Download

1 / 13
130 likes | 211 Views
COMP/EECE 7/8740 Neural Networks. Approximations by Perceptrons and Single-Layer NNs Robert Kozma February 11, 2003. Linear Discriminant Function. Input: X=[x_1, x_2,…, x_d] T , d-dimensional input space T means transposed vector or matrix Linear combination of input data:

E N D
COMP/EECE 7/8740 Neural Networks Approximations by Perceptrons and Single-Layer NNs Robert Kozma February 11, 2003
Linear Discriminant Function • Input: X=[x_1, x_2,…, x_d]T, • d-dimensional input space • T means transposed vector or matrix • Linear combination of input data: • Y(X) = WT X + W0 • W = [w+1, w_2,…, w_d]T – weight vector • w_o = constant -- bias offset • Y(X) = S w_i x_i + w_o • Discriminant function (threshold) • Class 1 if Y(X) < 0 • Class 2 if Y(X) > 0
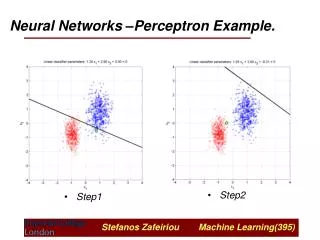
Meaning of Linear Discriminant • x_1 Class 1 (Y > 0) Y(X) = 0 x_2 Class 2 (Y < 0) If W_0 = 0 Bias shows the offset from origin
Nodal Representation of Discriminant as Neural Net • Linear combination • Y(X) = WT X + W0 : Y > 0 or Y < 0 discriminant Y(X) w_1 w_d w_0 x_1 x_2 x_3 x_4 … x_d x_0
Single Layer Neural NetMulti-Class Recognition Problem • Linear discriminant • K – number of classes, k = 1,…, K • Yk(X) = WkT X + Wk0 • choose max discriminant: Yk(X) = max {Yi(X)} • Yk(X) = S wki xi + wk0 , k = 1, …, K • Where summation is over all input dimension d
Multi-class Recognition • Yk(X) = S wki xi + wk0 , k = 1, …, K • Max{Yk(X) } Y1(X) … Yk(X) Output Input w_11 w_1d w_0 x_1 x_2 x_3 x_4 … x_d x_0
Include Nonlinearity in Output • Yk(X) = g (S wki xi + wk0 ), k = 1, …, K Y1(X) … Yk(X) g( ) g( ) Output Input w_11 w_1d w_0 x_1 x_2 x_3 x_4 … x_d x_0
Motivation of Nonlinear Transfer Function • NN outputs are interpreted as posteriory probabilities • > these are not necessarily linear in inputs • We can derive for normal class-conditional probabilities • Y_k P(C_k | X ) = 1 / {1 + exp(A)} • Where: A = WT X + W0 • This is called sigmoid nonlinearity • Display and see fig. 3.5
Derivation of Decision Criterion • Goal: minimize probability of misclassification • Bayesian rule: • choose P(Ck|X) > P(cj|X) for any j p(x|Ck) P(Ck)/p(X) > p(x|Cj) P(Cj)/p(X), here p(X) const • p(x|Ck) P(Ck)/p(X) > p(x|Cj) P(Cj)/p(X) • Interpretation: • Threshold decision (two classes) • Draw 2 normal curves and illustrate the meaning • Next : log transformation…
NN Decision Criterion (cont’d) • Log is a monotonous function, so: log(p(x|Ck) P(Ck)) > log(p(x|Cj) P(Cj)) log(p(x|Ck)) + log( P(Ck)) > log(p(x|Cj) + log(P(Cj)) Rearrange it and define Y = Yk/Yj: Y(x) = log{(p(x|Ck)/p(x|Cj)} + log{P(Ck)/P(Cj)} > 0 • This is an alternative form of the decision rule • Why?! • Plug in class-conditional and prior probabilities to get a decision criterion
Actual Form of Class Conditional Probability • Common: normal/Gaussian distribution • N(s,m) • P(x|Ck) = 1/sqrt(2Ps2k ) exp{-(x-mk)2/2sk} • Substitute it to Bayes rule • Yk(x) = -1/2 (x-mk)2/sk –1/2ln sk + lnP(Ck) • For Normal class-conditional probabilities • The decision criterion is quadratic in X!! • This makes life easy and given a justification of SSE criteria later
Advantages of Normal Class Conditional Probabilities + • Simplicity of treatise • Quadratic (2nd order) decision criterion • 2 parameters s,m • Good approximation in a lot of real-life problems • CLT: central limit theorem: xi iid rv, I=1,…, n • Then (x1+x2+…xn)/n N(s,m), when n inf. • Linear transformation preserves the properties • There is a linear transformation of the variables that diagonalizes the covariance • Related to entropy maximum principle
Covariance Matrix • Multivariate process X={x1, x2, .., xd}T • Normal distribution P(x) = 1/{(2P)d/2 |S|1/2} exp{-1/2 (x-mk)TS-1 (x-mk)} • Here m = {m1,m2, …, md}T -- mean vector • mi = E(xi) = (-inf,+inf) xi p(xi) dxi • S is covariance matrix: Sij, i,j = 1,…,d • Sij = E((xi- mi)) (xj- mj) ) = (xi- mi)) (xj- mj) p(xi ‘xj) dxi dxj • Diagonalization means: S matrix is diagonal • No offdiagonal covariance components