Download
1 / 22
220 likes | 237 Views
Categorical data. Decision Tree Classification. Which feature to split on?. Try to classify as many as possible with each split (This is a good split). Which feature to split on?. This is a bad split – no classifications obtained. Improving a good split. Decision Tree Algorithm Framework.

E N D
Which feature to split on? Try to classify as many as possible with each split (This is a good split)
Which feature to split on? This is a bad split – no classifications obtained
Decision Tree Algorithm Framework • If you have positive and negative examples, use a splitting criterion to decide on best attribute to split • Each child is a new decision tree – call the algorithm again with the parent feature removed • If all data points in child node are same class, classify node as that class • If no attributes left, classify by majority rule • If no data points left, no such example seen: classify as majority class from entire dataset
Splitting Criterion • ID3 Algorithm • Some information theory • Blackboard
Issues on training and test sets • Do you know the correct classification for the test set? • If you do, why not include it in the training set to get a better classifier? • If you don’t, how can you measure the performance of your classifier?
Cross Validation • Tenfold cross-validation • Ten iterations • Pull a different tenth of the dataset out each time to act as a test set • Train on the remaining training set • Measure performance on the test set • Leave one out cross-validation • Similar, but leave only one point out each time, then count correct vs. incorrect
Noise and Overfitting • Can we always obtain a decision tree that is consistent with the data? • Do we always want a decision tree that is consistent with the data? • Example: Predict Carleton students who become CEOs • Features: state/country of origin, GPA letter, major, age, high school GPA, junior high GPA, ... • What happens with only a few features? • What happens with many features?
Overfitting • Fitting a classifier “too closely” to the data • finding patterns that aren’t really there • Prevented in decision trees by pruning • When building trees, stop recursion on irrelevant attributes • Do statistical tests at node to determine if should continue or not
Preventing overfitting by cross validation • Another technique to prevent overfitting (is this valid)? • Keep on recursing on decision tree as long as you continue to get improved accuracy on the test set
Review of how to decide on which attribute to split • Dataset has two classes, P and N • Relationship between information and randomness • The more random a dataset is (points in P and N), the more information is provided by the message “Your point is in class P (or N).” • The less random a dataset is, the less information is provided by the message “Your point is in class P (or N).” • Information of message =Randomness of dataset =
Patrons split Randomness = 0.4591 Type split Randomness = 1 Patrons has less randomness, so it is a better split Randomness is often referred to as entropy (similarities with thermodynamics) Which split is better?
Learning Logical Descriptions Hypothesis
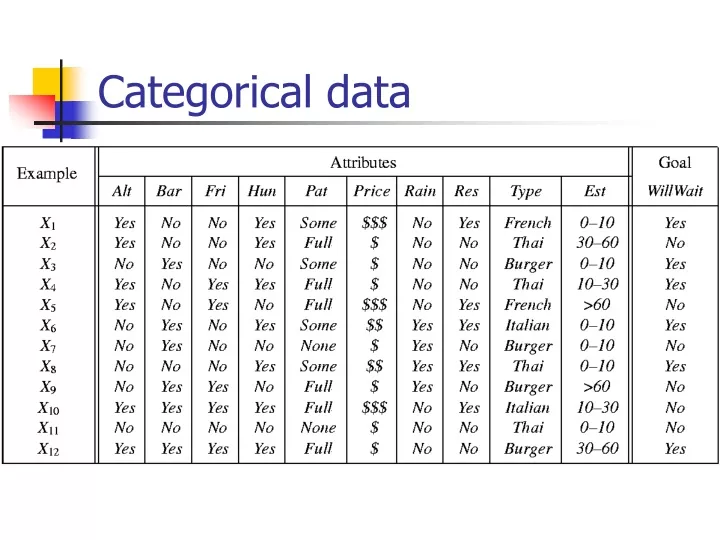
Learning Logical Descriptions • Goal is to learn a logical hypothesis consistent with the data • Example of hypothesis consistent with X1: • Is this consistent with X2? • X2 is a false negative for hypothesis if hypothesis says negative, but should be positive • X2 is a false positive for hypothesis if hypothesis says positive, but should be negative
Current-best-hypothesis search • Start with an initial hypothesis and adjust it as you see examples • Example: based on X1, arbitrarily start with • X2 should be -, but H1 says +. H1 is not restrictive enough, specialize it: • X3 should be +, but H2 says -. H2 is too restrictive, generalize:
Current-best-hypothesis search • X4 should be +, H3 says -. Must generalize: • What if you end up with an inconsistent hypothesis that you cannot modify to make work? • Backup search and try a different route • Tree on blackboard
Neural Networks • Moving on to Chapter 19, neural networks