Download

1 / 25
250 likes | 403 Views
ECE 1747 Parallel Programming Course Project Dec. 2006. Parallel Computation of the 2D Laminar Axisymmetric Coflow Nonpremixed Flames. Qingan Andy Zhang PhD Candidate Department of Mechanical and Industrial Engineering University of Toronto. Outline. Introduction Motivation Objective

E N D
ECE 1747 Parallel Programming Course Project Dec. 2006 Parallel Computation of the 2D Laminar Axisymmetric Coflow Nonpremixed Flames Qingan Andy Zhang PhD Candidate Department of Mechanical and Industrial Engineering University of Toronto
Outline • Introduction • Motivation • Objective • Methodology • Result • Conclusion • Future Improvement • Work in Progress
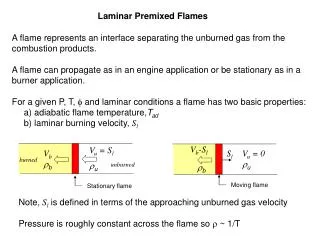
Flow configuration Introduction • Multi-dimensional flame • Easy to model • Computationally OK with detail sub-models such as chemistry, transport, etc. • Lots of experimental data • Resembles the turbulent flames in some cases (eg. flamelet regime)
Motivation The run time is expected to be long if: • Complex Chemical Mechanism • Appel (2000) mechanism (101 species,543 reactions) • Complex Geometry • Large 2D coflow laminar flame (1,000*500=500,000) • 3D laminar flame (1,000*500*100=50,000,000) • Complex Physical Problem • Soot formation • Multi-phase problem
Objective To develop parallel flame code based on the sequential flame code • Speedup • Feasibility • Accuracy • Flexibility
Methodology -- Options • Shared Memory • OpenMP • Pthread • Distributed Memory • MPI • Distributed Shared Memory • Munin • TreadMarks MPI is chosen because it is widely used for scientific computation, easy to program and also the cluster is a Distributed Memory system.
Methodology -- Preparation • Linux OS • Programming tool (Fortran, Make, IDE) • Parallel computation concepts • MPI commands • Network (SSH, queuing system)
Methodology –Sequential code • Sequential Code Analysis • Algorithm • Dependency • Data • I/O • CPU time breakdown Sequential code is the backbone for parallelization!
Continuity equation Momentum equation Gas species equation Energy equation Constitutive relation + Initial condition Boundary condition CFD With parallel computation Methodology Flow configuration and computational domain
Methodology CFD: Finite Volume Method Iterative process on Staggered grid Quantities solved (primitive variables): U, V, P’, Yi (i=1,KK), T Yi --- ith gas species mass fraction KK --- total gas species number If KK=100, then we have to solve (3+100+1)=104 equations at each point. If mesh is 1000*500, then, we have to solve 104*1000*500=52,000,000 equations in each iteration. If 3000 iterations are required to get converged solution, we have to totally solve 52,000,000*3000=156,000,000,000 equations. Flow configuration and computational domain
General Transport Equation Unsteady Term + Convection Term = Diffusion Term + Source Term Unsteady: time variant term Convection: caused by flow motion Diffusion: For species: molecular diffusion and thermo diffusion Source term: For species: chemical reaction
Mass and Momentum equation Mass: Axial momentum: Radial momentum:
Diffusion of species Radiation heat transfer Chemical reaction Species and Energy equation Species Energy
Methodology –Sequential code • Start iteration from scratch or continued job • Within one iteration • Iteration starts • Discretization get AP(I,J) and CON(I,J) • Solve TDMA or PbyP Gauss Elimination • Get new value update F(I,J,NF) array • Do other equations • Iteration ends • End iteration if convergence reached
Methodology –Sequential code Most time-consuming part: Species Jacobian matrix DSDY(K1,K2,I,J) evaluation Dependency?? Fig. 1 CPU time for each sub-code summarized after one iteration with radiation included
R, V Z, U Six processes used to decompose the computational domain of 206*102 staggered grid points Methodology -- Parallelization Domain Decomposition Method (DDM) with Message Passing Interface (MPI) programming Ghost Points are placed at the boundary to reduce communication among processes!
Cluster Information • Cluster location: icpet.nrc.ca in Ottawa • 40 nodes connected by Ethernet • AMD Opteron 250 (2.4GHz) with 5G memory • Redhat Linux Enterprise Edition 4.0 • Batch-queuing system: Sun Grid Engine (SGE) • Portland Group compilers (V 6.2) + MPICH2 n1-5 n2-5 n3-5 n4-5 | n5-5 n6-5 n7-5 n8-5 n1-4 n2-4 n3-4 n4-4 | n5-4 n6-4 n7-4 n8-4 n1-3 n2-3 n3-3 n4-3 | n5-3 n6-3 n7-3 n8-3 n1-2 n2-2 n3-2 n4-2 | n5-2 n6-2 n7-2 n8-2 n1-1 n2-1 n3-1 n4-1 | n5-1 n6-1 n7-1 n8-1
Results --Speedup Table 1 CPU time and speedup for 50 iterations with Appel et al. 2000 mechanism • Speedup is good • CPU time spent on 50 iterations for the original sequential code is 51313 seconds, i.e. 14.26 hours. Too long!
Results --Speedup Fig. 3 Speedup obtained with different processes
Temperature field (in K) OH field (in mole fraction) Pyrene field (in mole fraction) Benzene field (in mole fraction) Results --Real application Flame field calculation using the parallel code (Appel 2000 mechanism) The trend is well predicted!
Conclusion • The sequential flame code is parallelized with DDM • Speedup is good • The parallel code is applied to model a flame using a detailed mechanism • Flexibility is good, i.e. geometry and/or # of processors can be easily changed
Future Improvement • Optimized DDM • Species line solver
Work in Progress • Fixed sectional soot model • Add 70 equations to the original system of equations
Experience • Keep communication down • Wise parallelization method • Debugging is hard • I/O
Thanks Questions?