacagct ggagtggtgt tcgtcgtgct 51 gctcctgcag caggcgcccg tgctgattcg ggccaccgac gcggaccctc . . . . . . . . . . . . . . . . . . . . . . . . . . . . FEATURE TABLE: Key |Location | ============+============+======================= CDS |(1)..(687) | misc_feature|(588)..(588)|n = a, t, g , or c
PCTGEN File (1) Accession Number (AN). This includes the sequence (SEQ ID) number. For example, AN 2003000906.1389 is SEQ ID 1389 from WO2003000906 (2) Original PCT Application title for the overall invention (3) Patent bibliographic information: Patent Assignee (PA), Publication Number (PN) and, where given, Related Application Number (RLN) and/or Application Number (AP) (4) Organism name (ORGN) providing the name of the species from which the sequence derives (5) Sequence Length (SQL). This is a full numeric search field. (6) The sequence (SEQ) represented with one letter codes (follows WIPO standard WST.25). Non-standard nucleotides are indicated with N. Uncommon amino acids are indicated with X. (7) Feature table (FEAT) describing the modifications and features of sequence, as given by the patent applicant Each record in PCTGEN represents a single sequence. As such here will often be more than one PCTGEN record per patent document, e.g. in the PCT full-text file on STN
Name, Dictionary, Structures searching Specific Code Match (SCM) searching Similarity (homology) searching Searching methods
CAS Index names All substances are given standardised names (plus common names), available in Registry Bioscience file cluster 60 databases with bioscience content Searchable simultaneously STNindex can be used to investigate Name Searching
Name Searching Use CA Index Nomenclature and preferred terminology to locate biosequences of interest
Name Searching • Biosequence records in REGISTRY contain nomenclature which can be used to find sequences of interest. REGISTRY records may contain • Systematic names • Derivative names based on a known peptide • Biological names, with biological function, source organism, and gene/strain/clone designation • Trade names • Common names • GenBank accession numbers
Name Searching RN 12629-01-5 REGISTRY CN Somatotropin (human) (9CI) (CA INDEX NAME) OTHER NAMES: CN 3: PN: WO0030587 SEQID: 1 claimed protein CN Bio-Tropin CN CB 311 CN Corpormon CN Crescormon CN Genotropin CN Growth hormone (human pituitary) CN Human growth hormone o o o CN PN: US5958879 TABLE: 5 claimed protein CN Saizen CN SJ 0011 CN Somatogen CN Somatotropin (human) CN Somatropin CN SR 29001 FS PROTEIN SEQUENCE SQL 191 (continued on next page)
Name Searching NTE ------------------------------------------------------------------- type ------ location ------ description ------------------------------------------------------------------- bridge Cys-53 - Cys-165 disulfide bridge bridge Cys-182 - Cys-189 disulfide bridge ------------------------------------------------------------------- SEQ 1 FPTIPLSRLF DNAMLRAHRL HQLAFDTYQE FEEAYIPKEQ KYSFLQNPQT 51 SLCFSESIPT PSNREETQQK SNLELLRISL LLIQSWLEPV QFLRSVFANS 101 LVYGASDSNV YDLLKDLEEG IQTLMGRLED GSPRTGQIFK QTYSKFDTNS 151 HNDDALLKNY GLLYCFRKDM DKVETFLRIV QCRSVEGSCG F DR 11145-52-1 MF Unspecified CI MAN LC STN Files: ADISINSIGHT, AGRICOLA, ANABSTR, BIOBUSINESS, BIOSIS, BIOTECHNO, CA, CANCERLIT, CAPLUS, CASREACT, CBNB, CEN, CHEMCATS, CHEMLIST, CIN, CSCHEM, DDFU, o o o 1017 REFERENCES IN FILE CA (1967 TO DATE) 89 REFERENCES TO NON-SPECIFIC DERIVATIVES IN FILE CA 1019 REFERENCES IN FILE CAPLUS (1967 TO DATE)
Name Searching CAS assigns names to protein and nucleic acid sequences according to the following guidelines:
Name Searching CAS assigns names to protein and nucleic acid sequences according to the following guidelines:
Name Searching • Biosequence name searching has many applications. It can be used to find specific sequences, as well as to refine subsequence searches. Three techniques will be highlighted: • Chemical name searching for specific, precisely defined biosequence names, such as trade names and common names • Controlled term searching for certain classes of proteins • Combination strategies - combining sequence searching with controlled term or name fragment searching
Name Searching • The REGISTRY file is very useful for finding sequences for very specific proteins or nucleic acids. Access to the biosequence records is possible using • Common names • Trade names • Systematic names • In almost all cases, it is necessary to identify first the preferred CA Index Name of the biosequence.