Download

1 / 20
200 likes | 385 Views
Mismatch string kernels for discriminative protein classification. By Leslie. et .al Presented by Yan Wang. Outline. Problem Definition Support Vector Machines Mismatch Kernel Mismatch Tree Data Structure Experiments Conclusions. Protein Classification.

E N D
Mismatch string kernels for discriminative protein classification By Leslie. et .al Presented by Yan Wang
Outline • Problem Definition • Support Vector Machines • Mismatch Kernel • Mismatch Tree Data Structure • Experiments • Conclusions
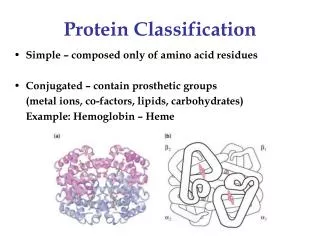
Protein Classification • Problem: classification of proteins sequences into functional and structural families based on sequence homology. • Motivation: Many proteins have been sequenced, but often structure and function remains unknown. Discriminativesupervised machine learningapproach to infer proteins structure and function needs an efficient way to do the computation.
Protein Classification • Given a new protein, can we place it in its “correct” position within an existing protein hierarchy?
Remote Homology • Remote homology: Superfamily-level homology. Sequences that belong to the same superfamily but not the same family. • Motivation: Classify proteins based on sequence data into homologous groups to understand the structure and functions of proteins. • Previous known approaches: pairwise sequence alignment, profiles, HMM • New approaches: Discriminative Models
Discriminative approach Protein sequences are seen as a set of labeled examples—positive if they are in the family and negative otherwise. More direct way to the goal Most accurate method
Discriminative Models -- SVM Assume training data linearly separable in feature space, Linear classification rule: margin Hyperplane:
The Kernel Function • The linear classifier relies on inner products between vectors <xi, xj>. • If every data point in the input space is mapped into high-dimensional space called feature space via some transformation Φ: x→φ(x), the inner product becomes: K (xi,xj)= <φ(xi),φ(xj)> called kernel. Φ is called the feature map. • A kernel function is some function that corresponds to an inner product into some feature space.
The k-Spectrum of a Sequence AKQDYYYYEI • Feature map for SVM based on spectrum of a sequence. • The k-spectrum of a sequence is the set of all k-length (contiguous, k>=1) subsequences that it contains. We refer to such a k-length subsequence as a k-mer. • Dimension of k-merfeature space =l k(l=20 for the alphabet of amino acids). AKQ KQD QDY DYY YYY YYY YYE YEI
k-Spectrum Feature Map • Feature map is indexed by all possible k-mers. • k-spectrum feature map with no mismatches: • For sequence x, ,where = number of occurrences of in x. AKQDYYYYEI ( 0 , 0 , … , 1 , … , 1 , … , 2 , … 1) AAA AAC … AKQ … DYY … YYY … YEI
k-Spectrum Kernel • k-spectrum kernel K (x, y) for two sequences x and y is obtained by taking the inner product in feature space: • This kernel simply counts the occurrences of k-length subsequences for each of the sequence in consideration. • This kernel gives a simple notion of sequence similarity: two sequences will have a large k-spectrum kernel value if they share many of the same k-mers.
(k, m)-Mismatch Kernel • Slight modification to the k-spectrum kernel. • Define a parameter m which allows up to m mismatches in the counting of occurrences. • This means =>k-spectrum feature map, allowing m mismatches: • If is a fixed k-mer, , where = 1 if is within m mismatches from , otherwise 0. • Example: Mismatch neighborhood around .
(k,m)-Mismatch Kernel • extend additively to longer sequences x by summing over all k-mers in x: (k, m)-mismatch kernel is once again just the inner product in feature space: SVMs can be learned by supplying this kernel function. The learned SVM classifier is given by:
A Simple Application: • We first normalize the kernels: • Then consider the induced distance:
Efficient computation of kernel matrix with a mismatch tree data structure (8,1)-mismatch tree for sequence AVLALKAVLL • The entire kernel matrix can be computed in one depth-first traversal of the mismatch tree structure. • The (k,m)-mismatch tree is a rooted tree of depth k, where each internal node has 20 branches. • an amino acid is labeled with each branch. • a leaf node presents a k-mer. • an internal node represented the prefix of a k-mer. A L
Example: Mismatch Tree Data Structure AA AB AC BA BB BC CA CB CC
Experiments • SCOP experiments with domain homologs
Experiments • SCOP experiments without domain homologs
Conclusions • Presented mismatch kernels that measure sequence similarity without requiring alignment and without depending upon a generative model. • Presented a method for efficiently computing kernels. • In the SCOP experiments, this method performs competitively when compare with state-of-the-art methods. Such as SVM-Fisher and SVM-pairwise. • Mismatch kernel approach gives efficient kernel computation, linear time prediction and maintains good performance even when there is little training data. • Mismatch kernel approach can extract high-scoring k-mers from a trained SVM-mismatch classifier in order to look for discriminative motif regions in the positive sequence family.