Synthesis of Array Operations in Distributed-Memory Systems Using High Performance Fortran
280 likes | 403 Views
This study presents the application of Array Operation Synthesis (AOS) in distributed-memory systems, utilizing an 8-node DEC Alpha farm and IBM SP2 with High Performance Fortran (HPF) compilers. It details performance enhancements observed in various numerical algorithms, documenting speedups ranging from 1.6 to 10.4. We introduce a heuristic algorithm to tackle the NP-hard problem of optimal data layout, focusing on minimizing remote references while examining the implications of data access patterns post-AOS. Additionally, the findings demonstrate the viability of segmented alignment techniques for improved array operation efficiency.

Synthesis of Array Operations in Distributed-Memory Systems Using High Performance Fortran
E N D
Presentation Transcript
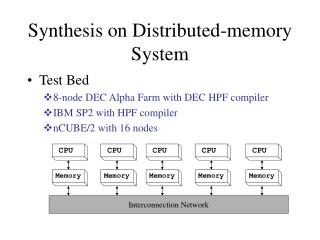
Synthesis on Distributed-memory System • Test Bed • 8-node DEC Alpha Farm with DEC HPF compiler • IBM SP2 with HPF compiler • nCUBE/2 with 16 nodes CPU CPU CPU CPU CPU Memory Memory Memory Memory Memory Interconnection Network
HPF Example REAL A(N,2*N), B(2*N), C(2*N,2*N) REAL D(2*N,N), E(N), F(N), G(N) !HPF TEMPLATE TEMP(N*N*4,N*N*4) !HPF ALIGN A(i,j) WITH TEMP(4*i-3,4*j-3) !HPF ALIGN B(i) WITH TEMP(*,4*i-3) !HPF ALIGN C(i,j) WITH TEMP(4*j-3,i) !HPF ALIGN D(i,j) WITH TEMP(4*j-3,4*i-3) !HPF ALIGN G(i) WITH TEMP(4*i-3,*) D=C(:,1:4*N:4) E=SUM(A+TRANSPOSE(D),DIM=2) F=SUM(SPREAD(B,DIM=2,NCOPIES=N)+D,DIM=1) G=B(1:2*N:2)+E+F S. Chatterjee et al. “Automatic Array Alignment in Data-Parallel Programs” ACM Symposium on Principles of Programming Languages,1993.
HPF Example (Cont’d) • We execute the codes by DEC HPF Compiler on 8-node DEC Farm with an FDDI network. • Loop 100 times. N is set to 128.
Apply Array Operation Synthesis to Distributed-memory Machines • Owner Computes Rule of HPF • Memory References of Distributed-memory Machines • Local References • Remote References(Communication)
Synthesis Anomaly Array Operation Synthesis may either • Example of Synthesis Anomaly decrease Remote References or GOOD increase Remote References or Require more communication time Synthesis Anomaly !HPF TEMPLATE TEMP(N,N) REAL A(N,N),B(N,N),C(N,N) !HPF ALIGN A(I,J),B(I,J),C(I,J)WITH TEMP(I,J) C=TRANSPOSE(A+B,1)
Evaluating Array Expression Optimal Solution is NP-hard • Except the optimal solution, we also propose a heuristic algorithm. Under the Owner Computes Rule To Synthesize Part of Array Operations To Find Data Layout of Temporary Arrays
A Heuristic to Reduce Synthesis Anomaly Do Array Operation Synthesis Does synthesis increase communication cost? Roll back temporary arrays Do code generation normally
Reference Location !HPF$ ALIGN F(I,J) WITH TEMP(3*I-1,J) • The reference location of F(2*J-1,I) with respect to TEMP is: TEMP(3*(2*J-1)-1,I)=TEMP(6*J-4,I)
Demonstration Example of Heuristic Algorithm !HPF$ TEMPLATE TEMP(300,300) REAL A(100,100),B(100,100),C(100,100) REAL D(100,100),E(100,100),F(200,100), G(300,100) !HPF$ ALIGN A(i,j),B(i,j),C(i,j),D(i,j),E(i,j) with TEMP(i,j) !HPF$ ALIGN F(i,j) with TEMP(3*i-1,j) !HPF$ ALIGN G(i,j) with TEMP(2*i,j) C(1:100,:)=F(1:200:2,:) D(1:100,:)=G(1:300:3,:) E=CSHIFT(TRANSPOSE(A+B),1,1 )*(TRANSPOSE(C)-TRANSPOSE(D) ) Do Array Operation Synthesis FORALL (I=1:99,J=1:100) E(I,J)=(A[J,I+1]+B[J,I+1])*(F[2*J-1,I]-G[3*J-2,I]) END FORALL FORALL (I=100:100,J=1:100) E(I,J)=(A[J,I-99]+B[J,I-99])*(F[2*J-1,I]-G[3*J-2,I]) END FORALL
Heuristic Algorithm (1) E(I,J)=(A[J,I+1]+B[J,I+1])*(F[2*J-1,I]-G[3*J-2,I]) E[I,J] F[2*J-1,I] A[J,I+1] B[J,I+1] G[3*J-2,I]
TEMP[I,J] TEMP[6*J-4,I] TEMP[J,I+1] TEMP[6*J-4,I] TEMP[J,I+1]
SB1 SB2
Heuristic Algorithm (1) E(I,J)=(A[J,I+1]+B[J,I+1])*(F[2*J-1,I]-G[3*J-2,I]) E[I,J] TEMP[I,J] SB1 SB2 F[2*J-1,I] A[J,I+1] B[J,I+1] G[3*J-2,I] TEMP[6*J-4,I] TEMP[J,I+1] TEMP[6*J-4,I] TEMP[J,I+1]
Heuristic Algorithm (2) !HPF$ ALIGN TA1(I,J) WITH TEMP(J,I+1) !HPF$ ALIGN TA2(I,J) WITH TEMP(6*J-4,I) • Create Temporary Arrays FORALL (I=1:99,J=1:100) TA1(I,J) =A(J,I+1)+B(J,I+1) END FORALL Communication Free Loop For Subtree SB1 FORALL (I=1:99,J=1:100) TA2(I,J) =F(2*J-1,I)-G(3*J-2,I) END FORALL For Subtree SB2 Communication Free Loop FORALL (I=1:99,J=1:100) E(I,J)=TA1(I,J)*TA2(I,J) END FORALL
Experimental Results on DEC Workstation Farm (N=128) (Purdue-set Problem 9) (APULE routine electromagnetic scattering problem)
Experimental Results on DEC Workstation Farm (N=128) (Sandia Wave)
Experimental Results on IBM SP2 (N=512) (Purdue-set Problem 9) (APULE routine electromagnetic scattering problem)
Experimental Results on IBM SP2 (N=512) (Sandia Wave)
Array Operation Synthesis in Distributed-memory Machines • Optimal solution is NP-hard • A heuristic algorithm for code generation • Experimental results show speedups from 1.6 to 10.4 for HPF code fragments on DEC alpha farm and IBM SP2 • We demonstrated that it is also profitable in applying AOS to HPF programs
Integrating AOS and Automatic Data Alignment • Data Alignment Directive in HPF is with continuous semantics • The data access patterns after applying AOS may not be continuous • We propose Segmented Alignment !HPF$ ALIGN TA2(I,J) WITH TEMP(6*J-4,I)
Segmented Alignment • To align Arrays in a specified index domain • Implementation of Segmented Alignment • Split an array into several subarrays !HPF$ ALIGN TA2(I,J) WITH TEMP(6*J-4,I) WHEN (I,J) IN (1:N/2:1, N/2:N:1)
Conclusion • The Array Operation Synthesis can handle RESHAPE, SPREAD, CSHIFT, EOSHIFT, TRANSPOSE, MERGE, section movement, reduction operations, and WHERE construct • The measured speedups from real applications between 1.21 and 7.55 in Sequent S27 and SGI Power Challenge. • Experimental results show speedups from 1.6 to 10.4 for HPF code fragments from real applications on DEC alpha Farm and IBM SP2
Future Work • To handle PACK, UNPACK and Matrix Multiplication • Integrating Automatic Data Alignment and AOS • Synthesis for array operation functions which includes message passing codes • Applying AOS toward a more extensive set of data parallel programs
Future Work • To handle PACK, UNPACK and Matrix Multiplication • Synthesis for array operation functions which includes message passing codes • Applying AOS toward a more extensive set of data parallel programs





















