Download

1 / 13
130 likes | 250 Views
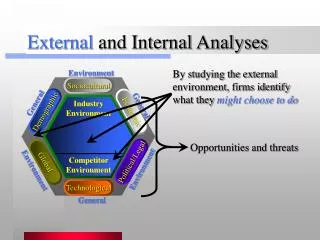
External and internal data traffic in Tier-2 ATLAS farms. Sketch of farm organization. Some approximate estimate s of internal and external data flows in ATLAS Ru-Tier-2 farms are done as well as proposal on possible organization of such a farm to fulfill needed requirements A.Minaenko, IHEP.

E N D
External and internal data traffic in Tier-2 ATLAS farms.Sketch of farm organization Some approximate estimate s of internal and external data flows in ATLAS Ru-Tier-2 farms are done as well as proposal on possible organization of such a farm to fulfill needed requirements A.Minaenko, IHEP
Estimate of the External Traffic • Main data flow goes from ATLAS Tier-1 (SARA) to Ru-Tier-2 • Reverse data flow is considerably smaller and does not create any problems • The data flow consists of AOD, DPD mainly which are firstly transmitted right after first data reconstruction, practically on-line • The AOD are re-reconstructed periodically and new versions of AOD based on the same raw data replace the previous versions, so each AOD is transmitted several times per year • Factors on which the external traffic depends are: • AOD event size – 200 KB now (to be 100-150 KB according to official ATLAS Computing TDR) • ATLAS DAQ rate – 200 Hz, i.e. 200 events are written down each a second • Repetition rate, i.e. number of AOD replacements after re-reconstruction – estimated value of 4-5 times • Finally the estimate of the external traffic is • 200 Hz * 200 KB * 5 times = 200 MB/sec = 1.6 Gbps • This is aggregated external traffic for all Ru-tier-2 sites • The estimate is true for 100% efficiency of LHC operation but really the value hardly will be larger 50% and in the nearest 2 years it will be significantly less • Hardly the external connectivity will create any problems in the nearest future A.Minaenko
Estimate of the Internal Traffic • The main challenge for Tier-2 farms providing LHC data analysis is a huge internal traffic. The data fetched to the site SE once are used then many times by numerous analysis jobs • Important feature: the data flow is one directional SE→WNs. A standard ATLAS analysis job during STEP09 took 5-30 GB of input data from SE and at the end saved to the SE about 100-200 MB only (logfile, ROOT file with histograms) • This is illustrated by the lower figure which shows in/outbound traffic for one of fileservers of the IHEP SE during STEP09. Average inbound traffic (13 Mbps) is about 20 times less than outbound one (230 Mbps) A.Minaenko
Estimate of the Internal Traffic • Estimate from WNs side. During STEP09 frequency of event handling by analyzing jobs was lower 10 Hz in the mean (using standard modern CPU of 2.5 kSI2k). But at some best sites it was about 20 Hz. Taking this value as reference one and AOD event size of 200 KB one obtains data flow estimate for one CPU 20*200 KB = 4 MB/sec. For a example farm with 1000 cores this will require a data flow of 4 GB/sec = 32 Gbps. This gives reference value which can be scaled according the real number of cores for a given farm • Estimate from SE side. The maximal data flow provided by SE is equal to Bw*N, here Bw is a bandwidth of output from a single fileserver of the SE and N is a total number of fileservers in the SE. If one takes standard Bw equal to 1 Gbps (one Ethernet card) then for SE consisting of 30 fileservers (as in RRC-KI) one will obtain 30 Gbps • It is necessary to take in to account that • the estimate from the WNs side is the mean value and peak value may be considerably larger • the estimate from the SE side is the maximally reachable value • these two values should be kept comparable. So, if, for instance ,the first value is considerably larger than the second one, it will require additional limitation of the number of running analysis jobs. Comparable does not mean equal: may be reasonable ratio is about A = 0.5*B • The design of any farm networking should be done by such a way that there should not be any bottlenecks creating additional limitations of the above estimates A.Minaenko
Sketch of possible farm organization • Just two general principles • To permit high internal traffic a farm should have ONE central switch. If there are more than one the links between them will create bottlenecks because they always be weaker then the internal bus of a switch or a stack • The ports of this central switch must be used with maximal possible efficiency as this can define maximal reachable bandwidth for the internal traffic. Usually the ports are duplex, i.e. each of them is able to transmit simultaneously 1 Gbps in and 1Gbps out and this feature must be used. If, for instance, some port will be used for connection with WNs (SE) only then this feature will not be used and the SE->WNs bandwidth will degrade • The internal bus of a standard 48 port switch (which are available in all our T2 sites – ProCurve 2810-48G) is able to transmit 96 Gbps traffic. As half of the traffic is in and the other half is out this means that, in principle, maximal SE->WNs bandwidth reachable on the base of such a switch is 48 Gbps. This value is sufficient for all our present T2 sites and I think will be sufficient in the next 2-3 years. It is necessary just realize such a bandwidth A.Minaenko
Sketch of possible farm organization • So, possible simplified sketch of T2 networking can look as following • 48 port switch is used as a central switch • 10 (for instance) 24 port switches of the same type is used as the first level switches • The example usage of the ports of such a first level switch can be: • 3 ports for 3 fileservers of the SE • 3 ports for connection with the central switch • 18 ports for 18 WNs (4 or 8 cores each) • Number of ports for fileservers is equal to the number of ports for connection with the central switch thus not limiting the output bandwidth the fileservers • The same 3 ports will be used for opposite direction data flow to supply WNs from the central switch • Thus such an example farm will have SE of 30 fileservers, 180 WNs of about 1000 cores and 30 Gbps SE->WNs bandwidth. Only 30 ports of the central switch are used giving possibility for some farm extension • In principle, 96 port switch can be used as the central switch • As well as 48 or 96 port switches (even better) can be used as first level switches A.Minaenko
Example farm: LAPP & TOKIO • Next slides illustrates several farm designs shown at the ATLAS STEP09 wash-up. Does not mean that they a good examples to follow, just F.Y.I. A.Minaenko
Example farm: LAPP A.Minaenko
Example farm: TOKIO A.Minaenko
Example farm: Glasgow A.Minaenko
Example farm: INFN-T1 A.Minaenko
Example farm: INFN-T1 A.Minaenko
Example farm: DESY-ZN ! A.Minaenko