Download
1 / 59
590 likes | 698 Views
Closed Loop Temporal Sequence Learning Learning to act in response to sequences of sensor events. Overview over different methods. You are here !. Natural Temporal Sequences in life and in “control” situations. Real Life Heat radiation predicts pain when touching a hot surface.

E N D
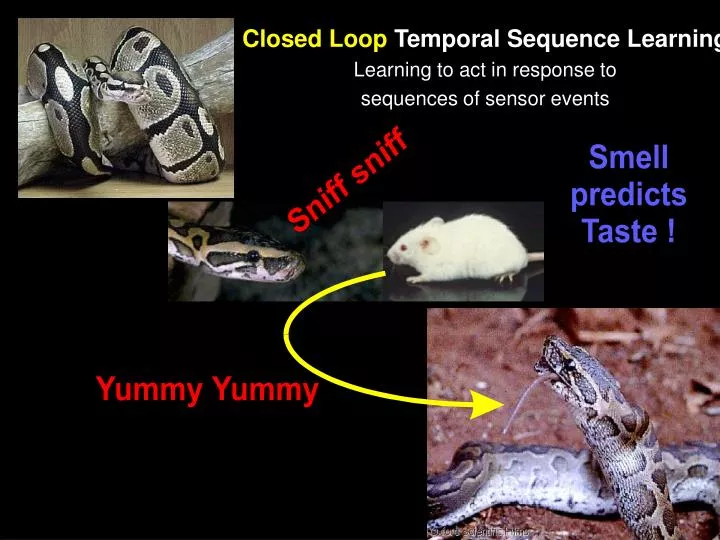
Closed Loop Temporal Sequence Learning Learning to act in response to sequences of sensor events
Overview over different methods You are here !
Natural Temporal Sequences in life and in “control” situations Real Life • Heat radiation predicts pain when touching a hot surface. • Sound of a prey may precede its smell will precede its taste. Control • Force precedes position change. • Electrical (disturbance) pulse may precede change in a controlled plant. Psychological Experiment • Pavlovian and/or Operant Conditioning: Bell precedes Food.
x What we had so far ! Early: “Bell” w S Late: “Food”
Sensor 2 Pavlov, 1927 Bell Food Salivation Temporal Sequence This is an Open Loop System ! conditioned Input This is an open-loop system
Closed loop Behaving Sensing Adaptable Neuron Env.
Remove before being hit ! How to assure behavioral & learning convergence ?? This is achieved by starting with a stable reflex-like action and learning to supercede it by an anticipatory action.
w S Early: “Vision” Late: “Bump” x Robot Application
Reflex Only (Compare to an electronic closed loop controller!) Think of a Thermostat ! This structure assures initial (behavioral) stability (“homeostasis”)
This is a closed-loop system before learning Retraction reflex Bump The Basic Control Structure Schematic diagram of A pure reflex loop
Robot Application Learning Goal: Correlate the vision signals with the touch signals and navigate without collisions. Initially built-in behavior: Retraction reaction whenever an obstacle is touched.
This is a closed-loop system before learning This is a closed-loop system during learning This is an open-loop system The T represents the temporal delay between vision and bump. Closed Loop TS Learning
Antomically this loop still exists but ideally it should never be active again ! This is the system after learning Closed Loop TS Learning
What has the learning done ? Elimination of the late reflex input corresponds mathematically to the condition: X0=0 This was the major condition of convergence for the ISO/ICO rules. (The other one was T=0). What’s interesting about this is that the learning-induced behavior self-generates this condition. This is non-trivial as it assures the synaptic weight AND behavior stabilize at exactly the same moment in time.
This is the system after learning This is the system after learning. The inner pathway has now become a pure feed-forward path What has happened in engineering terms?
Delta pulse Disturbance D Calculations in the Laplace Domain! Formally:
The Learner has learned the inverse transfer function of the world and can compensate the disturbance therefore at the summation node! -e-sT 0 e-sT P1 D Phase Shift
The out path has, through learning, built a Forward Model of the inner path. This is some kind of a “holy grail” for an engineer called: “Model Free Feed-Forward Compensation” For example: If you want to keep the temperature in an outdoors container constant, you can employ a thermostat. You may however also first measure how the sun warms the liquid in the container, relating outside temperature to inside temperature (“Eichkurve”). From this curve you can extract a control signal for the cooling of the liquid and react BEFORE the liquid inside starts warming up. As you react BEFORE, this is called Feed-Forward-Compensation (FFC). As you have used a curve, have performed Model-Based FFC. Our robot learns the model, hence we do Model Free FFC.
Example of ISO instability as compared to ICO stability ! Remember the Auto-Correlation Instability of ISO?? dw1 = m u1 u0’ ICO dt dw1 = m u1 v’ ISO dt
One-shot learning Full compensation Over compensation
Statistical Analysis: Conventional differential hebbian learning One-shot learning (some instances) Highly unstable
Statistical Analysis: Input Correlation Learning One-shot learning (common) Stable in a wide domain
Stable learning possible with about 10-100 fold higher learning rate
Two more applications: RunBot With different convergent conditions! Walking is a very difficult problem as such and requires a good, multi-layered control structure only on top of which learning can take place.
An excursion into Multi-Layered Neural Network Control • Some statements: • Animals are behaving agents. They receive sensor inputs from MANY sensors and they have to control the reaction of MANY muscles. • This is a terrific problem and solved by out brain through many control layers. • Attempts to achieve this with robots have so far been not very successful as network control is somewhat fuzzy and unpredictable.
Adaptive Control during Waliking Three Loops Step control Terrain control Central Control (Brain) Ground- contact Spinal Cord (Oscillations ) Motorneurons & Sensors (Reflex generation) Muscles & Skeleton (Biomechanics) Muscle length
Self-Stabilization by passive Biomechanical Properties (Pendelum) Muscles & Skeleton (Biomechanics)
RunBot’s Network of the lowest loop Motor neurons & Sensors (Reflex generation) Muscles & Skeleton (Biomechanics) Muscle length
Leg Control of RunBot Reflexive Control (cf. Cruse)
Long-Loop Reflex of one of the upper loops Terrain control Central Control (Brain) Before or during a fall: Leaning forward of rump and arms
Long-Loop Reflexe der obersten Schleife Terrain control Central Control (Brain) Forward leaning UBC Backward leaning UBC
Differential Hebbian Learning related to Spike-Timing Dependent Plasticity Learning in RunBot
RunBot: Learning to climb a slope Spektrum der Wissenschaft, Sept. 06
Human walking versus machine walking ASIMO by Honda
RunBot’s Joints Falls Manages Ramp Lower floor Upper floor
X0=0: Weight stabilize together with the behaviour Learning relevant parameters Too late Early enough X
A different Learning Control Circuitry AL, (AR) Stretch receptor for anterior angle of left (right) hip; GL, (GR) Sensor neuron for ground contact of left (right) foot; EI (FI) Extensor (Flexor) reflex inter-neuron, EM (FM) Extensor (Flexor) reflex motor-neuron; ES (FS) Extensor (Flexor) reflex sensor neuron
Motor Neuron Signal Structure (spike rate) Right Leg Left Leg x0 x1 Learning reverses pulse sequence Stability of STDP
Motor Neuron Signal Structure (spike rate) Right Leg Left Leg x0 x1 Learning reverses pulse sequence Stability of STDP
The actual Experiment Note: Here our convergence condition has been T=0 (oscillatory!) and NOT as usual X0=0




















