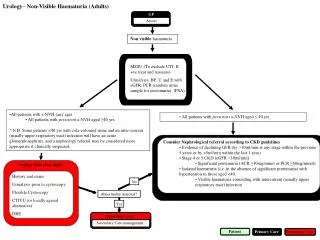
Download

1 / 32
401 likes | 829 Views
Toxmatch - a tool to assess chemical similarity. Nina Jeliazkova - Ideaconsult Ltd., Sofia, Bulgaria Ana Gallegos Saliner, Grace Patlewicz - European Chemicals Bureau, Ispra, Italy Joanna Jaworska - Procter & Gamble, Brussels, Belgium. Introduction.

E N D
Toxmatch - a tool to assess chemical similarity Nina Jeliazkova - Ideaconsult Ltd., Sofia, Bulgaria Ana Gallegos Saliner, Grace Patlewicz - European Chemicals Bureau, Ispra, Italy Joanna Jaworska - Procter & Gamble, Brussels, Belgium
Introduction Chemical similarity is a widely used concept in toxicology, based on the hypothesis that similar compounds have similar biological activities. Toxmatch software • Full-featured and flexible user-friendly open source software, • Encodes several chemical similarity indices in order to facilitate systematic approaches of classifying chemicals into categories. • The core functionalities include • The ability to compare datasets, based on various structural and descriptor-based similarity indices; • Calculate pair wise similarity between compounds and aggregated similarity of a compound to a set; • Several graphical displays that highlight the closeness of chemicals between data sets. Toxmatch has been commissioned by the European Chemicals Bureau (ECB) and will be made available as a free download from its website [http://ecb.jrc.it/qsar/qsar-tools/ ]. SETAC Europe 17th Annual Meeting (20-24 May 2007)
“it is ill defined to say “A is similar to B” and it is only meaningful to say “A is similar to B with respect to C” Similarity : philosophers’ view A chemical “A” cannot be similar to a chemical “B” in absolute terms but only with respect to some measurable key feature SETAC Europe 17th Annual Meeting (20-24 May 2007)
Intuitively, based on expert judgment A chemist would describe “similar” compounds in terms of “approximately similar backbone and almost the same functional groups”. Chemists have different views on similarity (based on experience or context) Lajiness et al. (2004). Assessment of the Consistency of Medicinal Chemists in Reviewing Sets of Compounds, J. Med. Chem., 47(20), 4891-4896. Similarity : chemists’ view SETAC Europe 17th Annual Meeting (20-24 May 2007)
Similarity by computers • Computerized chemical similarity assessment needs unambiguous definitions • Chemicals of interest are encoded numerically (using graphs, descriptors, wave functions, etc) • The measure between the numerical representations is called similarity index. The variety of numerical representations and ways to define a comparative measure have resulted in plethora of approaches to measure similarity between chemical compounds. How to select the proper one? SETAC Europe 17th Annual Meeting (20-24 May 2007)
From similarity to toxicological activity • The aim in assessing chemical similarity in toxicology is to systemically identify chemicals with similar biological activities. • The similarity hypothesis is well substantiated but there are also many contradictory examples, where a small change in chemical structure has led to a dramatic change in the biological response. • This “similarity paradox” suggests that no single and universally applicable similarity measureexists, but the choice depends on the particular endpoint. SETAC Europe 17th Annual Meeting (20-24 May 2007)
Tailored similarity • A “tailored” similarity space is a space comprising specifically selected descriptors or structural patterns. The process within Toxmatch is as follows: • Train similarity measures for specific activities (a training set is required) • Select relevant features by supervised learning methods (e.g. Weka data mining library) • Calculate similarity to the set • Calculate pair wise similarity • Use pair wise similarity values of k most similar chemicals to make a decision on toxicity: • Predict toxicological activity or • Classify into groups of similar toxicity • Group similar chemicals (through unsupervised clustering based on pairwise similarity). These groups will not necessarily coincide with groups of similar toxicity SETAC Europe 17th Annual Meeting (20-24 May 2007)
Tailored similarity in Toxmatch • Select training set ( 4 predefined datasets available) • Encode chemicals into descriptors, fingerprints or atom environments • Perform data preprocessing • Perform feature selection • Calculate similarity • Use similarity values for: • classification into categories • toxicity prediction, read across • clustering • dataset comparison • Visualization, interpretation SETAC Europe 17th Annual Meeting (20-24 May 2007)
Toxmatch main screen SETAC Europe 17th Annual Meeting (20-24 May 2007)
Training sets • Toxmatch comes with following training sets: • Aquatic toxicity • Bioconcentration factor • Skin sensitization • Skin irritation SETAC Europe 17th Annual Meeting (20-24 May 2007)
Structure representation • Descriptors • Imported (e.g. calculated by third party software) • Calculated ( > 100 descriptors available from open source software The Chemistry Development Kit(CDK)http://cdk.sf.net) • Fingerprints • Daylight style hashed fingerprints, 1024 bit length • CDK implementation • Atom environments (circular fingerprints) • Ambit implementation SETAC Europe 17th Annual Meeting (20-24 May 2007)
Data preprocessing and feature selection • Data preprocessing: • Data standardization • Principal Component Analysis (PCA) • Missing values processing • Feature selection • Purpose: select most relevant descriptors or structural patterns (tailored similarity space) • Algorithms: • RelieFF ( finds subset of descriptors that will give best results in prediction or classification) • Infogain (finds descriptors that discriminate best between groups) • Implementation • Toxmatch makes use of open source Waikato Environment for Knowledge Analysis (WEKA) [http://www.cs.waikato.ac.nz/ml/weka/ ] • Developed by the Department of Computer Science, University of Waikato, New Zealand • Machine learning/data mining software written in Java (distributed under the GNU Public License) • Used for research, education, and applications worldwide • Implementation of hundreds of published data mining algorithms (regression, classification, clustering, evaluation and validation) SETAC Europe 17th Annual Meeting (20-24 May 2007)
Similarity indices in Toxmatch • Euclidean distance • Cosine similarity • Hodgkin-Richards index • Tanimoto distance on descriptors • Tanimoto distance on fingerprints • Hellinger distance on atom environments • Maximum Common Structure similarity Descriptors, Euclidean distance Fingerprints, Tanimoto distance Similarity values colour coding: Atom environments, Hellinger distance 1 0 Similarity matrices for structures with Reactive Mode of Action EPA Fathead Minnow dataset (DSSTox) SETAC Europe 17th Annual Meeting (20-24 May 2007)
0 Pairwise similarity - visualization • Similarity matrix • Compare chemicals in: • the training set • subsets of the training set • the test set • subsets of the test set • training set and test set • subsets of training and test set • Click on a matrix cell displays the pair of chemicals and similarity value • Retrieve most similar chemicals to a query one (user selected threshold) Similarity values colour coding: 1 SETAC Europe 17th Annual Meeting (20-24 May 2007)
Similarity values colour coding: 1 0 Pairwise similarity - visualization • Retrieve most similarchemicals to a query one • Load training set • Select similarity measure • Load (draw or enter by IUPAC name or SMILES your query compounds) • Switch to similarity matrix tab • Specify similarity threshold • Press <Show> button to display most similar chemicals • The results can be browsed or exported to a file SETAC Europe 17th Annual Meeting (20-24 May 2007)
Similarity to nearest neighbors, by Fingerprints and Tanimoto distance Example: Most similar compounds to n-hexanal from BCF training set Cyclohexane CAS: 110-82-7 LogBCF=1.84 2-Butanone oximeCAS: 96-29-7 LogBCF=0.58 Isophorone CAS: 78-59-1 LogBCF=0.84 0.46 Tanimoto =0.43 Tanimoto = 0.47 N-hexanal 0.43 0.375 DecalinCAS: 91-17-8 LogBCF=3.25 MethylcyclohexaneCAS: 108-87-2 LogBCF=2.25 0.375 0.375 0.375 Pentadecane CAS: 629-62-9 LogBCF=1.21 Pentadecane CAS: 4390-04-9 LogBCF=1.21 CAS: 544-76-3 LogBCF=1.31 SETAC Europe 17th Annual Meeting (20-24 May 2007)
Pairwise similarity is not everything! Similarity to a set: • Similarity between a query structure and a representative point of the set • dataset centre (descriptor space) • weighted fingerprint • Average similarity between a query structure and the nearest k chemicals; Doesn’t work well for diverse data sets SETAC Europe 17th Annual Meeting (20-24 May 2007)
How to use similarity values Similarity vs Activity plot • Similarity to the set vs. activity • Similarity values per se are not correlated with toxicity values • How to make use of similarity values? SETAC Europe 17th Annual Meeting (20-24 May 2007)
Toxicity prediction by similarity (1) • in Toxmatch is based on weighted average of activity values of the k nearest neighbours. • The actual set of k most similar compounds depends on similarity measure. • The weights are proportional to the pair wise similarities (e.g. the activity value of most similar compound is has largest weight and vice versa). • In order to predict dependent variable (activity), the measured activity values should be available for the training set. • Two values are reported per each compound– averaged similarity to the k nearest neighbours and predicted activity value. SETAC Europe 17th Annual Meeting (20-24 May 2007)
Toxicity prediction by similarity (2) Predicted vs. Observed plot The procedure See also poster Ana Gallegos Saliner et al.THE USE OF A DESCRIPTOR-BASED APPROACH TO PREDICT SKIN IRRITATION USING READILY ACCESSIBLE SOFTWARE TOOLS SETAC Europe 17th Annual Meeting (20-24 May 2007)
Read across Read-across is the process by which endpoint information for one chemical is used to make a prediction of the endpoint for another chemical, which is considered to be similar in some way. Read across can be either qualitative or quantitative though in both cases, a common substructure is required. Toxmatch : Prediction by weighted average of toxicity values of most similar chemicals (nearest neighbours) is essentially performing quantitative read across SETAC Europe 17th Annual Meeting (20-24 May 2007)
Classification into toxicity classes • Toxmatch classifies chemical compounds into groups of toxicological activity, based on similarity values of k nearest neighbours (k most similar compounds) • The query compound is classified into the group where most of the k nearest neighbours belong. • For this purpose activity groups should be available for the training set (e.g. potency classes or other grouping). • The values reported are : • Probability to belong to a group ( m/k , where m is the number of compounds in the group) • The group predicted. SETAC Europe 17th Annual Meeting (20-24 May 2007)
Classification into toxicity classes skin sensitization training set, 5 potency classes Most similar chemicals Query: Moderate – 40% Weak-40% Nonsensitizers – 20% Set of query chemicals SETAC Europe 17th Annual Meeting (20-24 May 2007)
Categories • “Traditional organic chemical categories do not encompass groups of chemicals that are predominately either toxic or nontoxic across a number of toxicological endpoints or even for specific toxic activities” Rosenkranz H.S., Cunningham A.R. (2001) Chemical Categories for Health Hazard Identification: A feasibility Study, Regulatory Toxicology and Pharmacology 33, 313-318. • Conclusion: • use expert knowledge • or machine learning methods to develop categories • Toxmatch provides both options SETAC Europe 17th Annual Meeting (20-24 May 2007)
Classification by expert defined rules • Implementation of structure and physicochemical property rules (BfR) for skin irritation prediction • Available also as a Toxtree plug-in SETAC Europe 17th Annual Meeting (20-24 May 2007)
Training set far from Test set Distance to the test set Test set close to the training set Test set far from the training set Correlating Test and Training set Training set close to Test set Distance to the training set Datasets comparison in Toxmatch Example: Comparison of EINECS database and LLNA skin sensitization dataset in fingerprint similarity space Theory: SETAC Europe 17th Annual Meeting (20-24 May 2007)
Conclusions One approach to comparing the similarity between two or more chemicals is through the use of similarity indices. This relies on the chemicals of interest being encoded numerically (using graphs, descriptors, wave functions, etc) and then using a measure, the similarity index to make the comparison. To facilitate similarity assessment, such indices can be readily encoded into software tools. Toxmatch is a new program that helps to facilitate the systematic assessment of chemical similarity which is a key component in the development and evaluation of grouping approaches such as read-across and chemical categories. SETAC Europe 17th Annual Meeting (20-24 May 2007)
Why Toxmatch • Open source • Toxmatch core relies on actively developed and widely used open source software • Chemoinformatics (The CDK) • Data mining (WEKA) • Scientifically transparent (there are many CDK and WEKA related peer reviewed publications) • Easily extendable • Platform independent SETAC Europe 17th Annual Meeting (20-24 May 2007)
Acknowledgments • ECB contract #CCR.IHCP.C431607.X0 / 22.12.2005“DEVELOPMENT OF A SOFTWARE TOOL TO ENCODE AND APPLY CHEMICAL SIMILARITY INDICES” • Various open source software packages: • The Chemistry Development Kit (cheminformatics) • WEKA data mining library (data mining algorithms) • Ambit (structural similarity and data management) • Toxtree (Verhaar rules for toxicity MOA and implementation of BfR rules for skin irritation prediction) • JFreechart (visualization) • JAMA (matrix operations) • Many more SETAC Europe 17th Annual Meeting (20-24 May 2007)
What do we measure • We compare numerical representations of chemical compounds • The numerical representation is not unique • The numerical representation includes only part of all the information about the compound • A distance measure reflects “closeness” only if the data holds specific assumptions SETAC Europe 17th Annual Meeting (20-24 May 2007)
ReliefF • An instance based method that involves finding nearest neighbours • Supervised (makes use of the class attribute, i.e. makes use of available grouping) • References • Kira, K. and Rendell, L. A. (1992). A practical approach to feature selection. In D. Sleeman and P. Edwards, editors, Proceedings of the International Conference on Machine Learning, pages 249-256. Morgan Kaufmann. • Kononenko, I. (1994). Estimating attributes: analysis and extensions of Relief. In De Raedt, L. and Bergadano, F., editors, Machine Learning: ECML-94, pages 171-182. Springer Verlag. • Marko Robnik Sikonja, Igor Kononenko: An adaptation of Relief for attribute estimation on regression. In D.Fisher (ed.): Machine Learning, Proceedings of 14th International Conference on Machine Learning ICML'97, Nashville, TN, 1997. SETAC Europe 17th Annual Meeting (20-24 May 2007)