Download
1 / 1
10 likes | 105 Views
Smart MPI Intra-node Communication among Multicore and Manycore Machines Teng Ma, George Bosilca, Aurelien Bouteiller and Jack J. Dongarra.

E N D
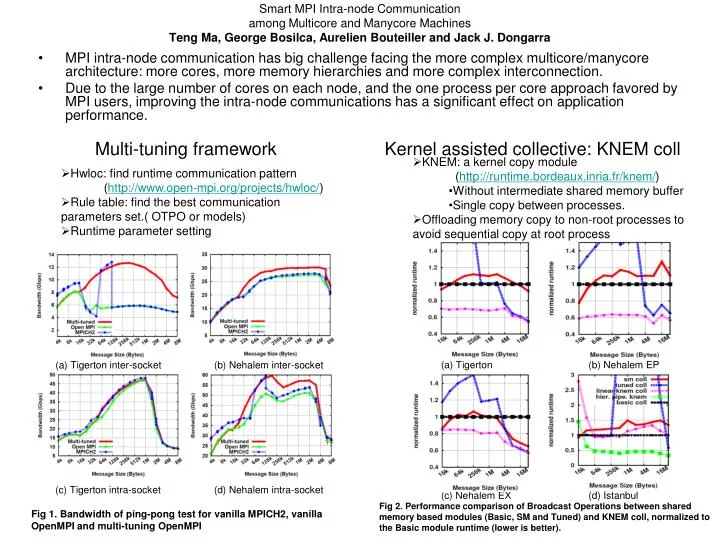
Smart MPI Intra-node Communicationamong Multicore and Manycore Machines Teng Ma, George Bosilca, Aurelien Bouteiller and Jack J. Dongarra • MPI intra-node communication has big challenge facing the more complex multicore/manycore architecture: more cores, more memory hierarchies and more complex interconnection. • Due to the large number of cores on each node, and the one process per core approach favored by MPI users, improving the intra-node communications has a significant effect on application performance. Multi-tuning framework Kernel assisted collective: KNEM coll • KNEM: a kernel copy module (http://runtime.bordeaux.inria.fr/knem/) • Without intermediate shared memory buffer • Single copy between processes. • Offloading memory copy to non-root processes to avoid sequential copy at root process • Hwloc: find runtime communication pattern (http://www.open-mpi.org/projects/hwloc/) • Rule table: find the best communication parameters set.( OTPO or models) • Runtime parameter setting (a) Tigerton (b) Nehalem EP (a) Tigerton inter-socket (b) Nehalem inter-socket (c) Tigerton intra-socket (d) Nehalem intra-socket (c) Nehalem EX (d) Istanbul Fig 2. Performance comparison of Broadcast Operations between shared memory based modules (Basic, SM and Tuned) and KNEM coll, normalized to the Basic module runtime (lower is better). Fig 1. Bandwidth of ping-pong test for vanilla MPICH2, vanilla OpenMPI and multi-tuning OpenMPI