Download

1 / 50
510 likes | 682 Views
Arquitetura IA32. Eduardo Augusto Bezerra <Eduardo.Bezerra@pucrs.br>. Resumo. Historico da arquitetura IA32 Avancos na arquitetura Tecnologia hyper pipeline Arquitetura IA32. Historico da Arquitetura IA32. 1978 – 16 bits e Segmentacao

E N D
Arquitetura IA32 Eduardo Augusto Bezerra <Eduardo.Bezerra@pucrs.br> Arquitetura IA32, Porto Alegre, Outubro de 2006
Resumo • Historico da arquitetura IA32 • Avancos na arquitetura • Tecnologia hyper pipeline • Arquitetura IA32 Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 1978 – 16 bits e Segmentacao • 8086 e 8088 sao os processadores de 16 bits antecessores a IA32 • 8086, regs 16 bits, data bus 16 bits, address 20 bits => 1 MBytes • 8088, data bus 8 bits • Segmentacao – regs de segmento de 16 bits contem ponteiro para • segmento de memoria de ate’ 64KB. Com 4 regs de segmento ao • mesmo tempo, 8086/8088 enderecam 256KB sem chavear segmentos. Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 1982 – Intel 286 – introduz modo protegido ao IA32 • Modo protegido: facilidades para multi-tarefa. Ex. Protecao memoria, • paginacao, suporte em HW para gerencia de memoria virtual. SOs tais • como Linux e Windows rodam em modo protegido. • Modo real: desabilita protecoes para permitir compatibilidade com • sw legado rodando em modo DOS. CPUs x86 iniciam em modo real, • ate’ serem chaveadas para modo protegido pelo SO no boot. • Modo real, regs de segmento na manipulacao memoria segmentada, • conteudo dos regs formam parte do endereco fisico. • Modo protegido, memoria segmentada definida por “Descriptor Tables” • Regs de segmento sao ponteiros para essas tabelas, nao sendo parte do • endereco fisico. Descriptors = end. 24 bits = 16MB mem. fisica. Arquitetura IA32, Porto Alegre, Outubro de 2006
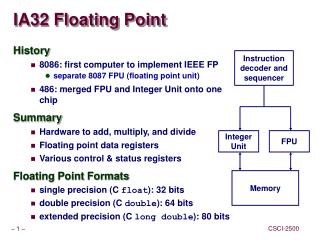
Historico da Arquitetura IA32 • 1985 – Intel 386 – primeiro proc. 32 bits da familia IA32 • Regs 32 bits para operandos e enderecamento. • Modo virtual 8086 para execucao eficiente de programas legados. • Barramento endereco 32 bits: mem. fisica 4GBytes. • Paginacao com tamanho de pagina de 4 KB, com metodo para • gerencia de memoria virtual. • Suporte para estagios paralelos. Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 1989 – Intel 486 • Pipeline com 5 estagios operando 5 instrucoes em paralelo. • Cache L1 de 8 KB para aumentar % instrucoes executadas – • Objetivo: 1 instrucao por ciclo. • FPU x87 integrada. • Facilidade para gerencia do sistema e economia de energia. Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 1993 – Intel Pentium • Segundo pipeline (arq. superescalar) para execucao de 2 instr/ciclo. • L1 cache duplicada – 8 KB dados e 8 KB instrucoes. • Predicao de desvio com tabela de desvio on-chip. • Data pahs internos de 128 e 256 bits. • Barramento de dados externo de 64 bits. • Suporte a sistemas multiprocessados – Modo dual processor. • Intel MMX: Modelo execucao SIMD (regs. SIMD de 64 bits). Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 1995 – 1999 Processadores P6 • Pentium Pro: superscalar 3-way; decodif./exec. de 3 instr./ciclo. Execucao dinamica: micro-data flow analysis, execucao fora de ordem, predicao de desvio avancada, execucao especulativa. Da mesma forma como no Pentium, 2 x 8 KB cache L1 (instr. e dados). Adicional cache L2 256 KB. • Pentium II: Tecnologia MMX. Cache L1 e L2 de 16 KB, e L2 de 256 KB, 512 KB, ou 1 MB. • Pentium II Xeon: L2 cache 2 MB. • Celeron: Encapsulamento PPGA para reducao de custo. • Pentium III: SSE SIMD Extensions do MMX – regs. de 128 bits p/ instr. SIMD. • Pentium III Xeon: Advanced transfer cache. Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 2000 – atualidade Pentium 4, 3.40 GHz • Intel NetBurst microarchitecture • Streaming SIMD Extensions 2 (SSE2). • Hyper-Threading SSE3. • Extended Memory 64 – Pentium 4 Extreme Edition. Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 2001 – atualidade, Intel Xeon • Intel NetBurst microarchitecture • Servidores multi-processados • Hyper-Threading • 64-bit Xeon 3.60 GHz – Tecnologia extended memory 64. • Dual-Core Xeon Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 2003 – atualidade, Intel Pentium M • Mobile low power • Execucao dinamica – remove dependencia de execucao sequencial, • pela combinacao de tecnicas: • Multiple branch prediction – Tenta adivinhar o fluxo do programa gerando os diversos • possiveis caminhos • Dataflow analysis – Escalona instrucoes para execucao quando prontas, sem levar • em consideracao a ordem no programa • Speculative execution – Executa instrucoes que provavelmente serao necessarias, • olhando alem do IP • Out of order execution • Super scalar • Cache L1: 32 KB instr. 32 KB dados; Cache L2 ate’ 2 MB • MMX, SIMD, e conj. instrucoes SSE2 Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 2005 – atualidade, Intel Pentium Processor Extreme Edition • Tecnologia dual-core • HW para suporte multi-thread • Intel NetBurst microarchitecture • SSE, SSE2, SSE3 • Hyper-threading • Tecnologia Intel Extended Memory 64 Arquitetura IA32, Porto Alegre, Outubro de 2006
Historico da Arquitetura IA32 • 2006 – atualidade, Intel Core Duo e Core Solo • Tecnologia dual-core com low power • Smart cache para compartilhamento eficiente entre dois cores • Decodificacao melhorada e execucao SIMD • Dynamic power e “deeper sleep” • Interfaces para sensores temperatura digitais – gerencia de temperatura Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura P6: • Pipeline do tipo “Three-way” super escalar - decodifica e executa em media tres instrucoes por ciclo • 3 “super-pipelines” com 12 estagios com suporte para execucao fora de ordem. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura Microarquitetura P6 – Advanced Transfer Cache Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura P6 – Principal: unidade exec. fora de ordem. • Alcancado com mecanismo de “execucao dinamica”. Composto por: • Deep branch prediction – processador decodifica instrucoes adiante dos desvios, mantendo pipe cheio. Algoritmos avancados de predicao de salto para prever a direcao do fluxo de execucao. • Analise dinamica do fluxo de dados – Analise em tempo real do fluxo de dados p/ determinar dependencias (hazards), e p/ detectar chances p/ execucao fora de ordem. Essa unidade monitora diversas instrucoes, e executa-as na ordem que melhor otimizara’ o uso das diversas unidades de execucao, mantendo a integridade dos dados. • Execucao especulativa – habilidade para executar instrucoes alem Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura P6 – Principal: unidade exec. fora de ordem. • Execucao especulativa (cont.) – habilidade para executar instrucoes alem de um desvio condicional, que ainda nao foi resolvido, e para gerar os resultados na ordem correta do fluxo de instrucoes original de um programa. • Para exec. especulativa e’ necessario desacoplar a execucao das instrucoes do comprometimento (geracao) dos resultados (write back). A unidade de exec. fora de ordem usa uma analise do fluxo de dados para executar todas as instrucoes disponiveis (pre-fetched) em um reservatorio, e armazena resultados em regs. temporarios. • Unidade aposentadoria (retirement) busca linearmente no reservatorio por instrucoes completadas que nao possuem mais dependencias de dados ou previsao de desvio nao-resolvida. Quando instrucoes completadas sao encontradas, unidade de aposentadoria grava esses resultados na memoria e/ou registradores do processador, na ordem em que foram geradas inicialmente, aposentando as instrucoes que estavam no reservatorio. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura Intel NetBurst • Mecanismo de execucao rapida • ULAs com velocidade duas vezes maior que a freq. do processador • Operacoes basicas com inteiros em 1/2 ciclo de clock • Maior throughput com latencia de execucao reduzida • Tecnologia hyper-pipelined • Deep pipeline • Escalabilidade • Execucao dinamica avancada • Mecanismo de execucao especulativa em profundidade, e fora de ordem • ate’ 126 instr. em execucao; ate’ 48 loads e 24 stores no pipe • Capacidade avancada para previsao de desvios • Reduz atrasos por erros na previsao; algoritmo avancado para predicao de desvio; array com destinos de desvio de 4 K posicoes. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura Intel NetBurst pipeline • 3 modulos: pipeline front-end, modulo exec. fora de ordem; unidade de aposentadoria • pipeline front-end: • Alimenta unidade de exec. fora de ordem com instrucoes na ordem em que ocorrem no programa • pre-busca instr. IA32 que devem vir a ser executadas • busca instr. que ainda nao foram buscados na pre-busca • decodifica instr. IA32 em micro-operacoes • gera microcodigo para instr. Complexas • fornece instr. decodificadas para cache de execucao • preve desvios usando algoritmos avancados Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura Intel NetBurst pipeline • pipeline front-end (cont.): • Principais problemas em pipes em geral: tempo para decodificar instr. buscadas; e desperdicio na decodificao devido a instr. de desvio na cache. • A “trace cache” do pipe resolve esses problemas. Instr. sao buscadas e decodificadas todo o tempo pelo mecanismo de traducao (logica de busca/decodificacao), e sequencias de micro operacoes (traces) sao geradas. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura Intel NetBurst pipeline • modulo de execucao fora de ordem: • Capacidade para execucao de instrucoes fora da ordem • Se uma uop foi atrasada, outras uops continuam – processador re-ordena • Modulo consegue gerenciar seis uops por ciclo, o que e’ maior que a capacidade da trace cache e da unidade de aposentadoria. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Microarquitetura Intel NetBurst pipeline • unidade de aposentadoria (retirement unit): • Recebe resultados de uops executadas, vindos da unidade de exec. fora de ordem. • Processa os resultados de forma que os estados na arquitetura correspondam a ordem do programa original • Quando uma uop completa e escreve o resultado, essa e’ aposentada. • Ate’ 3 uops por ciclo podem ser aposentadas • A unidade “buffer de re-ordenacao” (ROB) armazena uops completadas, atualiza o estado da arquitetura na ordem original, e gerencia a ordem das excessoes. • Essa unidade mantem um registro dos desvios e informa os branch target buffers (BTBs) • Os BTBs eliminam traces pre-buscados que nao sao mais necessarios. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Instrucoes SIMD • Instrucoes SIMD apareceram pela primeira vez no Pentium II e Pentium MMX • Quatro extensoes foram introduzidas na arquitetura IA-32 para possibilitar execucao do tipo “single-instruction multiple-data”: MMX, SSE, SSE2, SSE3. • Cada extensao possui um conjunto de instrucoes para realizar operacoes SIMD em dados inteiros e/ou ponto flutuante em registradores MMX de 64 bits ou XMM de 128 bits. • MMX – Pentium II e Pentium MMX, instrucoes para arrays de inteiros – SIMD • SSE – Pentium III, operam com valores inteiros e ponto flutuante precisao simples em regs. XMM. Instrucoes para gerencia de estados, controle de cache, ordenacao de memoria. Aplicacoes de geomeria 3-D, renderizacao 3-D, codificacao/decodificacao de video. • SSE2 – Pentium 4 e Xeon, inteiros em regs MMX e XMM, ponto flutuante precisao dupla em regs. XMM, operacoes com inteiros de 128 bits. • SSE3 - Pentium 4, tecnologia Hyper-Threading, 13 instr. para aumento desempenho. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura Instrucoes SIMD MMX SSE2 / SSE3 SSE Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Tecnologia Hyper-Threading (HT) • Desenvolvida para melhorar o desempenho de SOs multi-thread, e de aplicacoes executadas em ambiente multi-tarefa. • Possibilita, em hardware, que um unico processador execute duas ou mais threads concorrentemente, compartilhando recursos. • A diferenca entre tecnologia HT e multi-processamento (MP), esta’ no fato de HT utilizar um unico processador, enquanto MP usa mais de um chip em sockets diferentes. • Um processador com suporte HT consiste de 2 ou mais processadores logicos, cada qual com seu proprio estado arquitetural. • Cada processador logico possui um conjunto completo de regs IA-32 de dados, segmento, controle e debug. Possuem tambem controlador de interrupcao proprio. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura Comparacao entre Hyper-Threading (HT) e Multiprocessador Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Tecnologia Hyper-Threading (HT) • HT precisa suporte a tecnologia a nivel de processador, chipset e BIOS, e otimizacoes no sisitema operacional. • A nivel de BIOS, e’ realizada a inicializacao dos processadores logicos, de forma semelhante ao que ocorre em plataformas MP. • Um SO projetado para rodar em plataformas MP pode usar a instr. CPUID para identificar a presenca de hardware para suporte HT, e o numero de processadores logicos disponibilizados. Arquitetura IA32, Porto Alegre, Outubro de 2006
Avancos na Arquitetura • Tecnologia Multi-core • Outra forma de HT, fornecendo dois ou mais cores fisicos no mesmo chip. • Pentium Extreme Edition: primeiro IA-32 a suportar multi-core, com dois cores + HT com dois processadores logicos em cada core. Total 4 procs. Arquitetura IA32, Porto Alegre, Outubro de 2006
Pentium Pro • Diversas instruções complexas, com tamanhos variando de 1 a 15 bytes • Necessidade de recursos consideráveis de hardware para implementação da lógica de decodificação e execução de instruções • Uma única instrução pode realizar uma ou mais leituras/escritas na memória e uma ou mais operações na ULA • Desafio para execução de mais de uma instrução por ciclo em um hardware super-escalar Arquitetura IA32, Porto Alegre, Outubro de 2006
Pentium Pro • Instruções CISC obtidas da memória (geradas por compilador) são colocadas nas caches L2 e L1 – instruções possuem tamanhos variados • Arquitetura realiza tradução das instruções CISC contidas em L1, decodificando e transformando em instruções RISC de tamanho fixo(micro-operações ou uOPs) • As uOPs são colocadas em reservatório com capacidade para armazenar 40 instruções, onde aguardam para entrar no fluxo de execução • Quando os operandos necessários por uma determinada instrução estiverem disponíveis, e quando a unidade de execução a ser utilizada estiver livre, a instrução é retirada do reservatório e executada – EXECUÇÃO FORA DE ORDEM • Após execução da uOP, os resultados são escritos nos registradores, na ordem original do fluxo do programa • Esse processo é descrito a seguir, onde estágios 1 a 14 são operações do reservatório de uOPs, e do estágio 15 em diante uOPs são executadas Arquitetura IA32, Porto Alegre, Outubro de 2006
Tecnologia Hyper Pipeline TC Nxt IP: “Trace Cache Next Instruction Pointer” Ponteiro do Branch Target Buffer indica a localização da próxima uOP (já transformada p/ RISC)
Tecnologia Hyper Pipeline TC Fetch: “Trace Cache Fetch” Realiza leitura da uOP RISC na Execution Trace Cache
Tecnologia Hyper Pipeline Drive: “Atraso nos barramentos” Direciona as uOPs para a unidade de alocação
Tecnologia Hyper Pipeline Alloc: “Allocate” Alocação de recursos necessários para execução da uOP como, por exemplo, buffers para load/store, entre outros
Tecnologia Hyper Pipeline Rename: “Register renaming” Renomeia os registradores locais (EAX, ...) associando aos registradores de trabalho existentes no hardware (128 no total)
Tecnologia Hyper Pipeline Que: “Write into the uOP Queue” As uOPs são colocadas nas filas, onde permanecem até que os escalonadores estejam disponíveis
Tecnologia Hyper Pipeline Sch: “Schedule” Escrita nos escalonadores e verificação de dependências. Procura dependências a serem resolvidas
Tecnologia Hyper Pipeline Disp: “Dispatch” Envio das uOPs para a unidade de execução apropriada
Tecnologia Hyper Pipeline RF: “Register File” Leitura dos registradores, que contém os operandos das operações pendentes (operandos das ULAs, ...)
Tecnologia Hyper Pipeline Ex: “Execute” Executa as uOPs na unidade apropriada (recurso alocado)
Tecnologia Hyper Pipeline Flgs: “Flags” Cálculo dos flags (zero, negativo, ...). Flags normalmente servem de entrada para instruções de desvio.
Tecnologia Hyper Pipeline Br Ck: “Branch Check” Esse estágio compara o resultado obtido (calculado) para uma operação de desvio, com a predição realizada originalmente
Tecnologia Hyper Pipeline Drive: “Atraso no barramento” Resultado da verificação do desvio (erro ou acerto na predição) é informado para o início do processo
Arquitetura IA32 – Modos de operacao • Modo protegido: estado nativo do processador, modo multi-tarefa. • Modo real: modelo de programacao do 8086, usado para compatibilidade. Processador entra nesse modo no reset e power-up. • Modo de gerencia de sistema (SMM): usado por SOs para funcoes dependentes de plataforma, ex. gerencia de energia, seguranca do sistema, entre outros. Processador entra em SMM quando o pino externo SMI# e’ ativado. Arquitetura IA32, Porto Alegre, Outubro de 2006
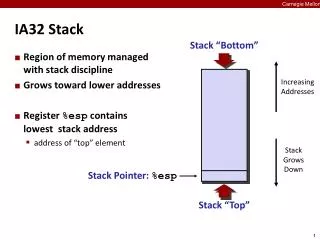
Arquitetura IA32 – Registradores • Uma tarefa pode enderecar 2^32 = 4 GB enderecamento linear, e 2^36 = 64 GB enderecamento fisico. • Uma pilha e’ utilizada para chamada e passagem de paramentos para sub-rotinas. Arquitetura IA32, Porto Alegre, Outubro de 2006
Arquitetura IA32 – Registradores • EAX – acumulador para operandos e resultados de operacoes • EBX – Ponteiro para dados no segmento de dados • ECX – Contador para operacoes com string e lacos • EDX – ponteiro para I/O • ESI – Ponteiro para dados no segmento apontado pelo reg. DS, e ponteiro origem para operacoes string • EDI – Ponteiro para dados no segmento apontado pelo reg. ES, e ponteiro destino para operacoes string • ESP – Ponteiro para pilha (segmento SS) • EBP – Ponteiro para dados na pilha (segmento SS) Arquitetura IA32, Porto Alegre, Outubro de 2006
Arquitetura IA32 – Registradores Arquitetura IA32, Porto Alegre, Outubro de 2006
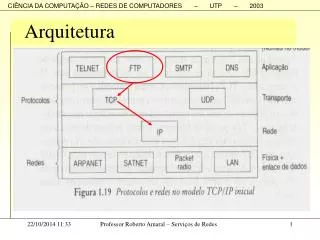
Arquitetura IA32 – Registradores • Memoria linear: Codigo, Dados e Pilha estao no mesmo espaco de enderecamento, e para o programa a memoria e’ um espaco de enderecamento contiguo de 2^32 bytes. • Memoria segmentada: Para o programa a memoria e’ um grupo de segmentos de memoria independentes, onde codigo, dados e pilha estao em segmentos separados. Processador usa registradores de segmento e um deslocamento para calcular um endereco linear. Programas podem acessar 16.383 segmentos diferentes, cada um com 2^32 bytes enderecos. • Segmentacao aumenta a confiabilidade do sistema evitando, por exemplo, que a pilha seja corrompida. • Modo real: modelo de memoria original do 8086, usado para compatibilidade com programas legados. Arquitetura IA32, Porto Alegre, Outubro de 2006
Arquitetura IA32 – Registradores Arquitetura IA32, Porto Alegre, Outubro de 2006
Arquitetura IA32 – Registradores • Memoria linear: Codigo, Dados e Pilha estao no mesmo espaco de enderecamento, e para o programa a memoria e’ um espaco de enderecamento contiguo de 2^32 bytes. • Memoria segmentada: Para o programa a memoria e’ um grupo de segmentos de memoria independentes, onde codigo, dados e pilha estao em segmentos separados. Processador usa registradores de segmento e um deslocamento para calcular um endereco linear. Programas podem acessar 16.383 segmentos diferentes, cada um com 2^32 bytes enderecos. • Segmentacao aumenta a confiabilidade do sistema evitando, por exemplo, que a pilha seja corrompida. • Modo real: modelo de memoria original do 8086, usado para compatibilidade com programas legados. Arquitetura IA32, Porto Alegre, Outubro de 2006