Download

1 / 8
80 likes | 96 Views
Discover the different types of consensus trees used in phylogenetics, such as Strict Consensus and Semi-strict Consensus, and learn about methods like the Incongruence Length Difference Test. Explore how consensus trees help reconcile clades from multiple phylogenetic trees and serve as a conservative estimate of evolutionary relationships.

E N D
Consensus Trees * consensus trees reconcile clades from different trees * consensus is a conservative estimate of phylogeny that emphasizes points of agreement * a position of safety - defensible and pragmatic starting point… especially if you are proposing a new classification * philosophy: agreement among data sets is more important than agreement within data sets
*Strict Consensus (Nelson 1979, Sokal & Rohlf 1981): only those components (clades) shared by all trees are considered; components must be exactly replicated among all trees. Most restrictive approach. Semi-strict Consensus (or Combinable Component Consensus (Bremer 1990): includes all compatible components. Works from strict consensus and adds back all components that are not explicitly contradicted by one or more of the competing cladograms. (Called "semi-strict" consensus in PAUP*.) *Consensus n-Trees (Margush & McMorris 1981): accepts all nodes/resolutions that are present in n% or more of the trees. Usually n=50 and referred to as majority rule consensus. *Adam's Consensus (Adams 1972, McMorris et al. 1982): pulls down components to the first node to which there will be no conflict. Most unrestrictive approach. Preserves structure.
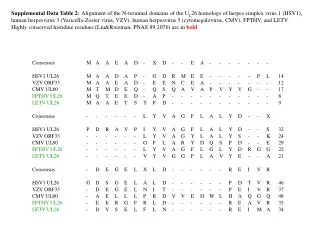
From Quicke 1993. Principles and Techniques of Contemporary Taxonomy
Incongruence Length DifferenceTestFarris et al., 1994 (refer to handout) DXY = L(X + Y)- (LX + LY) where L(X + Y) = length of total evidence or combined analysis LX = length of tree from data set X LY = length of tree from data set Y DXY = measure of incongruence DXY = 0, when MPT from each data set is identical DXY = is large, when minimizing homoplasy in one data set requires creating substantial homoplasy in the other Thus L(X + Y) exceeds (LX + LY) only by the amount of extra homoplasy required by the combined approach. When there is a significant difference in the signal between two data sets then DXY will be large
Incongruence Length DifferenceTest A significance test of the differences between two trees (incongruence) generated by comparing the combined data tree length to values generated by random partitioning of the data sets. * Random partitions are made by generating data sets (matrices) identical in size to the two original data sets * tree lengths are calculated for each partition * structure (signal) in the original partitions will be randomized in the new partitions, and thus the new (randomized) trees will tend to be longer (than DXY) * compare the number of times (LX + LY)< (LP + LQ), where P and Q are random partitions, thus * Type I error rate (tail probability) on rejecting the null hypothesis is 1 - S / (W + 1) S = number of repartitions where (LX + LY)< (LP + LQ) W = number of randomly-selected partitions * S is then compared to W * If W = 99 and S = 95, for example, this indicates significance at the 5% level