Download

1 / 35
350 likes | 367 Views
Explore the challenges and optimizations of RPC for scalable distributed systems, focusing on latency impacts and the U-Net architecture. Learn about microkernels, overhead reduction strategies, and U-Net's user-level network interface design.

E N D
“Lightweight Remote Procedure Call” (1990) Brian N. Bershad, Thomas E. Anderson, Edward D. Lazowska, Henry M. Levy (University of Washington) “U-Net: A User-Level Network Interface for Parallel and Distributed Computing” (1995) Thorsten von Eicken, Anindya Basu, Vineet Buch, Werner Vogels (Cornell University) Dan Sandler • COMP 520 • September 9, 2004 Optimizing RPC
Review: Scalability • Scalable systems distribute work along an axis that can scale without bound • e.g., Number of CPUs, machines, networks, … • Distributed work requires coordination • Coordination requires communication • Communication is slow
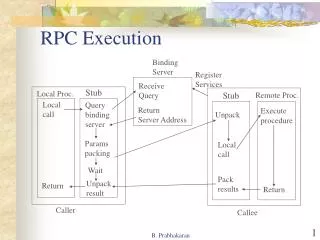
Review: RPC • Remote procedure call extends the classic procedure call model • Execution happens “elsewhere” • Goal: API transparency • Communication details are hidden • Remember, RPC is just a part of a distributed system • Solves only one problem: communication
Performance: A war on two fronts • Conventional RPC • Procedure calls between hosts • Network communication (protocols, etc.) hidden from the programmer • Performance obstacle: the network • Local RPC • Processes cannot communicate directly • Security, stability • The RPC abstraction is useful here too • Performance obstacle: protection domains
Overview • Two papers, addressing these RPC usage models • What is the common case? • Where is performance lost? • How can we optimize RPC? • Build the system • Evaluate improvements
The Remote Case • “U-Net”. Von Eicken, et al., 1995. • Historically, the network is the bottleneck • Networks getting faster all the time • Is RPC seeing this benefit?
Message latency • End-to-end latency • (network latency) + (processing overhead) • Network latency • Transmission delay • Increases with message size • Faster networks address this directly • Processing overhead • At endpoints, in hardware & software • Faster networks don't help here
Latency Observations • Network latency • Impact per message is O(message size) • Dominant factor for large messages • Processing overhead • Impact is O(1) • Dominant for small messages
Impact on RPC • Insight:Applications tend to use small RPC messages. • Examples • OOP (messages between distributed objects) • Database queries (requests vs. results) • Caching (consistency/synch) • Network filesystems
Poor network utilization Per-message overhead at each host + Most RPC clients use small messages = Lots of messages = Lots of host-based overhead = Latency & poor bandwidth utilization
Review: the microkernel OS • Benefits: • Protected memory provides security, stability • Modular design enables flexible development • Kernel programming is hard, so keep the kernel small Application OS services Small kernel
Review: the microkernel OS • Drawback: • Most OS services are now implemented in other processes • What was a simple kernel trap is now a full IPC situation • Result: overhead Application OS services Small kernel
Overhead hunting • Lifecycle of a message send • User-space application makes a kernel call • Context switch to kernel • Copy arguments to kernel memory • Kernel dispatches to I/O service • Context switch to process • Copy arguments to I/O process space • I/O service calls network interface • Copy arguments to NI hardware • Return path is similar • This all happens on the remote host too
U-Net design goals • Eliminate data copies & context switches wherever possible • Preserve microkernel architecture for ease of protocol implementation • No special-purpose hardware
U-Net architecture App App App App App Microkernel µK COMMUNICATION CONNECTION SETUP IO service Network interface Network interface Traditional RPC U-Net RPC
U-Net architecture summary • Implement RPC as a library in user space • Connect library to network interface (NI) via shared memory regions instead of kernel calls • App & NI poll & write memory to communicate — fewer copies • NI responsible for routing of messages to/from applications • Kernel involved only for connection setup — fewer context switches
U-Net implementations • Simple ATM hardware: Fore SBA-100 • Message routing must still be done in kernel (simulated U-Net) • Proof-of concept & experimentation • Programmable ATM: Fore SBA-200 • Message multiplexing performed on the board itself • Kernel uninvolved in most operations • Maximum benefit to U-Net design
U-Net as protocol platform • TCP, UDP implemented on U-Net • Modular: No kernel changes necessary • Fast: Huge latency win over vendor's TCP/UDP implementation • Extra fast: Bandwidth also improved over Fore TCP/UDP utilization
U-Net: TCP, UDP results • Round trip latency (µsec)vs. packet size (bytes)on ATM • U-Net roughly 1/5 of Fore impl. latency
U-Net: TCP, UDP results • Bandwidth (Mbits/sec)vs. packet size (bytes)on ATM • Fore maxes at 10 Mbyte/sec • U-Net achieves nearly 15
Active Messages on U-Net • Active Messages: Standard network protocol and API designed for parallel computation • Split-C: parallel programming language built on AM • By implementing AM on U-Net, we can compare performance with parallel computers running the same Split-C programs.
Active Messages on U-Net • Contenders • U-Net cluster, 60 MHz SuperSparc • Meiko CS-2, 40 MHz SuperSparc • CM-5, 33 MHz Sparc-2 • Results: U-Net cluster roughly competitive with supercomputers on a variety of Split-C benchmarks • Conclusion: U-Net a viable platform for parallel computing using general-purpose hardware
U-Net design goals: recap • Eliminate context switches & copies • Kernel removed from fast paths • Most communications can go straight from app to network interface • Preserve modular system architecture • “Plug-in” protocols do not involve kernel code • (Almost) no special-purpose hardware • Need programmable controllers with fancy DMA features to get the most out of U-Net • At least you don't need custom chips & boards (cf. parallel computers)
Local RPC Model: inter-process communicationas simple as a function call User process User process OS Service OS Service OS Service Kernel
A closer look Reality: the RPC mechanism is heavyweight • Stub code oblivious to the local case • Unnecessary context switching • Argument/return data copying • Kernel bottlenecks User process User process OS Service OS Service OS Service
Slow RPC discourages IPC System designers will find ways to avoid using slow RPC even if it conflicts with the overall design... User process User process Larger, more complex OS service OS service folded into kernel
Monolithic Kernel Slow RPC discourages IPC ...or defeats it entirely. User process User process
Local RPC trouble spots • Suboptimal parts of the code path: • Copying argument data • Context switches & rescheduling • Copying return data • Concurrency bottlenecks in kernel • For even the smallest remote calls, network speed dominates these factors • For local calls ... we can do better
LRPC: Lightweight RPC • Bershad, et al., 1990. • Implemented within the Taos OS • Target: multiprocessor systems • Wide array of low-level optimizations applied to all aspects of procedure calling
Guiding optimization principle • Optimize the common case • Most procedure calls do not cross machine boundaries (20:1) • Most procedure calls involve small parameters, small return values (32 bits each)
LRPC: Key optimizations • Threads transfer between processes during a call to avoid full context switches and rescheduling • Compare: client thread blocks while server thread switches in and performs task • Simplified data transfer • Shared argument stack; optimizations for small arguments which can be byte-copied • Simpler call stubs for simple arguments thanks to (b) • Many decisions made at compile time • Kernelbottlenecks reduced • Fewer shared data structures
LRPC: Even more optimizations • Shared argument memory allocated pairwise at bind time • Saves some security checks at call-time, too • Arguments copied only once • From optimized stub into shared stack • Complex RPC parameters can be tagged as “pass through” and optimized as simple ones • e.g., a pointer eventually handed off to another user process • Domains are cached on idle CPUs • A thread migrating to that domain can jump to such a CPU (where the domain is already available) to avoid a full context switch
LRPC Performance vs. Taos RPC • Dispatch time: 1/3 • Null() • LRPC: 157 microsec • Taos: 464 microsec • Add(byte[4],byte[4]) -> byte[4] • LRPC: 164; Taos: 480 • BigIn(byte[200]) • LRPC: 192; Taos: 539 • BigInOut(byte[200]) -> byte[200] • LRPC: 227; Taos: 636
LRPC Performance vs. Taos RPC • Multiprocessor performance: substantial improvement 25 LRPC 1000 calls/sec (as measured) 15 5 Taos RPC 1 2 3 4 # of CPUs
Common Themes • Distributed systems need RPC to coordinate distributed work • Small messages dominate RPC • Sources of latency for small messages • Cross-machine RPC: overhead in network interface communication • Cross-domain RPC: overhead in context switching, argument copying • Solution:Remove the kernel from the fast path