Download
1 / 15
150 likes | 372 Views
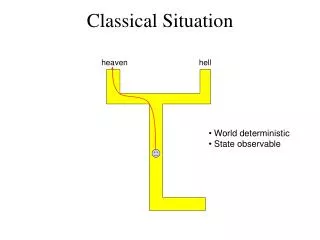
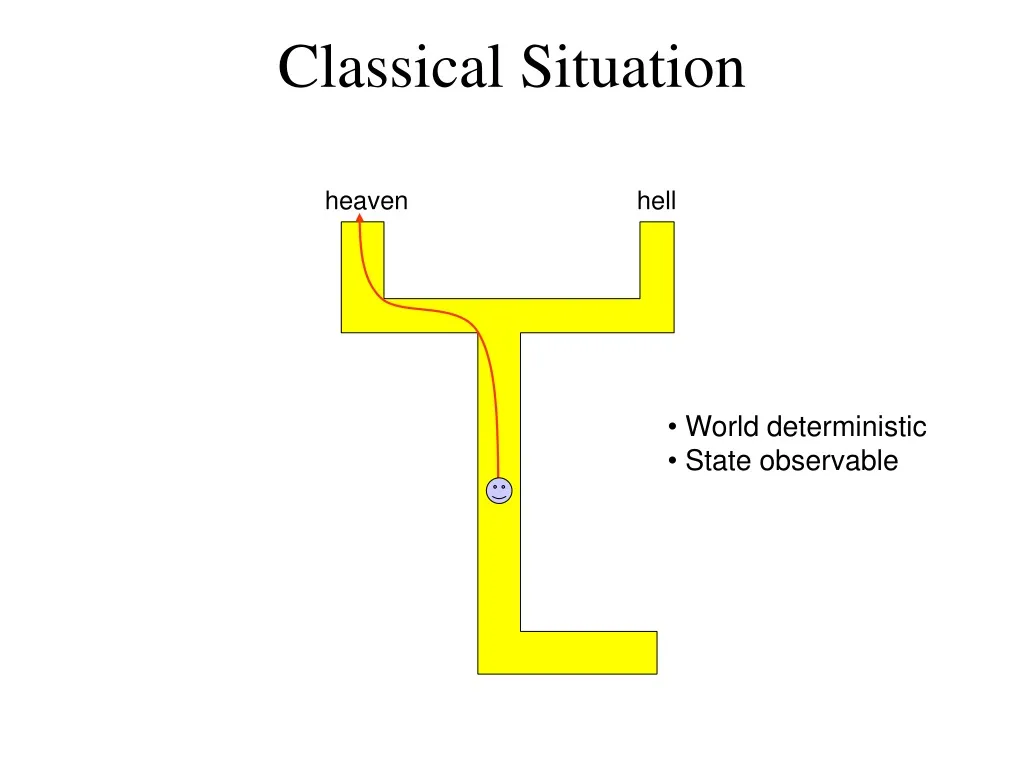
Classical Situation. heaven. hell. World deterministic State observable. MDP-Style Planning. Policy Universal Plan Navigation function. [Koditschek 87, Barto et al. 89]. heaven. hell. World stochastic State observable. Stochastic, Partially Observable. heaven?. hell?. sign.

E N D
Classical Situation heaven hell • World deterministic • State observable
MDP-Style Planning • Policy • Universal Plan • Navigation function [Koditschek 87, Barto et al. 89] heaven hell • World stochastic • State observable
Stochastic, Partially Observable heaven? hell? sign [Sondik 72] [Littman/Cassandra/Kaelbling 97]
Stochastic, Partially Observable heaven hell hell heaven sign sign
Stochastic, Partially Observable start 50% 50% heaven hell ? ? hell heaven sign sign sign
MDP-Style Planning • Policy • Universal Plan • Navigation function [Koditschek 87, Barto et al. 89] heaven hell • World stochastic • State observable
Markov Decision Process (discrete) r=1 0.1 s2 0.9 0.7 0.1 0.3 0.99 r=0 s3 0.3 s1 r=20 0.3 0.4 0.2 s5 s4 r=0 0.8 r=-10 [Bellman 57] [Howard 60] [Sutton/Barto 98]
Value Iteration • Value function of policy p • Bellman equation for optimal value function • Value iteration: recursively estimating value function • Greedy policy: [Bellman 57] [Howard 60] [Sutton/Barto 98]
Stochastic, Partially Observable ? ? heaven hell ? ? hell heaven start start sign sign sign sign 50% 50%
Introduction to POMDPs (1 of 3) action b 100 -100 100 -40 80 0 a b a b action a -100 action b action a s1 s2 s1 s2 p(s1) [Sondik 72, Littman, Kaelbling, Cassandra ‘97]
Value Iteration in POMDPs Substitute b for s • Value function of policy p • Bellman equation for optimal value function • Value iteration: recursively estimating value function • Greedy policy:
Missing Terms: Belief Space • Expected reward: • Next state density: Bayes filters! (Dirac distribution)
Value Iteration in Belief Space state s next state s’, reward r’ observation o . . . . . . . . belief state b next belief state b’ Q(b, a) max Q(b’, a) value function
Why is This So Complex? ? State Space Planning (no state uncertainty) Belief Space Planning (full state uncertainties)