Download
1 / 19
190 likes | 280 Views
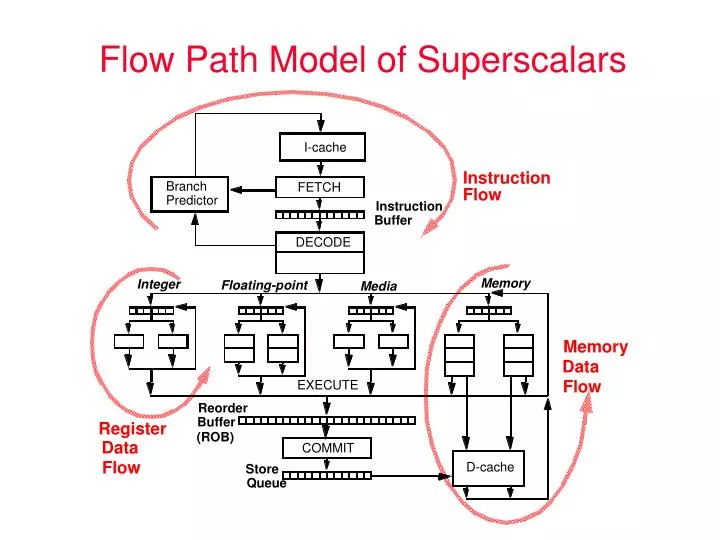
Flow Path Model of Superscalars. I-cache. Instruction. Branch. FETCH. Flow. Predictor. Instruction. Buffer. DECODE. Memory. Integer. Floating-point. Media. Memory. Data. Flow. EXECUTE. Reorder. Buffer. Register. (ROB). Data. COMMIT. Flow. D-cache. Store. Queue.

E N D
Flow Path Model of Superscalars I-cache Instruction Branch FETCH Flow Predictor Instruction Buffer DECODE Memory Integer Floating-point Media Memory Data Flow EXECUTE Reorder Buffer Register (ROB) Data COMMIT Flow D-cache Store Queue
Out-of-order Core Fetch Unit Instruction Fetch Buffer • Fetch buffer smoothes out the rate mismatch between fetch and execution • neither the fetch bandwidth nor the execution bandwidth is consistent • Fetch bandwidth should be higher than execution bandwidth • we prefer to have a stockpile of instructions in the buffer to hide cache miss latencies. This requires both raw cache bandwidth + control flow speculation
00 01 10 11 Instruction Cache Basic 000 001 Row Decoder 111 PC=..xxRRRCC00 Mutiplexer Instruction example: 4 instructions per cache line
Spatial Locality and Fetch Bandwidth 00 01 10 11 000 001 Row Decoder 111 PC=..xxRRRCC00 Inst0 Inst1 Inst2 Inst3
Fetch Group Miss Alignment 00 01 10 11 000 001 Row Decoder 111 PC=..xx0000100 Inst0 Inst1 Inst2 Cycle i Cycle i+1 Inst3??
IFAR T T T logic logic logic Odd Directory 0 A0 B0 0 A1 B1 0 A2 B2 0 A3 B3 Sets 1 A4 B4 1 A5 B5 1 A6 B6 1 A7 B7 A & B A11 2 A8 B8 2 A9 B9 2 A10 B10 2 B11 TLB hit 3 A12 B12 3 A13 B13 3 A14 B14 3 A15 B15 and buffer control Even 255 255 255 255 Directory logic Sets mux mux mux mux A & B Instruction buffer network 1 2 3 n + + + n n n n o n i n n t o o o c i D Interlock, t i i u t t c r c c u dispatch, t u u s r D r r t b r a n c h , n t t s I s s n execution, n n I D I I logic D IBM RS/6000 Auto-alignment - 2-way set associative I-Cache, 8 256-inst SRAM modules - 16 instruction per cache line (**What is a cache line?)
Instruction Decoding Issues • Primary tasks: • Identify individual instructions • Determine instruction types • Detect inter-instruction dependences • Two important factors: • Instruction set architecture • Width of parallel pipeline
Intel Pentium Pro Fetch/Decode Unit x86 Macro-Instruction Bytes from IFU To Next Instruction Buffer 16 bytes Address Calc. Decoder Decoder Decoder uROM 0 1 2 Branch Address Calc. 4 uops 1 uop 1 uop uop Queue (6) Up to 3 uops Issued to dispatch
Byte1 Byte2 Byte8 • • • 5 Bits 5 Bits 5 Bits Byte2 Byte1 Byte8 • • • Predecoding in the AMD K5 From Memory 8 Instruction Bytes 64 Predecode Logic 8 Instr. Bytes + 64 + 40 Predecode Bits I-Cache 16 Instr. Bytes + 128 + 80 Predecode Bits Decode, Translate and Dispatch ROP2 ROP1 ROP3 ROP4 Predecoding is also useful for RISC ISAs!! Cost: cache size, refill time Up to 4 ROP’s
IBM’s Experience on Pipelined Processors [Agerwala and Cocke 1987] • Code Characteristics (dynamic) • loads - 25% • stores - 15% • ALU/RR - 40% • branches - 20% • 1/3 unconditional (always taken) unconditional - 100% schedulable • 1/3 conditional taken • 1/3 conditional not taken conditional - 50% schedulable
Control Flow Graph • Shows possible paths of control flow through basic blocks • Control Dependence • Node X is control dependant on Node Y if the computation in Y determines whether X executes
A B C D Mapping CFG toLinear Instruction Sequence A A C B D D B C
Branch Types and Implementation • Types of Branches • Conditional or Unconditional? • Subroutine Call (aka Link), needs to save PC? • How is the branch target computed? • Static Target e.g. immediate, PC-relative • Dynamic targets e.g. register indirect • Conditional Branch Architectures • Condition Code ‘N-Z-C-V’ e.g. PowerPC • General Purpose Register e.g. Alpha, MIPS • Special Purposes register e.g. Power’s Loop Count
What’s So Bad About Branches? • Performance Penalties • Use up execution resources • Fragmentation of I-Cache lines • Disruption of sequential control flow • Need to determine branch direction (conditional branches) • Need to determine branch target Robs instruction fetch bandwidth and ILP
Riseman and Foster’s Study • 7 benchmark programs on CDC-3600 • Assume infinite machine: • Infinite memory and instruction stack, register file, fxn units Consider only true dependency at data-flow limit • If bounded to single basic block, i.e. no bypassing of branches maximum speedup is 1.72 • Suppose one can bypass conditional branches and jumps (i.e. assume the actual branch path is always known such that branches do not impede instruction execution) Br. Bypassed: 0 1 2 8 32 128 Max Speedup: 1.72 2.72 3.62 7.21 24.4 51.2