Download
1 / 1
10 likes | 112 Views
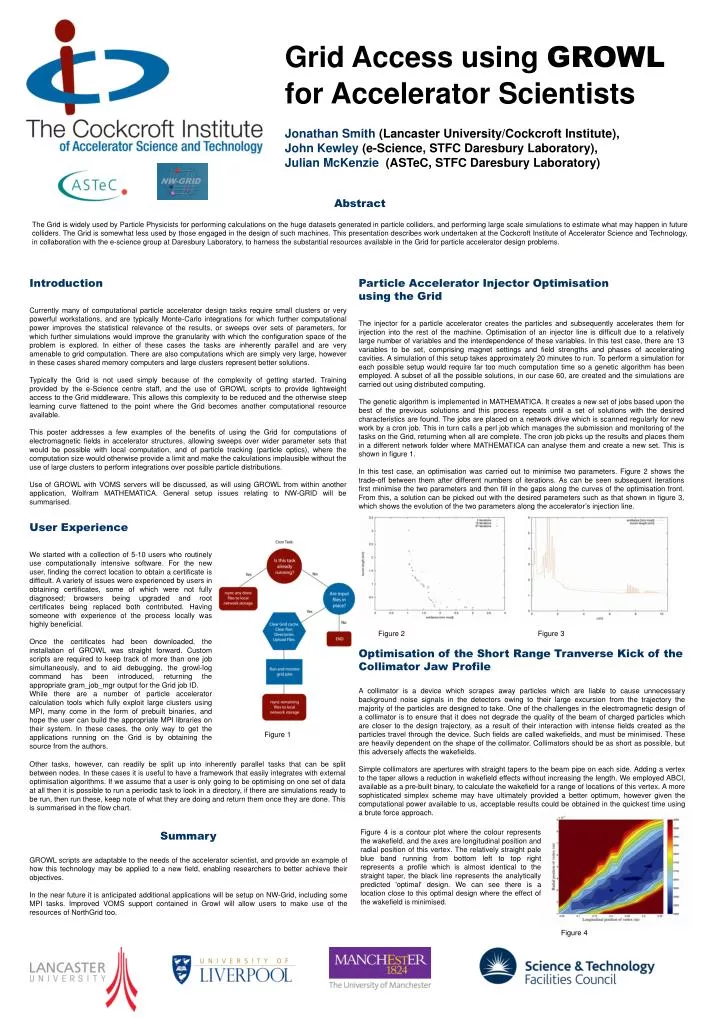
Grid Access using GROWL for Accelerator Scientists Jonathan Smith (Lancaster University/Cockcroft Institute), John Kewley (e-Science, STFC Daresbury Laboratory), Julian McKenzie (ASTeC, STFC Daresbury Laboratory) . Abstract

E N D
Grid Access using GROWLfor Accelerator Scientists Jonathan Smith (Lancaster University/Cockcroft Institute), John Kewley (e-Science, STFC Daresbury Laboratory), Julian McKenzie (ASTeC, STFC Daresbury Laboratory) Abstract The Grid is widely used by Particle Physicists for performing calculations on the huge datasets generated in particle colliders, and performing large scale simulations to estimate what may happen in future colliders. The Grid is somewhat less used by those engaged in the design of such machines. This presentation describes work undertaken at the Cockcroft Institute of Accelerator Science and Technology, in collaboration with the e-science group at Daresbury Laboratory, to harness the substantial resources available in the Grid for particle accelerator design problems. Introduction Currently many of computational particle accelerator design tasks require small clusters or very powerful workstations, and are typically Monte-Carlo integrations for which further computational power improves the statistical relevance of the results, or sweeps over sets of parameters, for which further simulations would improve the granularity with which the configuration space of the problem is explored. In either of these cases the tasks are inherently parallel and are very amenable to grid computation. There are also computations which are simply very large, however in these cases shared memory computers and large clusters represent better solutions. Typically the Grid is not used simply because of the complexity of getting started. Training provided by the e-Science centre staff, and the use of GROWL scripts to provide lightweight access to the Grid middleware. This allows this complexity to be reduced and the otherwise steep learning curve flattened to the point where the Grid becomes another computational resource available. This poster addresses a few examples of the benefits of using the Grid for computations of electromagnetic fields in accelerator structures, allowing sweeps over wider parameter sets that would be possible with local computation, and of particle tracking (particle optics), where the computation size would otherwise provide a limit and make the calculations implausible without the use of large clusters to perform integrations over possible particle distributions. Use of GROWL with VOMS servers will be discussed, as will using GROWL from within another application, Wolfram MATHEMATICA. General setup issues relating to NW-GRID will be summarised. Particle Accelerator Injector Optimisation using the Grid The injector for a particle accelerator creates the particles and subsequently accelerates them for injection into the rest of the machine. Optimisation of an injector line is difficult due to a relatively large number of variables and the interdependence of these variables. In this test case, there are 13 variables to be set, comprising magnet settings and field strengths and phases of accelerating cavities. A simulation of this setup takes approximately 20 minutes to run. To perform a simulation for each possible setup would require far too much computation time so a genetic algorithm has been employed. A subset of all the possible solutions, in our case 60, are created and the simulations are carried out using distributed computing. The genetic algorithm is implemented in MATHEMATICA. It creates a new set of jobs based upon the best of the previous solutions and this process repeats until a set of solutions with the desired characteristics are found. The jobs are placed on a network drive which is scanned regularly for new work by a cron job. This in turn calls a perl job which manages the submission and monitoring of the tasks on the Grid, returning when all are complete. The cron job picks up the results and places them in a different network folder where MATHEMATICA can analyse them and create a new set. This is shown in figure 1. In this test case, an optimisation was carried out to minimise two parameters. Figure 2 shows the trade-off between them after different numbers of iterations. As can be seen subsequent iterations first minimise the two parameters and then fill in the gaps along the curves of the optimisation front. From this, a solution can be picked out with the desired parameters such as that shown in figure 3, which shows the evolution of the two parameters along the accelerator’s injection line. User Experience We started with a collection of 5-10 users who routinely use computationally intensive software. For the new user, finding the correct location to obtain a certificate is difficult. A variety of issues were experienced by users in obtaining certificates, some of which were not fully diagnosed; browsers being upgraded and root certificates being replaced both contributed. Having someone with experience of the process locally was highly beneficial. Once the certificates had been downloaded, the installation of GROWL was straight forward. Custom scripts are required to keep track of more than one job simultaneously, and to aid debugging, the growl-log command has been introduced, returning the appropriate gram_job_mgr output for the Grid job ID. While there are a number of particle accelerator calculation tools which fully exploit large clusters using MPI, many come in the form of prebuilt binaries, and hope the user can build the appropriate MPI libraries on their system. In these cases, the only way to get the applications running on the Grid is by obtaining the source from the authors. Figure 2 Figure 3 Optimisation of the Short Range Tranverse Kick of the Collimator Jaw Profile A collimator is a device which scrapes away particles which are liable to cause unnecessary background noise signals in the detectors owing to their large excursion from the trajectory the majority of the particles are designed to take. One of the challenges in the electromagnetic design of a collimator is to ensure that it does not degrade the quality of the beam of charged particles which are closer to the design trajectory, as a result of their interaction with intense fields created as the particles travel through the device. Such fields are called wakefields, and must be minimised. These are heavily dependent on the shape of the collimator. Collimators should be as short as possible, but this adversely affects the wakefields. Simple collimators are apertures with straight tapers to the beam pipe on each side. Adding a vertex to the taper allows a reduction in wakefield effects without increasing the length. We employed ABCI, available as a pre-built binary, to calculate the wakefield for a range of locations of this vertex. A more sophisticated simplex scheme may have ultimately provided a better optimum, however given the computational power available to us, acceptable results could be obtained in the quickest time using a brute force approach. Figure 1 Other tasks, however, can readily be split up into inherently parallel tasks that can be split between nodes. In these cases it is useful to have a framework that easily integrates with external optimisation algorithms. If we assume that a user is only going to be optimising on one set of data at all then it is possible to run a periodic task to look in a directory, if there are simulations ready to be run, then run these, keep note of what they are doing and return them once they are done. This is summarised in the flow chart. Figure 4 is a contour plot where the colour represents the wakefield, and the axes are longitudinal position and radial position of this vertex. The relatively straight pale blue band running from bottom left to top right represents a profile which is almost identical to the straight taper, the black line represents the analytically predicted 'optimal' design. We can see there is a location close to this optimal design where the effect of the wakefield is minimised. Summary GROWL scripts are adaptable to the needs of the accelerator scientist, and provide an example of how this technology may be applied to a new field, enabling researchers to better achieve their objectives. In the near future it is anticipated additional applications will be setup on NW-Grid, including some MPI tasks. Improved VOMS support contained in Growl will allow users to make use of the resources of NorthGrid too. Figure 4