Download

1 / 28
280 likes | 374 Views
Use of genetic algorithm for designing redundant sensor network. Carine Gerkens Systèmes chimiques et conception de procédés Département de chimie appliquée Université de Liège. Synopsis. Objectives Data validation Algorithm description Optimization Case study Parallelization

E N D
Use of genetic algorithm for designing redundant sensor network Carine Gerkens Systèmes chimiques et conception de procédés Département de chimie appliquée Université de Liège
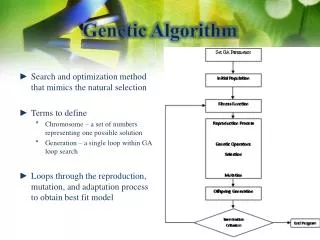
Synopsis • Objectives • Data validation • Algorithm description • Optimization • Case study • Parallelization • Global parallelization • Distributed genetic algorithms • Conclusions
Objectives Using concepts for data reconciliation in chemical processes, create an algorithm able to • Design a sensor network that allows to • Limit the annualised cost of the measurement system for a chemical plant • Evaluate process key variables with a prescribed accuracy • Secure redundancy even in case of one sensor failure • Give the solution for quite large plants within a reasonable time • Problem solved by Bagajewicz (linear mass balances) and Madron (graph oriented method)
Data validation Sensor network design Data validation • All measurements are erroneous • Some important variables(efficiency, conversion…) can not be measured • Thanks to redundancy: correct each measurement as slightly as possible to verify all conservation equations (linear or not, mass and energy balances, link equations) • Estimate non measured variables and their accuracy from reconciled measured variables and accuracies • Hypothesis: Gaussian distribution of measurement errors • Accuracies influenced by the number, the location and the precision of sensors
Q F D P F1 T 1 T2 F2 = f( D P) F3 = Q / Cp (T2-T1) Redundancy • Redundancy is more than repeating the same measurement on the same variable several times (temporal redundancy) • It is also • installing several identical sensors (spacial redundancy) • estimating the same variable thanks to different sensors (stuctural redondancy)
Unconstrained optimization problem (Lagrange) • Optimality Data validation(2) • Constrained optimization problem (linearised eq)
Data validation(3) • Solve the system: • Solution:
Data validation(4) • Validated accuracies
Problem feasability? • For all possible sensors : • M singular? • Target accuracies reached? Sensor network optimization Algorithm description • Belsim-Vali validation model • For all operating points • Validated values of all variables • Jacobian matrices A and B Sensor database - Cost - Accepted range - Uncertainty Belsim-Vali validation model Sensor database • Key variables • Variables • - Required standart deviation Key variables • Optimization criteria • Cost • Target accuracies • Singularity of the validation problem • Safeguard against one sensor failure • Several operating points Problem feasability? • Sensor requirements • existing sensor • - impossible placement Optimization criteria Sensor requirements Sensor network optimization
Genetic algorithm Optimization The problem to optimise is • Large scale • Generally multimodal • Not derivable Developed by John Holland Solution described by a set of binary decisions (genes) corresponding to the decision to install a sensor at a given location
Optimization(2) • Random search algorithm based on reproduction and natural selection mechanisms • Biological systems are robust, efficient and flexible • Artificial systems try to translate nature but less perfomant • Robustness of GA proved empirically • Combine survival of best individuals with information exchange • Exploit parents information to create better children
Optimization(3) • Mecanisms used: • Selection • Reproduction (50%) • One-point-crossover (50%) • Jump mutation (1%)
Optimization(2) • First population chosen randomly with a high probability for each sensor to be chosen • Population of 20 chromosomes • Evaluation of each chromosome’s fitness Sensitivity matrix inversion (Chen et Stadherr) sparse matrix • The best individual is kept at each generation • Stop criterion: best remains unchanged during x generations • Final solution better than initial one (but not necessary the global minimum)
Case study: ammonia loop Ammonia synthesis loop 224 variables 178 constraint equations 117 potential sensors 58 key parameters Optimes.exe
Search history: ammonia loop (2) Case of redundant sensor network • Processor M (dothan) 1.6 GHz • Stop criterion : 200 generations • 100 objective function evaluations per second • Solution obtained after 76 seconds Objective function : 1822.9 Cost : 1850 units 361 generations 7241 objective function evaluations
Solution : case of redundant sensor network 39 sensors : 1 chromatograph, 7 mass flowmeters, 20 temperature sensors, 11 pressure gauges
Solution : case of one sensor failure Computing time : 1h45 67 sensors : 2 chromatograph, 13 mass flowmeters, 31 temperature sensors, 21 pressure gauges
Case study: reformer • 1263 variables • 1116 constraint equations • 473 potential sensors • 9 key parameters • Case of redundant sensor network • Processor Pentium IV • Stop criterion : 200 generations • 9 objective function evaluations per minut • Solution obtained after 6 days
Case study: reformer (2) • Objective function : 1955.1 units • Cost : 1960 units • 1618 generations • 77665 objective function evaluations • Solution: 72 sensors : • 3 chromatographs, • 10 mass flowmeters, • 45 temperature sensors, • 13 pressure gauges, • 1 density sensor
Impossible to deal with larger size problems Parallelisationallows to Parallelisation Why? Large computing time for middle size problems share the computing work between several processors reduce the computing time techniques are compared by efficiency
Slowest operations Shared between processors Fastest operations Carried out by master processor Weak loss of efficiency Best efficiency if Global parallelisation • Use of MPI (Message Passing Interface) • Evaluation of chromosomes’fitness Population evolution, comparison of fitness
Global parallelisation (2) Case of a redundant sensor network:
Distributed Genetic Algorithm Global parallelisation : fall of efficiency with the number of processors DGA : better efficiency? • Chromosomes distributed in sub-populations • Migration operator : chromosomes transfert • Migrating chromosomes chosen randomly • Parameters : Sub-populations’size: 10 chromosomes Number of migrating chromosomes : 2 Number of sub-populations : 5 • Number of generations before migration : 5
Conclusions • The solution found is better than the initial network but there is no guarantee of overall optimum • Accuracies on key parameters are acceptable • Both parallelization techniques allow to reduce the computing time • Distributed genetic algorithm gives better results than global parallelization
Future work • Adaptation to dynamic problems • Create an algorithm of dynamic data validation • Design of networks able to identify process faults
Acknowledgements • Walloon Region • European Social Funds