Download

1 / 46
460 likes | 584 Views
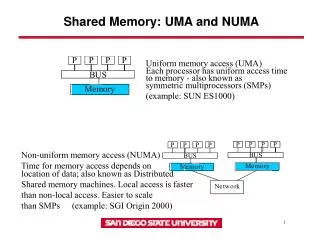
Matching Memory Access Patterns and Data Placement for NUMA Systems. Zolt á n Maj ó Thomas R. Gross Computer Science Department ETH Zurich, Switzerland. Non-uniform memory architecture. Processor 0. Processor 1. Core 0. Core 1. Core 4. Core 5. Core 2. Core 3. Core 6. Core 7.

E N D
Matching Memory Access Patterns and Data Placement for NUMA Systems Zoltán MajóThomas R. Gross Computer Science Department ETH Zurich, Switzerland
Non-uniform memory architecture Processor 0 Processor 1 Core 0 Core 1 Core 4 Core 5 Core 2 Core 3 Core 6 Core 7 IC MC MC IC DRAM DRAM
Non-uniform memory architecture Local memory accesses bandwidth: 10.1 GB/s latency: 190 cycles Processor 0 Processor 1 T Core 0 Core 1 Core 4 Core 5 Core 2 Core 3 Core 6 Core 7 IC MC MC IC DRAM DRAM Data All data based on experimental evaluation of Intel Xeon 5500 (Hackenberg [MICRO ’09], Molka [PACT ‘09])
Non-uniform memory architecture Local memory accesses bandwidth: 10.1 GB/s latency: 190 cycles Remote memory accesses bandwidth: 6.3 GB/s latency: 310 cycles Processor 0 Processor 1 T Core 0 Core 1 Core 4 Core 5 Core 2 Core 3 Core 6 Core 7 IC MC MC IC DRAM DRAM Data Key to good performance: data locality All data based on experimental evaluation of Intel Xeon 5500 (Hackenberg [MICRO ’09], Molka [PACT ‘09])
Data locality in multithreaded programs Remote memory references / total memory references [%]
Data locality in multithreaded programs Remote memory references / total memory references [%]
Outline • Automatic page placement • Memory access patterns of matrix-based computations • Matching memory access patterns and data placement • Evaluation • Conclusions
Automatic page placement • Current OS support for NUMA: first-touch page placement • Often high number of remote accesses • Data address profiling • Profile-based page-placement • Supported in hardware on many architectures
Profile-based page placementBased on the work of Maratheet al. [JPDC 2010, PPoPP 2006] Profile P0 : accessed 1000 times by P1 : accessed 3000 times by T0 T1 Processor 0 Processor 1 P0 T0 P1 T1 DRAM DRAM
Automatic page placement • Compare: first-touch and profile-based page placement • Machine: 2-processor 8-core Intel Xeon E5520 • Subset of NAS PB: programs with high fraction of remote accesses • 8 threads with fixed thread-to-core mapping
Inter-processor data sharing Profile P0 : accessed 1000 times by P1 : accessed 3000 times by T0 T1 Processor 0 Processor 1 T0 T1 P2 : accessed 4000 times by accessed 5000 times by P2 T0 T1 P0 P1 DRAM DRAM P2: inter-processor shared
Inter-processor data sharing Profile P0 : accessed 1000 times by P1 : accessed 3000 times by T0 T1 Processor 0 Processor 1 T0 T1 P2 : accessed 4000 times by accessed 5000 times by T0 T1 P0 P1 P2 DRAM DRAM P2: inter-processor shared
Inter-processor data sharing Shared heap / total heap [%]
Inter-processor data sharing Shared heap / total heap [%]
Inter-processor data sharing Shared heap / total heap [%] Performance improvement [%]
Inter-processor data sharing Shared heap / total heap [%] Performance improvement [%]
Automatic page placement • Profile-based page placement often ineffective • Reason: inter-processor data sharing • Inter-processor data sharing is a program property • Detailed look: program memory access patterns • Loop-parallel programs with OpenMP-like parallelization • Matrix processing • NAS BT
Matrix processing Process msequentially m[NX][NY] for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] NX NY
Matrix processing Process mx-wise parallel m[NX][NY] #pragma omp parallel for for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T0 for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T1 NX T2 T3 T4 T5 T6 T7 NY
Thread scheduling Remember: fixed thread-to-core mapping Processor 0 Processor 1 T0 T1 T2 T3 DRAM DRAM T4 T5 T6 T7
Matrix processing Process mx-wise parallel m[NX][NY] #pragma omp parallel for for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T0 Allocated atProcessor 0 T1 NX T2 T3 T4 Allocated atProcessor 1 T5 T6 T7 NY
Matrix processing Process mx-wise parallel Process my-wise parallel m[NX][NY] T0 T1 T2 T3 T4 T5 T6 T7 #pragma omp parallel for for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] for(i=0; i<NX;i++) • #pragma omp parallel for for(j=0; j<NY; j++) // access m[i][j] Allocated atProcessor 1 Allocated atProcessor 0 NX NY
Example: NAS BT Time-step iteration m[NX][NY] T0 T1 T2 T3 T4 T5 T6 T7 • for(t=0; t<TMAX; t++) • { • x_wise(); • y_wise(); • } T0 T1 NX T2 T3 T4 T5 T6 T7 NY
Example: NAS BT Time-step iteration m[NX][NY] T0 T1 T2 T3 T4 T5 T6 T7 • for(t=0; t<TMAX; t++) • { • x_wise(); • y_wise(); • } T0 Allocated at Processor 0 Appropriate allocation not possible T1 NX T2 T3 T4 Appropriate allocation not possible Allocated at Processor 1 T5 T6 NY T7 Result: Inter-processor shared heap: 35% Remote accesses: 19%
Solution? • Adjust data placement High overhead of runtime data migration cancels benefit • Adjust iteration scheduling Limitedby data dependences • Adjust data placement and iteration scheduling together
API • Library for data placement • Set of common data distributions • Affinity-aware loop iteration scheduling • Extension to GCC OpenMP implementation • Example use case: NAS BT
Use-case: NAS BT • Remember: BT has two incompatible access patterns • Repeated x-wise and y-wise access to the same data • Idea: data placement to accommodate both access patterns Allocated atProcessor 0 Allocated atProcessor 1 NX Blocked-exclusive data placement Allocated atProcessor 1 Allocated atProcessor 0 NY
Use-case: NAS BT for(t=0; t<TMAX; t++) { x_wise(); distr_t *distr; distr= block_exclusive_distr( m,sizeof(m),sizeof(m[0]/2)); distribute_to(distr); y_wise(); }
Use-case: NAS BT for(t=0; t<TMAX; t++) { x_wise(); distr_t *distr; distr= block_exclusive_distr( m,sizeof(m),sizeof(m[0]/2)); distribute_to(distr); #pragma omp parallel for for(i=0; i<NX; i++) for(j=0; j<NY; j++) //access m[i][j] y_wise(); }
x_wise() Matrix processed in two steps Step 1: left half • all accesses local Step 2: right half • all accesses local T0 Allocated atProcessor 0 Allocated atProcessor 1 T1 T2 T3 NX T4 Allocated atProcessor 1 Allocated atProcessor 0 T5 T6 T7 NY / 2 NY / 2
Use-case: NAS BT for(t=0; t<TMAX; t++) { x_wise(); distr_t *distr; distr= block_exclusive_distr( m,sizeof(m),sizeof(m[0]/2)); distribute_to(distr); #pragma omp parallel for for(i=0; i<NX; i++) for(j=0; j<NY; j++) //access m[i][j] #pragma omp parallel for for(i=0; i<NX; i++) for(j=0; j<NY/2; j++) //access m[i][j] #pragma omp parallel for for(i=0; i<NX; i++) for (j=NY/2; j<NY; j++) //access m[i][j] y_wise(); }
Use-case: NAS BT for(t=0; t<TMAX; t++) { x_wise(); distr_t *distr; distr= block_exclusive_distr( m,sizeof(m),sizeof(m[0]/2)); distribute_to(distr); #pragma omp parallel for for(i=0; i<NX; i++) for(j=0; j<NY/2; j++) //access m[i][j] #pragma ompparallel for for(i=0; i<NX; i++) for (j=NY/2; j<NY; j++) //access m[i][j] schedule(static) schedule(static-inverse) y_wise(); }
Matrix processing Process mx-wise parallel m[NX][NY] #pragma omp parallel for schedule(static) for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T0 for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T1 NX T2 T3 T4 T5 T6 T7 NY
Matrix processing Process mx-wise parallel m[NX][NY] #pragma omp parallel for schedule(static) for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T0 m[0 .. NX/8 - 1][*] for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] T1 m[NX/8 .. 2*NX/8 - 1][*] NX T2 m[2*NX/8.. 3*NX/8 - 1][*] T3 m[3*NX/8.. 4*NX/8 - 1][*] T4 m[4*NX/8.. 5*NX/8 - 1][*] T5 m[5*NX/8 ..6*NX/8 - 1][*] T6 m[6*NX/8 ..7*NX/8 - 1][*] T7 m[7*NX/8 .. NX - 1][*] NY
static vs. static-inverse #pragma omp parallel for schedule(static) for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] #pragma omp parallel for schedule(static-inverse) for(i=0; i<NX;i++) for(j=0; j<NY; j++) // access m[i][j] m[0 .. NX/8 - 1][*] T0 m[NX/8 .. 2*NX/8 - 1][*] m[5*NX/8 .. 6*NX/8 - 1][*] m[4*NX/8 .. 5*NX/8 - 1][*] m[2*NX/8 .. 3*NX/8 - 1][*] m[0 .. NX/8 - 1][*] m[7*NX/8 .. NX - 1][*] m[6*NX/8 .. 7*NX/8 - 1][*] m[3*NX/8 .. 4*NX/8 - 1][*] T7 T1 T6 T5 T3 T2 T0 T4 m[NX/8 .. 2*NX/8 - 1][*] T1 m[2*NX/8 .. 3*NX/8 - 1][*] T2 m[3*NX/8 .. 4*NX/8 - 1][*] T3 m[4*NX/8 .. 5*NX/8 - 1][*] T4 m[5*NX/8 .. 6*NX/8 - 1][*] T5 m[6*NX/8 .. 7*NX/8 - 1][*] T6 m[7*NX/8 .. NX - 1][*] T7
y_wise() Matrix processed in two steps Step 1: upper half • all accesses local T0 T1 T2 T3 T4 T5 T6 T7 Allocated atProcessor 0 Allocated atProcessor 1 NX / 2 NX / 2 Step 2: lower half • all accesses local Allocated atProcessor 1 Allocated atProcessor 0 NY
Outline • Profile-based page placement • Memory access patterns • Matching data distribution and iteration scheduling • Evaluation • Conclusions
Evaluation Performance improvement over first-touch [%]
Evaluation Performance improvement over first-touch [%]
Evaluation Performance improvement over first-touch [%]
Scalability Machine: 4-processor 32-core Intel Xeon E7-4830 Performance improvement over first-touch [%]
Scalability Machine: 4-processor 32-core Intel Xeon E7-4830 Performance improvement over first-touch [%]
Conclusions • Automatic data placement (still) limited • Alternating memory access patterns • Inter-processor data sharing • Match memory access patterns and data placement • Simple API: practical solution that works today • Ample opportunities for further improvement