Download

1 / 27
270 likes | 428 Views
Lecture 9 – Nonlinear Programming Models. Topics Convex sets and convex programming First-order optimality conditions Examples Problem classes. General NLP. Minimize f ( x ). s.t. g i ( x ) ( , , =) b i , i = 1,…, m.

E N D
Lecture 9 – Nonlinear Programming Models Topics • Convex sets and convex programming • First-order optimality conditions • Examples • Problem classes
General NLP Minimize f(x) s.t. gi(x) (, , =) bi, i = 1,…,m x = (x1,…,xn)T is the n-dimensional vector of decision variables f(x) is the objective function gi(x) are the constraint functions bi are fixed known constants
Convex Sets Definition: A set Sn is convex if every point on the line segment connecting any two points x1, x2ÎS is also in S. Mathematically, this is equivalent to x0 = lx1 + (1–l)x2ÎS for all l such 0 ≤ l ≤ 1. x1 x2 x1 x1 x2 x2
(Nonconvex) Feasible Region S = {(x1, x2) : (0.5x1 – 0.6)x2 ≤ 1 2(x1)2 + 3(x2)2 ≥ 27; x1, x2 ≥ 0}
Convex Sets and Optimization Let S = { xÎn : gi(x) £bi, i = 1,…,m } Fact:If gi(x) is a convex function for each i = 1,…,m then S is a convex set. Convex Programming Theorem: Let xn and let f(x) be a convex function defined over a convex constraint set S. If a finite solution exists to the problem Minimize { f(x) : xÎS } then all local optima are global optima. If f(x) is strictly convex, the optimum is unique.
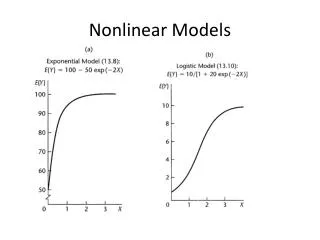
Convex Programming Min f(x1,…,xn) s.t. gi(x1,…,xn) £bi i = 1,…,m x1 ³ 0,…,xn ³ 0 is a convex program if fis convex and each giis convex. Max f(x1,…,xn) s.t. gi(x1,…,xn) £bi i = 1,…,m x1 ³ 0,…,xn ³ 0 is a convex program if fis concave and each gi is convex.
Linearly Constrained Convex Function with Unique Global Maximum Maximize f(x) = (x1 – 2)2 + (x2 – 2)2 subject to –3x1 – 2x2 ≤ –6 –x1 + x2 ≤ 3 x1 + x2 ≤ 7 2x1 – 3x2 ≤ 4
Optimality conditions • Stationarity: • Complementarity: migi(x) = 0, i = 1,…,m • Feasibility: gi(x) bi, i = 1,…,m • Nonnegativity: mi 0, i = 1,…,m First-Order Optimality Conditions Minimize { f(x) : gi(x) bi, i = 1,…,m } Lagrangian:
Importance of Convex Programs Commercial optimization software cannot guarantee that a solution is globally optimal to a nonconvex program. NLP algorithms try to find a point where the gradient of the Lagrangian function is zero – a stationary point – and complementary slackness holds. Given L(x,m) = f(x) + m(g(x) – b) we want L(x,m) = f(x) + mg(x) = 0 m(g(x) – b) = 0 g(x) – b ≤0, m³ 0 For a convex program, all local solutions are global optima.
Max V(r,h) = pr2h s.t. 2pr2 + 2prh = s r³ 0, h³ 0 r h There are a number of ways to approach this problem. One way is to solve the surface area constraint for h and substitute the result into the objective function. Example: Cylinder Design We want to build a cylinder (with a top and a bottom) of maximum volume such that its surface area is no more than s units.
Solution by Substitution s - 2pr2 s - 2pr2 rs Volume = V = pr2 - pr3 [ ] = h = 2 2r 2pr 1/2 dV s s s 1/2 = 0 - r = ( ) h = r = 2( ) 2pr p p dr 6 6 s 3/2 s s 1/2 1/2 ( ) V = pr2h = 2p r = ( ) ) h = 2( p 6 p 6 6 Is this a global optimal solution?
Test for Convexity dV(r) s d2V(r) rs = 6pr - 3pr2 = - pr3 V(r) = dr 2 2 dr2 2 d V £ 0 for all r ³ 0 dr2 Thus V(r) is concave on r ³ 0 so the solution is a global maximum.
Model: Max f(x) = 6(x1)1/2 + 4(x2)1/2 s.t. x1 + x2£ 100, x1³ 0, x2³ 0 Solution:x1* = 69.2, x2* = 30.8, f(x*) = 72.1 Is this a global optimum? Advertising (with Diminishing Returns) • A company wants to advertise in two regions. • The marketing department says that if $x1 is spent in region 1, sales volume will be 6(x1)1/2. • If $x2 is spent in region 2, sales volume will be 4(x2)1/2. • The advertising budget is $100.
Portfolio Selection with Risky Assets (Markowitz) • Suppose that we may invest in (up to) n stocks. • Investors worry about (1) expected gain (2) risk. Let rj = random variable associated with return on stock j mj = expected return on stock j sjj = variance of return for stock j We are also concerned with the covariance terms: sij= cov(ri, rj) If sij > 0 then returns on i and j are positively correlated. If sij < 0 returns are negatively correlated.
If x1 = x2 = 1, we get Example: V(x) = s11x1x1 + s12x1x2 + s21x2x1 + s22x2x1 = 1 + (-1) + (-1) + 1 = 0 Thus we can construct a “risk-free” portfolio (from variance point of view) if we can find stocks “fully” negatively correlated. Decision Variables: xj= # of shares of stock j purchased n j =1 R(x) = åmjxj Expected return of the portfolio: n j =1 n i =1 V(x) = å å sijxixj Variance (measure of risk):
If , then buying stock 2 is just like buying additional shares of stock 1. Nonlinear optimization models … Let pj = price of stock j b = our total budget b = risk-aversion factor (when b = 0 risk is not a factor) Consider 3 different models: 1) Max f(x) = R(x) – bV(x) s.t. å pj xj £ b, xj³ 0, j = 1,…,n where b ³ 0 is determined by the decision maker n j =1
3) Min f(x) = V(x) s.t. R(x) ³ g, å pj xj £ b, xj³ 0, j = 1,…,n where g ³ 0 is the desired rate of return (minimum expectation) is selected by the investor. n j =1 • Max f(x) = R(x) • s.t. V(x) £ a, å pjxj £ b, xj³ 0, j = 1,…,n • where a ³ 0 is determined by the investor. Smaller values of a represent greater risk aversion. n j =1
10ft 1 ft x each link y Decision variables: Let (xj, yj), j = 1,…,n, be the incremental horizontal and vertical displacement of each link, where n³ 10. Constraints: xj2 + yj2 = 1, j = 1,…,n, each link has length 1 x1 + x2 + • • • + xn = 10,net horizontal displacement y1 + y2 + • • • + yn = 0,net vertical displacement Hanging Chain with Rigid Links What is equilibrium shape of chain?
1 1 1 y3) + • • • y1 + (y1 + y2) + (y1 + y2 + 2 2 2 1 (y1 + y2 + • • • + yn-1 + yn) + 2 1 1 = (n - 1 + ]y1 + (n - 2 + )y2 2 2 1 3 1 )y3+ • • • + yn-1 + yn + (n - 3 + 2 2 2 Summary n j =1 s.t. xj2 + yj2 = 1, j = 1,…,n x1 + x2 + • • • + xn = 10 y1 + y2 + • • • + yn = 0 Min å (n- j + ½)yj Objective: Minimize chain’s potential energy Assuming that the center of the mass of each link is at the center of the link. This is equivalent to minimizing
Constraints xj2 + yj2 = 1 for all j yield a nonconvex feasible region so there may be several local optima. Consider a chain with 4 links: These solutions are both local minima. Is a local optimum guaranteed to be a global optimum? No!
Direct Current Network Problem: Determine the current flows I1, I2,…,I7 so that the total content is minimized Content: G(I) = 0Iv(i)di for I ≥ 0 and G(I) = I 0v(i)di for I < 0
Solution Approach Electrical Engineering: Use Kirchoff’s laws to find currents when power source is given. Operations Research: Optimize performance measure in network taking flow balance into account. Linear resistor: Voltage, v(I ) = IR Content function, G(I ) = I 2R/2 Battery: Voltage, v(I ) = –E Content function, G(I ) = –EI
Network diagram: Network Flow Model Minimize Z = –100I1 + 5I22 + 5I32 + 10I42 + 10I52 subject to I1 – I2 = 0, I2 – I3 – I4 = 0, I5 – I6 = 0, I5 + I7 = 0, I3 + I6 – I7 = 0, –I1 – I6 = 0 Solution: I1 = I2 = 50/9, I3 = 40/9, I4 = I5 = 10/9, I6 = –50/9, I7 = –10/9
NLP Problem Classes • Constrained vs. unconstrained • Convex programming problem • Quadratic programming problem f(x) = a + cTx + ½ xTQx, Q 0 • Separable programming problem f(x) = j=1,n fj(xj) • Geometric programming problem g(x) = t=1,T ctPt(x), Pt(x) = (x1at1) . . . (xnatn), xj > 0 • Equality constrained problems
What You Should Know About Nonlinear Programming • How to identify a convex program. • How to write out the first-order optimality conditions. • The difference between a local and global solution. • How to classify problems.