Download

1 / 69
690 likes | 895 Views
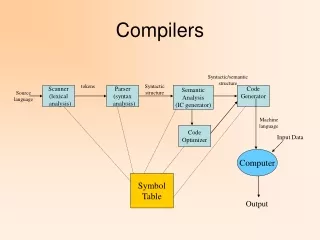
COS 320 Compilers. David Walker. The Front End. Lexical Analysis : Create sequence of tokens from characters (Chap 2) Syntax Analysis : Create abstract syntax tree from sequence of tokens (Chap 3) Type Checking : Check program for well-formedness constraints. stream of characters.

E N D
COS 320Compilers David Walker
The Front End • Lexical Analysis: Create sequence of tokens from characters (Chap 2) • Syntax Analysis: Create abstract syntax tree from sequence of tokens (Chap 3) • Type Checking: Check program for well-formedness constraints stream of characters stream of tokens abstract syntax Lexer Parser Type Checker
Parsing with CFGs • Context-free grammars are (often) given by BNF expressions (Backus-Naur Form) • Appel Chap 3.1 • More powerful than regular expressions • Matching parens • Nested comments • wait, we could do nested comments with ML-LEX! • CFGs are good for describing the overall syntactic structure of programs.
Context-Free Grammars • Context-free grammars consist of: • Set of symbols: • terminals that denotes token types • non-terminals that denotes a set of strings • Start symbol • Rules: • left-hand side: non-terminal • right-hand side: terminals and/or non-terminals • rules explain how to rewrite non-terminals (beginning with start symbol) into terminals symbol ::= symbol symbol ... symbol
Context-Free Grammars A string is in the language of the CFG if only if it is possible to derive that string using the following non-deterministic procedure: • begin with the start symbol • while any non-terminals exist, pick a non-terminal and rewrite it using a rule • stop when all you have left are terminals (and check you arrived at the string your were hoping to) Parsing is the process of checking that a string is in the CFG for your programming language. It is usually coupled with creating an abstract syntax tree.
Elist ::= E Elist ::= Elist , E E ::= ID E ::= NUM E ::= E + E E ::= ( S , Elist ) S ::= S; S S ::= ID := E S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules:
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S ID = E ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S ID = E ID = NUM ; PRINT ( NUM ) oops, can’t make progress
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S S ; S ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S S ; S ID := E ; S ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: Derive me! S S ; S ID = E ; S ID = NUM ; S ID = NUM ; PRINT ( Elist ) ID = NUM ; PRINT ( E ) ID = NUM ; PRINT ( NUM )
8. Elist ::= E 9. Elist ::= Elist , E 4. E ::= ID 5. E ::= NUM 6. E ::= E + E 7. E ::= ( S , Elist ) 1. S ::= S; S 2. S ::= ID := E 3. S ::= PRINT ( Elist ) non-terminals: S, E, Elist terminals: ID, NUM, PRINT, +, :=, (, ), ; rules: S S ; S ID = E ; S ID = NUM ; S ID = NUM ; PRINT ( Elist ) ID = NUM ; PRINT ( E ) ID = NUM ; PRINT ( NUM ) S S ; S S ; PRINT ( Elist ) S ; PRINT ( E ) S ; PRINT ( NUM ) ID = E ; PRINT ( NUM ) ID = NUM ; PRINT ( NUM ) Another way to derive the same string left-most derivation right-most derivation
Parse Trees • Representing derivations as trees • useful in compilers: Parse trees correspond quite closely (but not exactly) with abstract syntax trees we’re trying to generate • difference: abstract syntax vs concrete (parse) syntax • each internal node is labeled with a non-terminal • each leaf note is labeled with a terminal • each use of a rule in a derivation explains how to generate children in the parse tree from the parents
Parse Trees • Example: S S ; S ID = E ; S ID = NUM ; S ID = NUM ; PRINT ( Elist ) ID = NUM ; PRINT ( E ) ID = NUM ; PRINT ( NUM ) S S ; S := E ( L ) ID PRINT E NUM NUM
Parse Trees • Example: 2 derivations, but 1 tree S S ; S ID = E ; S ID = NUM ; S ID = NUM ; PRINT ( Elist ) ID = NUM ; PRINT ( E ) ID = NUM ; PRINT ( NUM ) S S ; S := E ( L ) ID PRINT S S ; S S ; PRINT ( Elist ) S ; PRINT ( E ) S ; PRINT ( NUM ) ID = E ; PRINT ( NUM ) ID = NUM ; PRINT ( NUM ) E NUM NUM
Parse Trees • parse trees have meaning. • order of children, nesting of subtrees is significant S S S S S ; S ; := E ( L ) ( L ) ID PRINT PRINT := E ID E E NUM NUM NUM NUM
Ambiguous Grammars • a grammar is ambiguous if the same sequence of tokens can give rise to two or more parse trees
Ambiguous Grammars characters: 4 + 5 * 6 tokens: NUM(4) PLUS NUM(5) MULT NUM(6) E non-terminals: E terminals: ID NUM PLUS MULT E ::= ID | NUM | E + E | E * E E + E E E * NUM(4) NUM(6) NUM(5) I like using this notation where I avoid repeating E ::=
Ambiguous Grammars characters: 4 + 5 * 6 tokens: NUM(4) PLUS NUM(5) MULT NUM(6) E non-terminals: E terminals: ID NUM PLUS MULT E ::= ID | NUM | E + E | E * E E + E E E * NUM(4) NUM(6) NUM(5) E E * E E E + NUM(6) NUM(5) NUM(4)
Ambiguous Grammars • problem: compilers use parse trees to interpret the meaning of parsed expressions • different parse trees have different meanings • eg: (4 + 5) * 6 is not 4 + (5 * 6) • languages with ambiguous grammars are DISASTROUS; The meaning of programs isn’t well-defined! You can’t tell what your program might do! • solution: rewrite grammar to eliminate ambiguity • fold precedence rules into grammar to disambiguate • fold associativity rules into grammar to disambiguate • other tricks as well
Building Parsers • In theory classes, you might have learned about general mechanisms for parsing all CFGs • algorithms for parsing all CFGs are expensive • to compile 1/10/100 million-line applications, compilers must be fast. • even for 10 thousand-line apps, speed is nice • sometimes 1/3 of compilation time is spent in parsing • compiler writers have developed specialized algorithms for parsing the kinds of CFGs that you need to build effective programming languages • LL(k), LR(k) grammars can be parsed.
Recursive Descent Parsing • Recursive Descent Parsing (Appel Chap 3.2): • aka: predictive parsing; top-down parsing • simple, efficient • can be coded by hand in ML quickly • parses many, but not all CFGs • parses LL(1) grammars • Left-to-right parse; Leftmost-derivation; 1 symbol lookahead • key ideas: • one recursive function for each non terminal • each production becomes one clause in the function
non-terminals: S, E, L terminals: NUM, IF, THEN, ELSE, BEGIN, END, PRINT, ;, = rules: 1. S ::= IF E THEN S ELSE S 2. | BEGIN S L 3. | PRINT E 4. L ::= END 5. | ; S L 6. E ::= NUM = NUM
non-terminals: S, E, L terminals: NUM, IF, THEN, ELSE, BEGIN, END, PRINT, ;, = rules: 1. S ::= IF E THEN S ELSE S 2. | BEGIN S L 3. | PRINT E 4. L ::= END 5. | ; S L 6. E ::= NUM = NUM Step 1: Represent the tokens datatype token = NUM | IF | THEN | ELSE | BEGIN | END | PRINT | SEMI | EQ Step 2: build infrastructure for reading tokens from lexing stream val tok = ref (getToken ()) fun advance () = tok := getToken () fun eat t = if (! tok = t) then advance () else error ()
non-terminals: S, E, L terminals: NUM, IF, THEN, ELSE, BEGIN, END, PRINT, ;, = rules: 1. S ::= IF E THEN S ELSE S 2. | BEGIN S L 3. | PRINT E 4. L ::= END 5. | ; S L 6. E ::= NUM = NUM Step 1: Represent the tokens datatype token = NUM | IF | THEN | ELSE | BEGIN | END | PRINT | SEMI | EQ Step 2: build infrastructure for reading tokens from lexing stream val tok = ref (getToken ()) fun advance () = tok := getToken () fun eat t = if (! tok = t) then advance () else error ()
non-terminals: S, E, L terminals: NUM, IF, THEN, ELSE, BEGIN, END, PRINT, ;, = rules: 1. S ::= IF E THEN S ELSE S 2. | BEGIN S L 3. | PRINT E 4. L ::= END 5. | ; S L 6. E ::= NUM = NUM datatype token = NUM | IF | THEN | ELSE | BEGIN | END | PRINT | SEMI | EQ val tok = ref (getToken ()) fun advance () = tok := getToken () fun eat t = if (! tok = t) then advance () else error () Step 3: write parser => one function per non-terminal; one clause per rule fun S () = case !tok of IF => eat IF; E (); eat THEN; S (); eat ELSE; S () | BEGIN => eat BEGIN; S (); L () | PRINT => eat PRINT; E () and L () = case !tok of END => eat END | SEMI => eat SEMI; S (); L () and E () = eat NUM; eat EQ; eat NUM
non-terminals: A, S, E, L rules: 1. A ::= S EOF 2. | ID := E 3. | PRINT ( L ) 4. E ::= ID 5. | NUM 6. L ::= E 7. | L , E fun A () = S (); eat EOF and S () = case !tok of ID => eat ID; eat ASSIGN; E () | PRINT => eat PRINT; eat LPAREN; L (); eat RPAREN and E () = case !tok of ID => eat ID | NUM => eat NUM and L () = case !tok of ID => ??? | NUM => ???
problem • predictive parsing only works for grammars where the first terminal symbol of each self-expression provides enough information to choose which production to use • LL(1) • if !tok = ID, the parser cannot determine which production to use: 6. L ::= E (E could be ID) 7. | L , E (L could be E could be ID)
solution • eliminate left-recursion • rewrite the grammar so it parses the same language but the rules are different: A ::= S EOF | ID := E | PRINT ( L ) E ::= ID | NUM A ::= S EOF | ID := E | PRINT ( L ) E ::= ID | NUM L ::= E M M ::= , E M | L ::= E | L , E
eliminating left-recursion in general • Original grammar form: • Transformed grammar: X ::= base X ::= X repeat Strings: base repeat repeat ... X ::= base Xnew Xnew ::= repeat Xnew Xnew ::= Strings: base repeat repeat ...
Recursive Descent Parsing • Unfortunately, left factoring doesn’t always work • Questions: • how do we know when we can parse grammars using recursive descent? • Is there an algorithm for generating such parsers automatically?
Constructing RD Parsers • To construct an RD parser, we need to know what rule to apply when • we have seen a non terminal X • we see the next terminal a in input • We apply rule X ::= s when • a is the first symbol that can be generated by string s, OR • s reduces to the empty string (is nullable) and a is the first symbol in any string that can follow X
Constructing RD Parsers • To construct an RD parser, we need to know what rule to apply when • we have seen a non terminal X • we see the next terminal a in input • We apply rule X ::= s when • a is the first symbol that can be generated by string s, OR • s reduces to the empty string (is nullable) and a is the first symbol in any string that can followX
Constructing Predictive Parsers 1. Y ::= 2. | bb 5. Z ::= d 3. X ::= c 4. | Y Z next terminal rule non-terminal seen
Constructing Predictive Parsers 1. Y ::= 2. | bb 5. Z ::= d 3. X ::= c 4. | Y Z next terminal rule non-terminal seen
Constructing Predictive Parsers 1. Y ::= 2. | bb 5. Z ::= d 3. X ::= c 4. | Y Z next terminal rule non-terminal seen
Constructing Predictive Parsers 1. Y ::= 2. | bb 5. Z ::= d 3. X ::= c 4. | Y Z next terminal rule non-terminal seen
Constricting Predictive Parsers • in general, must compute: • for each production X ::= s, must determine if s can derive the empty string. • if yes, X Nullable • for each production X := s, must determine the set of all first terminals Q derivable from s • Q First(X) • for each non terminal X, determine all terminals symbols Q that immediately follow X • Q Follow(X)
Iterative Analysis • Many compilers algorithms are iterative techniques. • Iterative analysis applies when: • must compute a set of objects with some property P • P is defined inductively. ie, there are: • base cases: objects o1, o2 “obviously” have property P • inductive cases: if certain objects (o3, o4) have property P, this implies other objects (f o3; f o4) have property P • The number of objects in the set is finite • or we can represent infinite collections using some finite notation & we can find effective termination conditions
Iterative Analysis • general form: • initialize set S with base cases • applied inductive rules over and over until you reach a fixed point • a fixed point is a set that does not change when you apply an inductive rule • Nullable, First and Follow sets can be determined through iteration • many program optimizations use iteration • worst-case complexity is bad • average-case complexity is good: iteration “usually” terminates in a couple of rounds
Computing Nullable Sets • Non-terminal X is Nullable only if the following constraints are satisfied (computed using iterative analysis) • base case: • if (X := ) then X is Nullable • inductive case: • if (X := ABC...) and A, B, C, ... are all Nullable then X is Nullable
Computing First Sets • First(X) is computed iteratively • base case: • if T is a terminal symbol then First (T) = {T} • inductive case: • if X is a non-terminal and (X:= ABC...) then • First (X) = First (X) U First (ABC...) where First(ABC...) = F1 U F2 U F3 U ... and • F1 = First (A) • F2 = First (B), if A is Nullable • F3 = First (C), if A is Nullable & B is Nullable • ...
Computing Follow Sets • Follow(X) is computed iteratively • base case: • initially, we assume nothing in particular follows X • (Follow (X) is initially { }) • inductive case: • if (Y := s1 X s2) for any strings s1, s2 then • Follow (X) = First (s2) UFollow (X) • if (Y := s1 X s2) for any strings s1, s2 then • Follow (X) = Follow(Y) UFollow (X), if s2 is Nullable
building a predictive parser Y ::= c Y ::= X ::= a X ::= b Y e Z ::= X Y Z Z ::= d
building a predictive parser Y ::= c Y ::= X ::= a X ::= b Y e Z ::= X Y Z Z ::= d base case
building a predictive parser Y ::= c Y ::= X ::= a X ::= b Y e Z ::= X Y Z Z ::= d after one round of induction, we realize we have reached a fixed point
building a predictive parser Y ::= c Y ::= X ::= a X ::= b Y e Z ::= X Y Z Z ::= d base case