Download

1 / 17
170 likes | 204 Views
Capture, index, and retrieve digital files seamlessly with .CAPTURE software. Automate document processing with features like OCR, barcode reading, PDF conversion, image enhancement, and forms recognition. Customize workflows and effortlessly manage documents in various formats.

E N D
CAPTURE SOFTWARE Please take a few moments to review the following slides. The filing of documents no longer requires manual paper filing or manual indexing of digital files. It can be completely automatic. Put paper into the scanning device…….select the SCAN button……. and moments later the “validated” files are processed and retrievable by an unlimited number of users. Depress the “space bar” or single “mouse click” to advance to the next slide. Thank you for your interest.
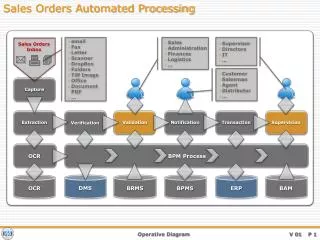
CAPTURE Files can be “captured” by monitoring a Windows folder (s) or from MS Outlook. Any scanning device can be used (standalone or MFP) to scan files to folder (s). The software allows the creation of unlimited, user defined processes known as workflows. Once files are captured, user defined processes may be applied.
WORKFLOW COMPONENTS Capture from Windows folder(s) from Outlook Processes Indexing- define unlimited “indexes” or tags OCR- either zone or full page Convert to PDF Convert PDF to Tif Image Enhancement (straighten, despec, split, etc) Metadata Writer Barcode Reader (1D and 2D) Imprinting Forms Recognition Workflow Loader Auto Orientation Delete Blank Page Publish to Folder (s) to Database to TEXT to Open Source to MS Sharepoint and many other DMS. The following slides will examine some of the components in greater detail……..
INDEXER This component is the engine that drives the CAPTURE solution. A designer can create an unlimited number of “indexes” or tags. Each index can be defined as Text, Integer, Date/Time or Currency. An index can be “mapped” directly to MS Access or any ODBC database for purposes of validation and extraction of related data. Automated workflows can be designed to perform OCR, barcode reading, etc, link that data to an index and perform a lookup into a database (your accounting system) to validate the data and to extract related data. INDEXER
OCR Zone OCR can be used to extract data from scanned images. Multiple zones can be created easily with the design tool. OCR zones can be “mapped” to a database to perform validation. Full page OCR can be used to create SEARCHABLE pdf documents.
BARCODE Barcodes can be used for extracting data from a document, performing database lookups with the extracted data and separating the multi-page document into sub documents automatically.
CONVERT TO PDF Scanned TIF documents may be converted to PDF (searchable or not) with the “indexes” permanently associated with the image. A password may be optionally set for the workflow.
IMAGE ENHANCEMENT TIF images can be auto-straightened, despecked (noise removed), rotated and split by physical number of pages.
FORMS RECOGNITION Forms templates can be created quickly and easily. The templates are stored in RAM and recognized automatically. When a scanned form matches a template, the corresponding workflow is launched automatically and the form is processed automatically.
WORKFLOW LOADER Any variable can be used to launch a workflow automatically (including OCR, Barcode, Forms Recognition, Folder Names, etc)
CONVERT TIF TO PDF This component is used when the scanned (source) document is a PDF. Some processes require a TIF image format. This component will convert from the PDF format to the TIF format automatically.
Delete Blank Page • This component can be used to remove blank pages. It can be very useful when scanning in the duplex mode (both sides) to automatically recognize blank pages and remove them.
AUTO-ORIENTATION This component can be used to automatically orient an image file to a portrait orientation.
SUMMARY OF CAPTURE A designer can use the components shown in the previous slides to create automated (operator unattended) and validated (accurate) workflows. The filing of documents no longer requires manual paper filing or manual indexing of digital files. It is completely automatic. Paper is put into the scanning mechanism….the SCAN button is selected…. and moments later the files are processed and retrievable by an unlimited number of users. The next two slides discuss the comprehensive Publishing and Retrieval options followed by the second category REPOSITORY.
PUBLISHING Many publishing combinations can be used. There is no limit to the number of files published or the number of folders created or the types of databases updated.
RETRIEVAL There are many ways to retrieve files with the software. Each user can select the method that works best for them. That is the benefit of “open architecture”. All methods allow unlimited user retrieval. The methods of retrieval include (but are not limited to): * Windows Explorer navigation. * ODBC database index lookups via client/server or web browser. * Full content (key word) searching via client/server or web browser. * Folder navigation via web browser (Open Source DMS) * Retrieval from third party applications; i.e. Adobe catalog, MS Sharepoint and other DMS. * Integration with “in house” systems (due to open architecture design).
REPOSITORY The Repository is where the files are stored. Due to the open architecture of the software many types of Repositories are supported. For example, you may prefer a client/server environment. Or, you may prefer a web based deployment. Or, you may want both. An analysis of the document types and the associated business processes will help in selecting the environment that works best for you. In addition, a key component in making a Repository decision is the method of retrieval. You may prefer folder navigation. You may want to retrieve files by entering a “key word” (Content Management). Or, you may want to access a database by “indexes” or tags. Or, you may want to use all three retrieval options.