Download

1 / 19
190 likes | 326 Views
Crawlers and Crawling Strategies. CSCI 572: Information Retrieval and Search Engines Summer 2010. Outline. Crawlers Web File-based Characteristics Challenges. Why Crawling?. Origins were in the web Web is a big “spiderweb”, so like a a “spider” crawl it

E N D
Crawlers and Crawling Strategies CSCI 572: Information Retrieval and Search Engines Summer 2010
Outline • Crawlers • Web • File-based • Characteristics • Challenges
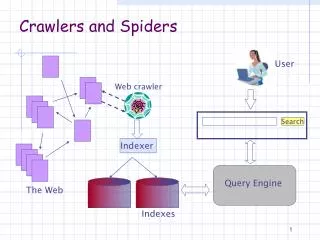
Why Crawling? • Origins were in the web • Web is a big “spiderweb”, so like a a “spider” crawl it • Focused approach to navigating the web • It’s not just visit all pages at once • …or randomly • There needs to be a sense of purpose • Some pages more important or different than others • Content-driven • Different crawlers for different purposes
Different classifications of Crawlers • Whole-web crawlers • Must deal with different concerns thanmore focused vertical crawlers, or content-based crawlers • Politeness, ability to mitigate any and all protocols defined in the URL space • Deal with URL filtering, freshness and recrawling strategies • Examples: Heretix, Nutch, Bixo, crawler-commons, clever uses of wget and curl, etc.
Different classifications of Crawlers • File-based crawlers • Don’t necessitate the understanding of protocol negotiation – it’s a hard problem in its own right! • Assume that the content is already local • Uniqueness is in the methodology for • File identification and selection • Ingestion methodology • Examples: OODT CAS, scripting (ls/grep/UNIX), internal appliances (Google), Spotlight
Web-scale Crawling • What do you have to deal with? • Protocol negotiation • How do you get data from FTP, HTTP, SMTP, HDFS, RMI, CORBA, SOAP, Bittorrent, ed2k URLs? • Build a flexible protocol layer like Nutch did? • Determination of which URLs are important or not • Whitelists • Blacklists • Regular Expressions
Politeness • How do you take into account that web servers and Internet providers can and will • Block you after a certain # of concurrent attempts • Block you if you ignore their crawling desirements codified in e.g., a robots.txt file • Block you if you don’t specify a User Agent • Identify you based on • Your IP • Your User Agent
Politeness • Queuing is very important • Maintain host-specific crawl patterns and policies • Sub-collection based using regex • Threading and brute-force is your enemy • Respect robots.txt • Declare who you are
Crawl Scheduling • When and where should you crawl • Based on URL freshness within some N day cycle? • Relies on unique identification of URLs and approaches for that • Based on per-site policies? • Some sites are less busy at certain times of the day • Some sites are on higher bandwidth connections than others • Profile this? • Adaptative fetching/scheduling • Deciding the above on the fly while crawling • Regular fetching/scheduling • Profiling the above and storing it away in policy/config
Data Transfer • Download in parallel? • Download sequentially? • What to do with the data once you’ve crawled in, is it cached temporarily or persisted somewhere?
Identification of Crawl Path • Uniform Resource Locators • Inlinks • Outlinks • Parsed data • Source of inlinks, outlinks • Identification of URL protocolschema/path • Deduplication
File-based Crawlers • Crawling remote content,getting politeness down,dealing with protocols,and scheduling is hard! • Let some other componentdo that for you • CAS Pushpull great ex. • Staging areas, deliveryprotocols • Once you have the content, there is still interesting crawling strategy
What’s hard? The file is already here • Identification of which files are important, and which aren’t • Content detection and analysis • MIME type, URL/filename regex, MAGIC detection, XML root chars detection, combinations of them • Apache Tika • Mapping of identified file types to mechanisms for extracting out content and ingesting it
Quick intro to content detection • By URL, or file name • People codified classification into URLs or file names • Think file extensions • By MIME Magic • Think digital signatures • By XML schemas, classifications • Not all XML is created equally • By combinations of the above
Case Study: OODT CAS • Set of componentsfor sciencedata processing • Deals withfile-based crawling
File-based Crawler Types • Auto-detect • Met Extractor • Std Product Crawler
Other Examples of File Crawlers • Spotlight • Indexing your hard drive on Mac and making it readily available for fast free-text search • Involves CAS/Tika like interactions • Scripting with ls and grep • You may find yourself doing this to run processing in batch, rapidly and quickliy • Don’t encode the data transfer into the script! • Mixing concerns
Challenges • Reliability • If crawl fails during web-scale crawl, how do you mitigate? • Scalability • Web-based vs. file based • Commodity versus appliance • Google or build your own • Separation of concerns • Separate processing from ingestion from acquisition
Wrapup • Crawling is a canonical piece of a search engine • Utility is seen in data systems across the board • Determine what your strategy for acquisition vis a vis your processing and ingestion strategy is • Separate and insulate • Identify content flexibly