Download

1 / 43
430 likes | 443 Views
Gradient Methods. April 2004. Preview. Background Steepest Descent Conjugate Gradient. Preview. Background Steepest Descent Conjugate Gradient. Background. Motivation The gradient notion The Wolfe Theorems. Motivation. The min(max) problem:

E N D
Gradient Methods April 2004
Preview • Background • Steepest Descent • Conjugate Gradient
Preview • Background • Steepest Descent • Conjugate Gradient
Background • Motivation • The gradient notion • The Wolfe Theorems
Motivation • The min(max) problem: • But we learned in calculus how to solve that kind of question!
Motivation • Not exactly, • Functions: • High order polynomials: • What about function that don’t have an analytic presentation: “Black Box”
Motivation- “real world” problem • Connectivity shapes (isenburg,gumhold,gotsman) • What do we get only from C without geometry?
Motivation- “real world” problem • First we introduce error functionals and then try to minimize them:
Motivation- “real world” problem • Then we minimize: • High dimension non-linear problem. • The authors use conjugate gradient method which is maybe the most popular optimization technique based on what we’ll see here.
Motivation- “real world” problem • Changing the parameter:
Motivation • General problem: find global min(max) • This lecture will concentrate on finding localminimum.
Background • Motivation • The gradient notion • The Wolfe Theorems
Directional Derivatives: first, the one dimension derivative:
Directional Derivatives : In general direction…
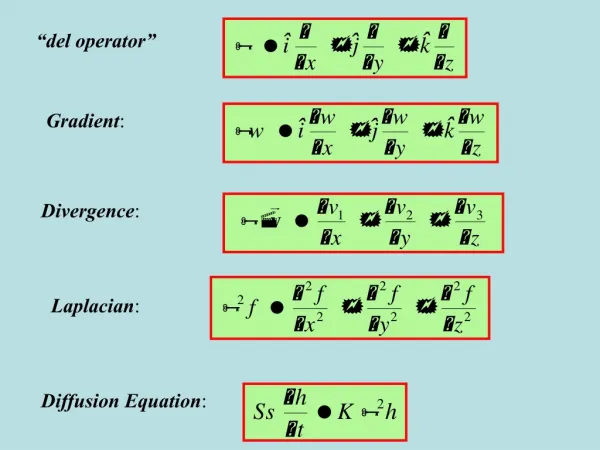
The Gradient: Definition in In the plane
The Gradient Properties • The gradient defines (hyper) plane approximating the function infinitesimally
The Gradient properties • By the chain rule: (important for later use)
The Gradient properties • Proposition 1: is maximal choosing is minimal choosing (intuitive: the gradient point the greatest change direction)
The Gradient properties Proof: (only for minimum case) Assign: by chain rule:
The Gradient properties On the other hand for general v:
The Gradient Properties • Proposition 2: let be a smooth function around P, if f has local minimum (maximum) at p then, (Intuitive: necessary for local min(max))
The Gradient Properties Proof: Intuitive:
The Gradient Properties Formally: for any We get:
The Gradient Properties • We found the best INFINITESIMAL DIRECTIONat each point, • Looking for minimum: “blind man” procedure • How can we derive the way to the minimum using this knowledge?
Background • Motivation • The gradient notion • The Wolfe Theorems
The Wolfe Theorem • This is the link from the previous gradient properties to the constructive algorithm. • The problem:
The Wolfe Theorem • We introduce a model for algorithm: Data: Step 0: set i=0 Step 1: if stop, else, compute search direction Step 2: compute the step-size Step 3: set go to step 1
The Wolfe Theorem The Theorem: suppose C1 smooth, and exist continuous function: And, And, the search vectors constructed by the model algorithm satisfy:
The Wolfe Theorem And Then if is the sequence constructed by the algorithm model, then any accumulation point y of this sequence satisfy:
The Wolfe Theorem The theorem has very intuitive interpretation : Always go in decent direction.
Preview • Background • Steepest Descent • Conjugate Gradient
Steepest Descent • What it mean? • We now use what we have learned to implement the most basic minimization technique. • First we introduce the algorithm, which is a version of the model algorithm. • The problem:
Steepest Descent • Steepest descent algorithm: Data: Step 0: set i=0 Step 1: if stop, else, compute search direction Step 2: compute the step-size Step 3: set go to step 1
Steepest Descent • Theorem: if is a sequence constructed by the SD algorithm, then every accumulation point y of the sequence satisfy: • Proof: from Wolfe theorem Remark: wolfe theorem gives us numerical stability is the derivatives aren’t given (are calculated numerically).
Steepest Descent • From the chain rule: • Therefore the method of steepest descent looks like this:
Steepest Descent • The steepest descent find critical point and local minimum. • Implicit step-size rule • Actually we reduced the problem to finding minimum: • There are extensions that gives the step size rule in discrete sense. (Armijo)
Steepest Descent • Back with our connectivity shapes: the authors solve the 1-dimension problem analytically. • They change the spring energy and get a quartic polynomial in x
Preview • Background • Steepest Descent • Conjugate Gradient