Download

1 / 13
130 likes | 306 Views
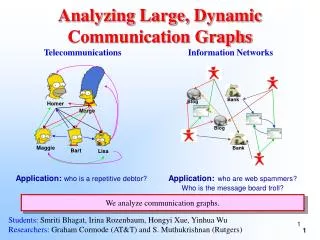
Sampling from Large Graphs. Motivation. Our purpose is to analyze and model social networks An online social network graph is composed of millions of nodes and edges In order to analyze it we have to store the whole graph in the computers memory Sometimes this is impossible

E N D
Motivation • Our purpose is to analyze and model social networks • An online social network graph is composed of millions of nodes and edges • In order to analyze it we have to store the whole graph in the computers memory • Sometimes this is impossible • Even when it is possible it is extremely time consuming only to compute some basic graph properties • Thus we need to extract a small sample of the graph and analyze it
Problem • Given a huge real graph, how can we derive a representative sample? • Which sampling method to use? • How small can the sample size be? • How do we measure success?
Problem • What do we compare against? • Scale down sampling: • Given a graph G with n nodes, derive a sample graph G’ with n’ nodes (n’ << n) that will be most similar to G • Back in time sampling: • Let Gn’ denote graph G at some point in time when it had n’ nodes • Find a sample S on n’ nodes that is most similar to Gn’ (when graph G had the same size as S)
Evaluation Techniques • Criteria for scale down sampling • In degree distribution • Out degree distribution • Distribution of sizes of weakly connected components • Distribution of sizes of strongly connected components • Hop plot, number of reachable pairs of nodes at distance h • Hop plot on the largest WCC • Distribution of the clustering coefficient • Distribution of singular values of the graph adjacency matrix versus the rank
Evaluation Techniques • Criteria for back in time sampling • Densification Power Law: • Number of edges vs number of nodes over time • The effective diameter of the graph over time • Observed that shrinks and stabilizes over time • Normalized size of the largest WCC over time • Average clustering coefficient over time • Largest singular value of graph adjacency matrix over time
Statistical Tests • Comparing graph patterns using Kolmogorov-Smirnov D-statistic • Measure the agreement between two distributions using D = maxx{|F’(x) – F(x)|} • Where F and F’ are two cumulative distribution functions • Does not address the issue of scaling • Just compares the shape of the distributions • Comparing graph patterns using the visiting probability • For each node u E G, calculate the probability of visiting node w E G • Use of Frobenius norm to calculate the difference in visiting probability.
Algorithms • Sampling by random node selection • Random Node Sampling: • Uniformly at random select a set of nodes • Random PageRank sampling • Set the probability of a node being selected into the sample proportional to its PageRank weight • Random Degree Node • Se the probability of a node being selected into the sample proportional to its degree
Algorithms • Sampling by random edge selection • Random edge sampling • Uniformly select edges at random • Random node – edge sampling • Uniformly at random select a node, then uniformly at random select an edge incident to it • Hybrid sampling • With probability p perform RNE sampling, with probability 1-p perform RE sampling
Algorithms • Sampling by exploration • Random node neighbor • Select a node uniformly at random together with all his out-going neighbors • Random walk sampling • Uniformly at random select a random node and perform a random walk with restarts • If we get stuck, randomly select another node to start • Random jump sampling • Same as random walk sampling but with a probability p we jump to a new node • Forest fire sampling • Choose a node u uniformly at random • Generate a random number z and select z out links of u that are not yet visited • Apply this step recursively for all z links selected
Evaluation • Three groups of algorithms: • RDN, RJ, RW: biased towards high degree nodes and densely connected part of the graph • FF, RPN, RN: not biased towards high degree nodes, match the temporal densification of the true graph • RE, RNE, HYB: For small sample size the resulting graph is very sparsely connected • Conclusion: • For the scale down goal methods based on random walks perform best • For the back in time goal forest fire algorithm performs best • No single perfect answer to graph sampling • Experiments showed that a 15% sample is usually enough
Further thoughts • Wrong approach trying to match all properties? Maybe we should try matching one at a time • Test methods for sampling on graphs with weighted – labeled edges • Current algorithms are extremely slow when we read a graph from a file • Need to implement better versions of them in order to decrease the I/O cost
Bibliography • Sampling from large graphs, J. Leskovec and C. Faloutsos • Unbiased sampling of Facebook, M. Gjoka, M. Kurant, C. T. Butts and A. Markopoulou • What is the real size of a sampled network? The case of the Internet, F. Viger, A. Barrat. L. Dall’Asta, C. Zhang and E. D. Kolaczyk • Sampling large Internet topologies for simulation purposes, V. Krishnamurthy, M. Faloutsos, M. Chrobak, J. Cui, L. Lao and A. G. Percus