Download

1 / 24
250 likes | 747 Views
Arbres de décision flous. Plan. Les arbres de décision binaire Partitionnement flou de données numériques Construction d’arbres de décision flous Procédure d’inférence pour la classification. Les arbres de décision binaire.

E N D
Plan • Les arbres de décision binaire • Partitionnement flou de données numériques • Construction d’arbres de décision flous • Procédure d’inférence pour la classification
Les arbres de décision binaire • Classifient les données selon une hiérarchie d’attributs ordonnés selon leur pouvoir représentatif. • L’arbre idéal est compact avec un pouvoir de prédiction maximum. • Un arbre de décision binaire possède : • Un ensemble de nœuds organisés hiérarchiquement qui testent chacun la valeur d’un attribut pour effectuer un branchement conséquent. • Un ensemble de feuilles qui sont reliées à différentes classes.
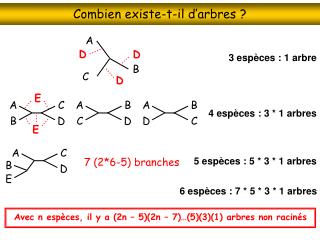
Un arbre de décisionbinairetypique Une même classe peut se retrouver dans des feuilles multiples
Limitations des arbres classiques • Le processus de décision dépend de valeurs seuils • NOM <= 20 -> class 1 NOM > 20 -> class 0 D’où vient 20 ? Pourquoi pas 19.9 ou 20.1 ? • La division des données pour construire l’arbre n’est pas toujours parfaite. • L’arbre est sensible au bruit dans l’ensemble d’apprentissage.
DIT >> 2 DIT >> 2 0.6 0.6 0.4 0.4 CLD >> 0 CLD >> 0 NOM >> 8 NOM >> 8 0.4 0.4 0.6 0.6 0.1 0.1 0.9 0.9 0.4 0.4 0.6 0.6 0.1 0.1 0.4 0.4 0 1 1 0 0 0 1 1 1 1 0 0 Limitations des arbres classiques • Le processus de classification suit le premier chemin valide • Exemple (classe avec DIT=3, CLD=0, NOM=4) TDIFDT TDIDT DIT >> 2 CLD >> 0 NOM >> 8 0.35 0.4
Avantages potentiels d’un arbre flou • Les valeurs linguistiques éliminent le problème des seuils durs • Tous les chemins sont évalués lors du processus de classification • Meilleure robustesse face au bruit • Meilleur pouvoir de généralisation entre l’ensemble d’apprentissage et l’ensemble test • Règles plus facilement interprétables
Apprentissage de classes multiples • On crée un arbre pour chaque paire (Ci, ) (potentiel d’explosion combinatoire!) (A1,C1) (A2,C2) (A3,C3) (A4,C1) (A5,C2) (A6,C1) (A1, C1) (A2, ) (A3, ) (A4, C1) (A5, ) (A6, C1) (A1, ) (A2, C2 ) (A3, ) (A4, ) (A5, C2 ) (A6, ) (A1, ) (A2, ) (A3, C3) (A4, ) (A5, ) (A6, ) Arbre binaire (C1, ) Arbre binaire (C2, ) Arbre binaire (C3, )
Le processus de classification • Déterminer sans ambiguïté la classe d’une donnée (A1, ) Arbre binaire (C1, ) Arbre binaire (C2, ) Arbre binaire (C3, ) (A1,C1)
Partitionnementflou des données • C-centroïdes (version floue des k-centroïdes) • Morphologie mathématique : • Opérations de base : Ouverture: • Fermeture: • Filtre:
Partitionnementflou des données • FPMM algorithm : .
Partitionnementflou des données • Example : Mot d’apprentissage Mot filtré
Création d’un arbre de décision binaire par induction Algorithme C4.5: Si exemples d`apprentissage épuisés: Stop; Sinon: Si tous les exemples d’apprentissage appartiennent à la même classe - Créer un feuille portant le nom de la classe ; Sinon: - Utiliser un test pour trouver le meilleur attribut discriminant dans l`ensemble d’apprentissage ; - Diviser l'ensemble d’apprentissage en deux selon les valeurs de l’attribut identifié ; Fin si ; Fin si • L’entropie est utilisée comme mesure d’information • Comme chaque attribut est commun à toutes les classes, Il faut tenir compte de son pouvoir discriminant pour chacune d’elles
Induction d’un arbre de décisionflou • Similaire à l’algorithm TDIDT de Quinlan • Fonction induire_arbre_flou (Ensemble_d_exemples E, Proprités P) • Sitous éléments dans E sont dans la même classe • alorsretourner une feuille (nœud terminal) étiquetée avec la classe • sinon • siP est vide • alorsretourner une feuille étiquetée avec la disjonction de toutes les classes de E • sinon • flouïfier E; • sélectionner une propriété pr de P comme racine de l’arbre courant; • for chaque partition floue f depr, • créer une branche correspondante dans l’arbre étiquetée f ; • trouver la partition pa des éléments de E qui ont f comme valeur ; • appeler induire_arbre_flou(pa, P) • attacher le nœud résultat à la branche f • fin pour
Entropie 101 • L’information véhiculée par un attribut définit son pouvoir discriminatoire • L’entropie représente “l’information moyenne” de l’attribut • pour un attribut A pris dans un ensemble, l’information véhiculée par la valeur v augmente avec sa rareté : infA(v) =1/p(v) p(v) : probabilité de v • p(v)=0 => infA(v)= ; p(v)=1 => infA(v)=1 • On peut faire varier la formule entre 0 et au lieu de 1 et en prenant le logarithme inflog_A(v)=log[1/p(v)]=-log[p(v)] • L’entropie est l’information moyenne (au sens des probabilités) véhiculée par l’ensemble des valeurs de a H(A)=-v p(v)log[p(v)]
Entropie 101 • Dans l’approche floue, v représente des valeurs linguistiques et l’entropie est l’information moyenne véhiculée par ces valeurs • La probabilité d’un valeur de v doit inclure toutes les valeurs numériques qui peuvent la représenter oú v(ai) représente le degré d’appartenance de ai à vand p(ai) est sa fréquence relative dans le domaine de v
Sélection de l’attribut ayant le meilleur pouvoir de représentation pour une classe • Dans TDIDT, on utilise l’entropie classique. • Pour A={ai }i=1,…,n : où p() est la probabilité que A= • Dans la version floue, on utilise l’entropie floue, ou entropie-étoile : où est une variable linguistique et P*( )est la probabilité floue que A= : • : fonction d’appartenance d’une valeur ai à • P(ai) : fréquence de ai dans l’ensemble d’apprentissage
Sélection de l’attribut ayant le meilleur pouvoir de représentation pour toutes les classes • Chaque attribut étant commun à toutes les classes, Il faut tenir compte de son pouvoir discriminant dans chacune d’elles => entropie conditionnelle : • Choisir Ajayant min. comme critère de division 19
Procédure d’inférence possible pour la classification • Pour chaque arbre : • Les données entrent par la racine de chaque arbre et sont propagées vers les feuilles . • Utiliser l’algorithme max-min* pour : • Déterminer les valeurs d’appartenance de chacune des feuilles au label associé (min) • En déduire la valeur floue de chaque label (max). • Partant de tous les arbres, utiliser la méthode du vote majoritaire pour identifier la classe d’appartenance des données *Max-min : min() le long de chaque chemin, max() pour chaque label de sortie
NOM 1 NOM 9 15 DAM 0.65 0.35 1 NOP DAM 0.78 0.55 0.7 0.3 0.8 0.2 0 1 1 0 0.3 0.2 0.65 0.35 Exemple • Données : (NOM=11, NOP=11, DAM=0.6) « petit » « grand » NOP 1 5 12 • L’utilisation de max- min donne : • (1) = 0.65 ; (2) = 0.3
Ex. Tree 1 Tree 2 Tree 3 Vote C1 C2 C3 C1 C2 C3 E1 1 0 0 0.3 0 0.8 0.78 0.2 0.08 E2 0.55 0.6 0.3 0.7 0.32 0.48 0.57 0.42 0.48 E3 0.1 0 0.8 0.1 0 0.6 0.22 0.55 0.02 Exemple - suite • Méthode du vote : • On prend la classe qui obtient le plus grand . • Ex : pour E1,
NOP Cas 1 1 9 15 NOP 1 Cas 2 5 12 Et si on changeait de fonctionsd’appartenance ? • Utiliser un outil d’analyse (simulateur) • Passer à la logique floue de niveau II !
Références [1]. Marsala C. , and Bouchon-Meunier B. , “Fuzzy partitioning using mathematical morphology in a learning scheme,” actes de 5th IEEE Conference on Fuzzy Systems, New Orleans, 1996. [2]. Marsala C. , Apprentissage inductif en présence de données imprécises : construction et utilisation d’arbres de décision flous, thèse de doctorat, Universite Pierre et Marie Curie, Paris (France), 1998. Rapport LIP6 No. 1998/014. [3]. Boukadoum, M., Sahraoui, H. & Lounis, H. “Machine Learning Approach to Predict Software Evolvability with Fuzzy Binary Trees” actes de ICAI 2001, Las Vegas, juin 2001. [4]. Sahraoui, H., Boukadoum, M., Chawiche, H. M., Mai, G. & Serhani, M. A. “A fuzzy logic framework to improve the performance and interpretation of rule-based quality prediction models for object-oriented software,” actes de COMPSAC 2002, Oxford (Angleterre), août 2002. [5] Boukadoum, M., Sahraoui, H. and Chawiche H. M. “Refactoring object-oriented software using fuzzy rule-based prediction,” actes de MCSEAI 2004, Sousse (Tunisie), mai 2004.