Download
1 / 57
570 likes | 585 Views
Explore the challenges and advancements in visual speech recognition using lip-reading and facial expression analysis. Learn about the benefits of combined audio and visual signals for enhanced speech recognition accuracy.

E N D
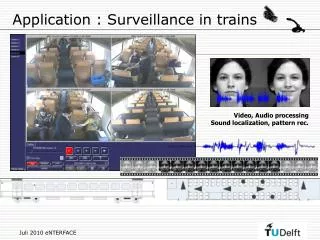
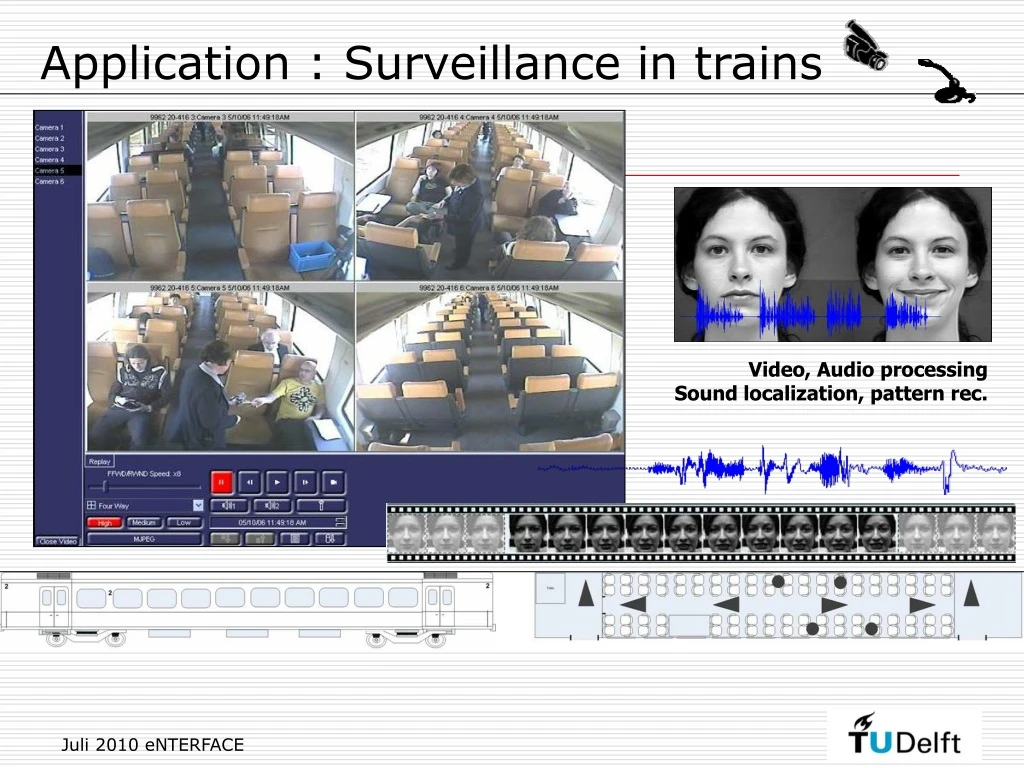
Application : Surveillance in trains Video, Audio processing Sound localization, pattern rec.
Model based approach Automatic recognition of facial expressions and lipreading using vector flow Lip reading Facial expression recognition
What makes visual speech recognition so hard? • Visemes Smaller word separability • Speech info in audio > Speech info in video
Lip-reading by Humans • People recognize speech better when the signal is both auditory and visual • The difference inrecognition ratesgrows with thelevel of noise inthe environment
Inspiration • In the 1968 Stanley Kubrick film 2001: A space odyssey the computer reads from the lip-movements the conversation of two astronauts. • Thirty years later automated lip-reading becomes a significant part of research in speech recognition systems.
AV speech corpus New speech corpus
AV speech corpus Recording a new speech corpus Applications|Problem|ASR|VSR|Training|Analysis|Conclusion|Recommendations Visemes|Corpus|Tracking|Features
AV speech corpus Recording a new speech corpus Applications|Problem|ASR|VSR|Training|Analysis|Conclusion|Recommendations Visemes|Corpus|Tracking|Features
AV speech corpus New speech corpus • Dutch • Recorded at high-speed: 100 fps • Front and profile views included • 70 people • 49 male, 21 female • Students, professors, secretaries, friends • Utterances: • Sentences, digits, spelling, conversation starters/endings, open questions • Normal, fast, whispering Applications|Problem|ASR|VSR|Training|Analysis|Conclusion|Recommendations Visemes|Corpus|Tracking|Features
AV speech corpus New speech corpus Applications|Problem|ASR|VSR|Training|Analysis|Conclusion|Recommendations Visemes|Corpus|Tracking|Features
Lip-reading by Humans • People recognize speech better when the signal is both auditory and visual • The difference inrecognition ratesgrows with thelevel of noise inthe environment
Active Contours • Internal and external energies • Internal energy forces contour to shrink • Locally defined external energy forces the contour to stop at the edge of the mouth • Computationally cheap • Sensitivity to initial setting of the contour 13 13 13 11 10 13 12 9 8 8 11 10 8 7 7 6 10 9 7 6 5
Template Matching • Internal and external energies • Internal energy forces template to maintain geometry • Globally defined external energy forces appropriate placement on the picture • Better results than with snakes • Integration of energy functions at each step can be very time consuming
Model • Goal: lip-reading • Needed: • accurate description of visible parts of articulatory system • Accurate description of the shape of the mouth: • measurements of the distance of the lip to a center of the mouth • measurements of thickness of visible part of the lips
Data processing (continued) • Filtered image • intensity distribution • center of mouth • Image in polar coordinates • Conditional distribution • Mean and variance functions
Data visualization • Single frame data vector:
Results of Experiments • Feed Forward BP Vanmiddag komt de pianostemmer langs om mijn vleugel te stemmen
Face tracking Tracking the face – Optical flow • Capturing apparent motion of subsequent images in a grid of motion vectors • Advantages • No lip model required • Good at capturing motion • Disadvantage • Slow
Face tracking Tracking the face – Lip Geometry Estimation • Applying some color filters and capturing the lip contours in polar coordinates • Advantages • No lip model required • More or less person-independent • Disadvantage • Not robust to external factors
Face tracking Tracking the face – Active Appearance Models • Point tracking according to a statistical lip model • Disadvantage • Requires annotated training • images • Advantages • Robust against external • factors • Fast!
Face tracking Active Appearance Models – Design of the lip model
Face tracking AAM model point coordinates
Feature extraction Features plotted for“F” time (frames)
Model based approach Automatic recognition of facial expressions using active Appearance model Automatic bi-modal human emotion recognition
M.A.E.L.I.A. Our digital cat H.C.I. Group
Requirements in other words… Get a life! I am still sleeping! AIBO! Let’s play!!! Follow me Are you out of your mind? I am sleeping!!! AIBO! Bring me my newspaper!!! 8:00 AM 7:00 AM I am so bored! I wish I had a companion! I feel so lonely!!! I am very sad and depressed. AIBO! Let’s play!!! Follow me Finally I have a friend! I am so happy and I even managed to pick up the bone! Wow!!! 11:00 AM 14:00 AM 16:00 AM
Multimodal Communication Uh, what a nerd I want a date She looks nice Uh, …. I have no time to do anything with you Hello, do you like to chat with me ?
Chat-session • A cup of tea? • Mmh, njeh, I don’t like tea. • What’s wrong with tea? • Tea makes me sick. • That’s nonsense!! • And my sister doesn’t like you too! • She is very disappointed!! • Hihi, I was joking!!! • Oh, that’s funny!!!
Chat-session • (f) A cup of tea? : - ) • (m) Mmh, njeh, I don’t like tea. (: - ( • (f) What’s wrong with tea? : - o • (m) Tea makes me sick. % - \ • (f) That’s nonsense!! : - l l • (f) My sister doesn’t like you too! : - l l • (f) She is very disappointed!! : - ( • (m) Hihi, I was joking!!! ; - ) • (f) Oh, that’s funny!!! : - ]
A cup of tea? : - )
Mmh, njeh, I don’t like tea. (: - (