Principal Components as a Projection on a Orthogonal Basis
120 likes | 348 Views
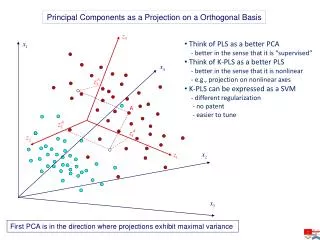
A. Principal Components as a Projection on a Orthogonal Basis. Think of PLS as a better PCA - better in the sense that it is “supervised” Think of K-PLS as a better PLS - better in the sense that it is nonlinear - e.g., projection on nonlinear axes

Principal Components as a Projection on a Orthogonal Basis
E N D
Presentation Transcript
A Principal Components as a Projection on a Orthogonal Basis • Think of PLS as a better PCA • - better in the sense that it is “supervised” • Think of K-PLS as a better PLS • - better in the sense that it is nonlinear • - e.g., projection on nonlinear axes • K-PLS can be expressed as a SVM • - different regularization • - no patent • - easier to tune First PCA is in the direction where projections exhibit maximal variance
Kernel PLS vs Support vector machines, SVMs • Unlike SVMs, K-PLS is not patented • - SVM patent was explicitly tagged in sale of patent portfolio from ATT to Canadian company • - SVM patents keep being updated • K-PLS is like PLS in kernel space • K-PLS is easy to tune (usually 5 latent variables), just kernel sigma with tuning data • K-PLS and SVM have similar loss functions to minimize: • - SVM has a one norm, K-PLS has a two-norm in the loss function • - both SVM and K-PLS regularize weights • - more latent variables in K-PLS implies larger weights
Linear and Nonlinear Principal Components: ReplaceXnmby Tnh • PCA: Create a reduced feature set from original attributes • PCAs: Are orthogonal projections in directions of largest variance • PCA calculations can be done with Svante Wold’s NIPALS algorithm • - elegant and efficient algorithm • - hidden gem of an algorithm (not well known at all) • PCAs can also be calculation with specialized neural networks (Erikki Oja) • Related Methods: Partial-Least Squares (PLS) • Independent component analysis (ICA) • Other reduced sets feature via wavelet and Fourier transforms, …
ICANN 2009 Toxicity Prediction challenge: second (and very close) runner up for predictabilty
MKMJE= Michael Krein + Mark Embrechts Highest R2 and highest Percentage correct within 0.5 logS
Kernel Principal Components Trick • We now use a data kernel • Rather than using a linear kernel we use a nonlinear kernel • Keep a “few happy” principal components for the loads • Calculate principal components from nonlinear kernel matrix
The most important Trick to make it work: Kernel Centering Centered Direct Kernel (Training Data) Training Data Mahalanobis-scaled Training Data Kernel Transformed Training Data Mahalanobis Scaling Factors Vertical Kernel Centering Factors Centered Direct Kernel (Test Data) Test Data Mahalanobis-scaled Test Data Kernel Transformed Test Data • Calculate averages for kernel matrix columns • Subtract averages, and store for use on kernel of test data • Calculate averages rows and subtract average • Do consistent centering on test kernel (use column average from training kernel)
K-PCA Application: Find hidden order in classes and reorder classes REM GET OLIVE DATA (6) dmak olive 3301 REM SCALE DATA dmak olive -3 REM DO K-PCA (5 1 4) dmak num_eg.txt 105 kpls5 olive.txt -17 REM PLOT (1 2) bbmeta tt.txt 23