Download
1 / 41
410 likes | 427 Views
What Is Signal Processing?. Signal Processing (n). (1) Conversion of a signal f(t,x,y,z) (as measured by sensors at x,y,z) to a form that’s easier to interpret or store. What Can I do with Signal Processing?.

E N D
What Is Signal Processing? Signal Processing (n). (1) Conversion of a signal f(t,x,y,z) (as measured by sensors at x,y,z) to a form that’s easier to interpret or store.
What Can I do with Signal Processing? Imaging (biomedical imaging, satellite remote sensing, distributed sensor networks, acoustic beamforming) Data Security (cryptography, watermarking) Communications (DSP implementation of modulators & error-correction codes at IF, RF, and even OF) Artificial Intelligence (computer vision, audiovisual scene understanding, speech recognition, cognitive world modeling) Data Mining (image recognition, audio recognition, audio & visual similarity measurement)
Useful Signal Processing Classes Core DSP Classes: ECE 310 (DSP), 320 (DSP Lab), 313 (Probability), 359 (Communications I) Artificial Intelligence/ Pattern Recognition DSP: ECE 302 (Music Synthesis),ECE 348 (Artificial Intelligence) ECE 370 (Robotics), ECE 386 (Controls), ECE 389 (Robot Dynamics) Communications/ Digital Modulation: ECE 338 (Communication Networks), ECE 361 (Communications II)
Where can I go with Signal Processing? Universities (Texas A&M, University of Maryland) DSP Companies (Motorola, TI) Communications Companies (Motorola, Rockwell, Boeing) Audio Companies (Shure, Nuance) Medical Imaging Companies (GE, Siemens)
I. What Can Machines Do Now? - Telephone-based Dialog Systems - Dictation for Word Processing - Speech I/O for Disabled Users - Speech I/O for Busy Users (e.g. Radiologists) - Hands-free GPS in new Jaguar
II. What Can People Do That Machines Can’t Do? - Two Voices at Once (TV is on --- why can’t I talk to my toaster?) - Reverberation (Do I need to put padding on all of the walls?) - Noise (automobile, street)
II. Example 2: Reverberation - Recorded speech equals input(t-delay 1) + input(t-delay 2) - Delays are longer than a vowel, so two different vowels get mixed together - Result: Just like 2 different speakers!!
II. Example 2: Reverberation The Only Way to Totally Avoid Reverberation:
Classification: Choose the “most probable” C C = argmax p(C|O) = argmax p(O|C) p(C) / p(O) = argmax p(O|C) p(C) p(C) --- the “language model” p(O|C) --- the “acoustic model” III. “Statistical” Speech Recognition
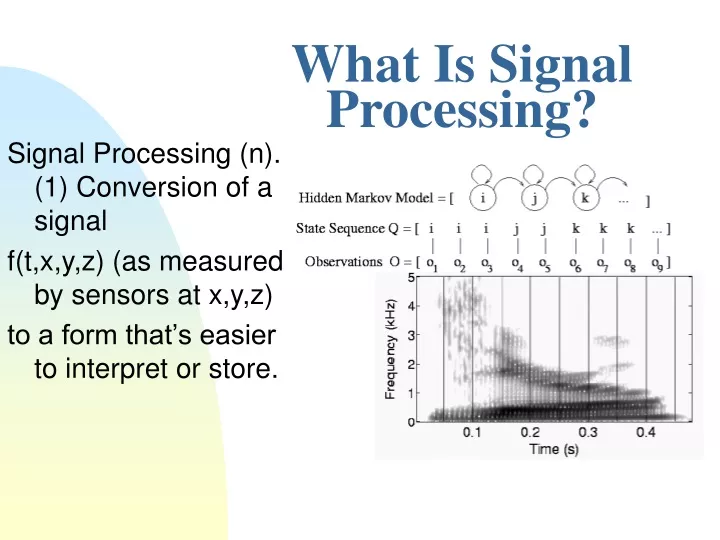
IV. Hidden Markov Model Maximize p(O,Q) = p(i) p(o1|i) p(i|i) p(o2|i) p(i|i) p(o3|i) p(j|i) p(o4|j) ...
IV. Response Generation Database Response: 12 flights Priority Ranking of Information: 1. Destination City 2. Origin City 3. Date 4. Price ….. Response Generation: “There are 12 flights tomorrow morning from Champaign to San Francisco. What price range would you like to consider?”
IV. Step 1:a. CreateAcoustic Targetsb. ConvertAcoustic Goalsto Movement Goals--- just like arobot controlproblem
IV. Step 4: Mechanical Pseudo-Fourier Transform
IV. Step 6: Beam-Forming --- Correlate Signals from 2 Ears ---
Conclusions • Telephone Speech Technology in Limited Domains works well. • Speech Recognition doesn’t understand • Multiple Voices • Reverberation • Other kinds of variability, e.g. accents • Better Speech Technology can be produced by learning from Human Speech Procesing
Background: Stop Cons. Release • Three “Places of Articulation:” • Lips (b,p) • Tongue Blade (d,t) • Tongue Body (g,k)
Problem Statement: Content of Speech is Multivariate 1. Source Information: Prosody, Articulatory Features
Content of Speech is Multivariate 2. Useful Non-Source Information: Composite Acoustic Cues
Types of Measurement Error • Small Errors: Spectral Perturbation • Large Errors: Pick the Wrong Peak Amp. (dB) Frequency (Hertz)
Large Errors are 20% of Total Std Dev of Small Errors = 45-72 Hz Std Dev of Large Errors = 218-1330 Hz P(Large Error) = 0.17-0.22 LogPDF Measurement Error (Hertz) re: Manual Transcriptions
Measurement Error Predicts Classification Error
Solution: Composite Cues as State Variables
a PosterioriMeasurement Distributions:10ms After /d/ in “dark” DFT Amplitude DFT Convexity P(F | O, Q) Frequency (0-4000 Hertz)
MRI Image Collection • GE Signa 1.5T • T1-weighted • 3mm slices • 24 cm FOV • 256 x 256 pixels • Coronal, Axial • 3 Subjects • 11 Vowels • Breath-hold in • vowel position • for 25 seconds
MRI Image Segmentation • In CTMRedit: • Manual • Seeded Region • Growing • Tested: • Snake • Structural • Saliency




















