Download

1 / 39
390 likes | 502 Views
Breakpoints and Halting in Distributed Systems. Presented by Abhishek Saxena CS 739 Distributed Systems Spring 2002. References. Detecting Relational Global Predicates in Distributed Systems by Alexander I. Tomlinson and Vijay K. Garg, 1993

E N D
Breakpoints and Halting in Distributed Systems Presented by Abhishek Saxena CS 739 Distributed Systems Spring 2002
References • Detecting Relational Global Predicates in Distributed Systems by Alexander I. Tomlinson and Vijay K. Garg, 1993 • Breakpoints and Halting in Distributed Programs by Barton P. Miller and Jong-Deok Choi, 1992 • Restoring Consistent Global States of Distributed Computations by Goldberg et al., 1991
Presentation Layout • Introduction • Motivation • Halting in Distributed Systems • Detecting Breakpoints for: • Conjunctive/Disjunctive/Linked Predicates • Relational Predicates • Applications to Research • Relevance to papers read • Conclusions
Introduction • General problems of: • Halting distributed programs • Detecting breakpoints • Validating resource conflicts • Recording, restoration and replay of program sequences
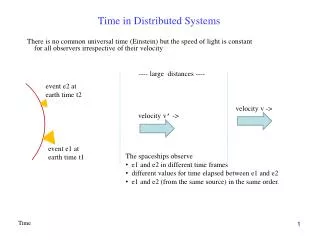
Motivation • Why halt? • Interactive debugging • Issues in distributed systems: • No single global notion of time • Unpredictable communication delays • How to issue instant command to all processes? • Command to simultaneously reach all processes?
Halting • 2 pertinent questions: • How to halt a distributed program? • Halting Algorithm • When to halt? • Breakpoint Detection
Halting Algorithm • Extends Chandy & Lamport’s algorithm • Sending rule: • Increments last_halt_id • Send halt marker containing this value to outgoing channels • Receiving rule: • Compare the halt_id with its last_halt_id & update • Send halt marker like sender
The Halting Algorithm Process R Sending process P Halt marker Halt marker Halt marker Halt marker Halt marker Process S Process U
The Halting Algorithm • Intuitive extension to Chandy & Lamport’s Algorithm[1] • Leads to a global consistent state since: • Process states same as recorded process states in [1] • Undelivered messages same as recorded channels states in [1]
Problems with this Algorithm • Processes that infrequently interact with other computation processes • Long halting time • Acyclic network connection Consumer Producer P Q Communication Channel
A Solution… • Centralized debugger process: Debugger process d q p
Problems with this solution • Communication overheads • Possible change in execution of program • Complex to build
Detecting Breakpoints • Breakpoints & Predicates • Predicate satisfaction = breakpoint detection • Distributed processes’ system needs: • Simple predicates • Disjunctive predicates • Linked predicates…interesting! • Conjunctive predicates…very interesting!
Simple Predicates • Encapsulate single process behavior • Detect simple events: • Entered procedure • Message sent / received • Channel created / destroyed • Process created / destroyed
Disjunctive predicates • Form: DP ::= SP [ U SP ]* • Satisfied when any SP is satisfied • Initiate halting when DP is true
Linked Predicates • Specify sequences of events • Form: LP ::= DP [ ->DP ]* • Debugger process sends the LP {DP1->...} to processes involved in DP1 • Upon DP1, strip off DP1 & send stripped LP to processes involved in DP2
Linked predicates’ implementation Process Q Processes involved in DP2 Processes involved in DP1 Process S Debugger process Process P Start halting DP2 DP2 DP1->DP2 DP1->DP2 DP1->DP2 Process T Start halting Start Halting Process R
Conjunctive Predicates • Form: CP ::= SP [ ∩ SP ]* • Hardest to detect! • No single time reference across machines • Interpretation based on virtual time: • Consider processes P1, P2 with virtual time axes T1, T2 • Define SCP = { (t1, t2) | t1ε T1, t2ε T2, SP(t1) ∩ SP(T2) }
Conjunctive predicates • Split SCP into: • Ordered-SCP: { (t1, t2) | (t1, t2)ε SCP, ((SP1) i -> (SP2) j) U ((SP2) i ->(SP1) j) } • Unordered-SCP: { (t1, t2) | (t1, t2)ε SCP, (t1, t2) € ordered-SCP }
Conjunctive Predicates t11 t21 ordered-SCP pair t12 t22 unordered- SCP pair t23 t13
Conjunctive Predicates • Detecting unordered-SCP events difficult • Requires: • Global information gathering process • Time delay! • Cannot preserve meaningful process states
Detecting Relational Global Predicates • Resource conflict validation problems undetectable by earlier predicate classes • Form: ( x0 +…+ xn > C ) • xi: resource usage at Pi • C: total resource available • Undecomposable into earlier classes of predicates
How to detect such predicates? • 2 algorithms: • Decentralized: runs concurrently • Centralized: decoupled from the target program
Model & Notation • Partial ordering on S = { S0, …, Sn } where, Si <= Sj, for 0 <= i,j <= n • Happens-before relation: “->” • pred.u.i: Intuitively, is the state just preceding u in process i • succ.u.i: The state just succeeding u in process i
Concurrent States & Intervals Q P 9 2 State Interval 10 3 Receive Interval 11 4 Deterministic event Local state Non-deterministic event
Concurrent Intervals 1, lo1 1, j 1, hi1 P1 0, lo0 P0 0, i 0, hi0 KEY pred relation
Concurrent Intervals • Intervals (0,i) & (1, j) concurrent iff KEY exists in P0 or P1 s.t., lo0 < i <= hi0 & lo1 < j <= hi1, where, the lo0, lo1, hi0, hi1 as defined by the previous diagram
Overview of algorithms • Gather information • What? • How? • Consider 2 processes P0 & P1 • Gather concurrent interval sequences: • { lo0 to hi0 } at P0 & { lo1 to hi1 } at P1 • Check resource violations at all possible pairs of states in these sequences!!
Algorithms contd… • Representation of (0, lo0) (0, hi0) (1, lo1) (1, hi1) as a 2x2 Matrix clock • Row i of Pi’s matrix clock = Pi’s vector clock • Current interval at Pk = (k, Mk[ , ]) • Row k of Mk…pred() of current interval at Pk • Row i<>k…pred.pred() of current interval at Pk
Maintaining Matrix Clocks • Initialize • Initialize matrix to 0 • If k=0 or k=1 Mk[k, k] ++ • Send message tagged with Mk[., .] ; Increment Mk[k,k] for k=0 V 1 • Upon message receive update matrix clock; Increment Mk[k,k] ; • Mk[k, ]= diagonal(Mk)
Matrix Clock Example 3 1 0 1 1 0 0 0 2 1 0 1 P0 2 1 0 1 0 0 0 1 0 0 0 1 0 0 0 2 2 1 2 3 P1
Decentralized Algorithm • Consider process P0 • Upon mesg receive evaluate lo0, lo1, hi0, hi1 • Find min value of resource(x) at P0 • Send debug mesg (min_x0, lo1, hi1) to P1 • P1 detects the predicate : (min_x0 + min_x1 > C)
Overheads & Complexity at P0 • Message overheads: • (# of receive intervals at P0)* sizeof ( 3 integers)………………..Debug mesgs • Sizeof(4 integers)…………Application mesgs • Memory: • # intervals at P0; min_x for each interval • Computation: • (# intervals at P0)*( # debug mesgs sent + received)
Centralized Algorithm • Checker process runs concurrently or, post-mortem • Consider the latter: processes P0 & P1 • Processes keep trace files containing: • min_x for each interval • an array of {lo0, lo1, hi0, hi1} for each interval • Runs a check algorithm • Builds heaps by inserting the min_x values for all concurrent interval sequences at P0 & P1 • Use these heap-tops to detect the predicate
Overheads & Complexity for P0 • Memory: • 4 integers for matrix clock each application process • Computation: • Monitor local variables • Rest offloaded to checker • O(R0 + M0logM0 + M1logM1) Where, R0 & M0 = # rec intervals & total intervals at P0
Major Practical Problems • Reduced complexity from exp to O(nlogn) but still… • Large overheads even for 2 processes • Lots of messages! • Lots of memory space! • Lots of computation!
Applications to Research • Development of distributed debugging environment • Recording of execution sequences • Rollback • Replay • Exploration of new execution scenarios • Command of mission-control distributed systems
Relevance to Papers Read • The S/Net’s Linda kernel: • Debugging distributed tuple space • Detecting race conditions, deadlocks, probe effects • Chandy & Lamport’s paper explores the detection of stable predicates and Garg’s paper explores unstable predicate detection
Conclusions • Distributed debugging still challenging • No efficient algorithm • Hard to do away with overheads • Need for efficient event monitoring & manipulation tools • Message sequence chart generators • Program flow analysis for more independent program splitting