Download
1 / 14
140 likes | 160 Views
This article explores the key components and techniques of data mining, including data cleaning, sampling, dimensionality reduction, and predictive modeling. Learn how to extract patterns and knowledge from large databases to make informed decisions.

E N D
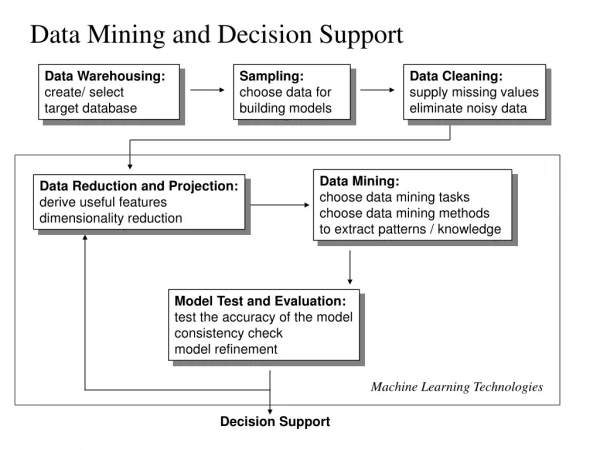
Data Mining and Decision Support Data Warehousing: create/ select target database Sampling: choose data for building models Data Cleaning: supply missing values eliminate noisy data Data Mining: choose data mining tasks choose data mining methods to extract patterns / knowledge Data Reduction and Projection: derive useful features dimensionality reduction Model Test and Evaluation: test the accuracy of the model consistency check model refinement Machine Learning Technologies Decision Support
Data Pre-processing • Data Cleaning : • Eliminating Noise Data (incorrect attribute values, incomplete data items ) • Missing data • Redundant data • Sampling: • selecting appropriate parts of the database for building models • providing error estimation for sample selection • Dimensionality Reduction and Feature Selection: • identifying the most appropriate attributes in the database being examined • creating important derived attributes • Data Transformation: • Transforming complex / dynamic data (such as time-series data) into simpler • (static) data
Exhaustive search through the databases available today is not practically feasible because of their size A DM system must be able to assist in the selection of appropriate parts (samples) of the databases to be examined Random sampling is used most frequently not necessarily representative assumes that the data supporting the various classes/events to be discovered is evenly distributed. Not the case in many real-world databases. Stratified samples: Approximate the percentage of each class (or sub-population of interest) in the overall database (used in conjunction with unevenly distributed data) Out-of-sample testing inductive model is never absolutely correct testing is to estimate the error rate (uncertainty) Sampling: Getting representatives
Out-of-sample Testing Must be independent Training data Induction sample Sample data Historical Data (warehouse) Test data Error estimation
Data Mining Operations and Techniques: • Predictive Modelling : • Based on the features present in the class_labeled training data, develop a description or model for each class. It is used for • better understanding of each class, and • prediction of certain properties of unseen data • If the field being predicted is a numeric (continuous ) variables then the prediction problem is a regression problem • If the field being predicted is a categorical then the prediction problem is a classification problem • Predictive Modelling is based on inductive learning (supervised learning)
debt * * o o * o * o o * o * * * * o o * o * o income debt * * o o * o * o o * o * * * * o o * o * o income Predictive Modelling (Classification): Linear Classifier: Non Linear Classifier: debt * * o o * o * o o * o * * * * o o * o * o income a*income + b*debt < t => No loan !
Clustering (Segmentation) Clustering does not specify fields to be predicted but targets separating the data items into subsets that are similar to each other. Clustering algorithms employ a two-stage search: An outer loop over possible cluster numbers and an inner loop to fit the best possible clustering for a given number of clusters Combined use of Clustering and classification provides real discovery power.
debt * * o o * o * o o * o * * * * o o * o * o income debt debt * + * + o o + + * + o + * + o o + + * + o + * * + + * + * + o + o + * + o + * + o + income Supervised vs Unsupervised Learning: debt + + + + + + + + + + + + + + + + + + + + + Supervised Learning Unsupervised Learning income
Associations relationship between attributes (recurring patterns) Dependency Modelling Deriving causal structure within the data Change and Deviation Detection These methods accounts for sequence information (time-series in financial applications pr protein sequencing in genome mapping) Finding frequent sequences in database is feasible given sparseness in real-world transactional database
Basic Components of Data Mining Algorithms • Model Representation (Knowledge Representation) : • the language for describing discoverable patterns / knowledge • (e.g. decision tree, rules, neural network) • Model Evaluation: • estimating the predictive accuracy of the derived patterns • Search Methods: • Parameter Search : when the structure of a model is fixed, search for the parameters which optimise the model evaluation criteria (e.g. backpropagation in NN) • Model Search: when the structure of the model(s) is unknown, find the model(s) from a model class • Learning Bias • Feature selection • Pruning algorithm
Task: determine which of a fixed set of classes an example belongs to Input: training set of examples annotated with class values. Output:induced hypotheses (model/concept description/classifiers) Predictive Modelling (Classification) Learning : Induce classifiers from training data Inductive Learning System Training Data: Classifiers (Derived Hypotheses) Predication : Using Hypothesis for Prediction: classifying any example described in the same manner Classifier Decision on class assignment Data to be classified
Definition Target function : Training set: hypothesis : Learning as Search Basic Concept of Inductive Learning (model space) Learning System g Evaluation T
Approximation Accuracy • True error : • Training error: • Learning problem : how can we base learning on a limited training set when it contains no information about the function elsewhere (generalisation problem)?
A Statistic Solution • Learning from a large independently drawn sample set with the same distribution as the input space (Bernoulli’s theorem) • Model space is formed without the knowledge of training data (no overfitting) • A local optimal is a reasonable hypothesis • Learning algorithm : search with heuristics • Heuristics : guided by statistical information for error pruning • Guarantees of providing performance of a model is probabilistic




















